Java也能做爬虫了?我爬取并下载了酷狗TOP500的歌曲!
点击“ 开发者技术前线 ”,选择“星标:top:”
在看|星标|留言, 真爱

作者:后山悟道人 链接 : my.oschina.net/gllfeixiang/blog/2995570
下文方法及代码仅供学习使用,不做他用。示例用到了一些库,包括:jsoup、HttpClient、net.sf.json大家可以自行去下载jar包。
1.分析是否能获得TOP500歌单
首先,打开酷狗首页查看酷狗TOP500,说好的500首,怎么就只有22首呢?

是真的只让看这些还是能找到其余的呢,于是我就看了下这TOP500的链接
https://www.kugou.com/yy/rank/home/1-8888.html?from=rank
可以看的出home后边有个1,难道这是代表第一页的意思?于是我就把1改成2,进入,果然进入了第二页, 至此可以知道我们可以在网页里获取这500首的歌单。
2.分析找到真正的mp3下载地址(这个有点绕)
点一个歌曲进入播放页面,使用谷歌浏览器的控制台的Elements,搜一下mp3,很轻松就定位到了MP3的位置
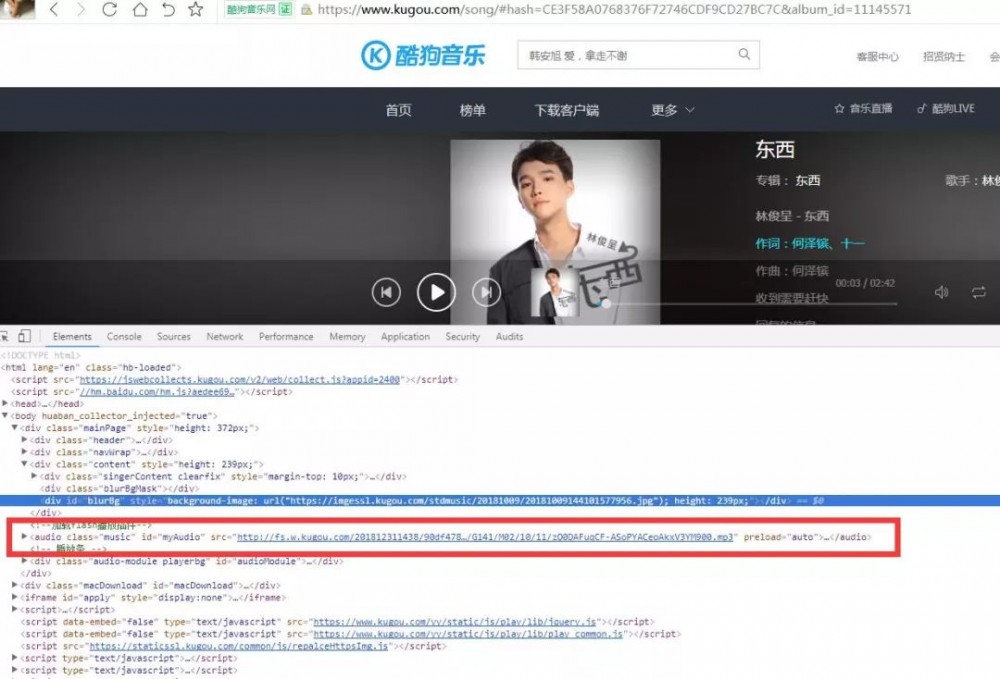
但是使用java访问的时候爬取的html里却没有该mp3的文件地址,那么这肯定是在该页面的位置使用了js来加载mp3,那么刷新下网页,看网页加载了哪些东西,加载的东西有点多,着重看一下js、php的请求,主要是看里面有没有mp3的地址,分析细节就不用说了
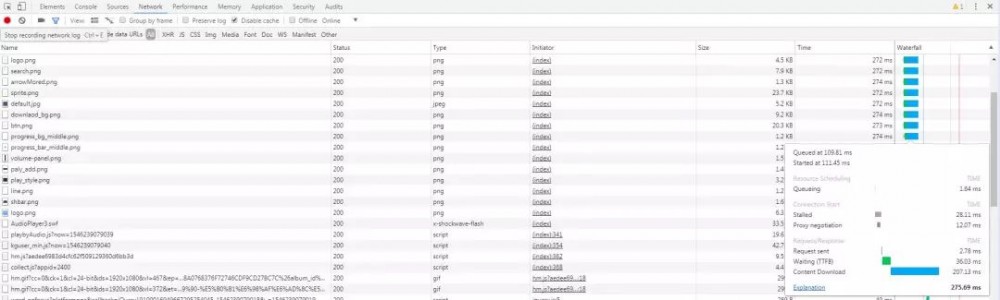
最终我在列表的
https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery191027067069941080546_1546235744250&hash=667939C6E784265D541DEEE65AE4F2F8&album_id=0&_=1546235744251
这个请求里发现了mp3的完整地址,
"play_url": "http:////fs.w.kugou.com//201812311325//dcf5b6449160903c6ee48035e11434bb//G128//M08//02//09//IIcBAFrZqf2ANOadADn94ubOmaU995.mp3",
那这个js是怎么判断是哪首歌的呢,那么只可能是hash这个参数来决定歌曲的,然后到播放页面里找到这个hash的位置,是在下面的js里
var dataFromSmarty = [{"hash":"667939C6E784265D541DEEE65AE4F2F8","timelength":"237051","audio_name":"/u767d/u5c0f/u767d - /u6700/u7f8e/u5a5a/u793c","author_name":"/u767d/u5c0f/u767d","song_name":"/u6700/u7f8e/u5a5a/u793c","album_id":0}],//当前页面歌曲信息
playType = "search_single";//当前播放
</script>
在去java爬取该网页,查看能否爬到这个hash,果然,爬取的html里有这段js,到现在mp3的地址也找到了,歌单也找到了,那么下一步就用程序实现就可以了。
3.java实现爬取酷狗mp3
先看一下爬取结果
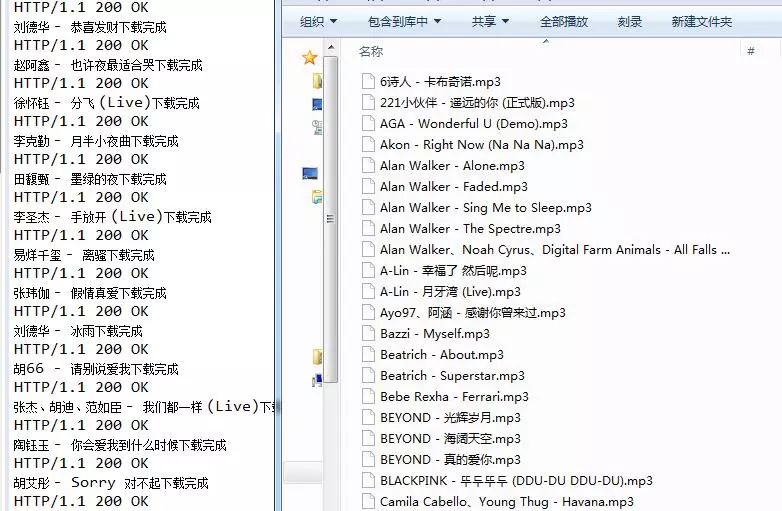
找到了资源,程序实现就好说了,其中使用到了自己写的几个工具类,自己整理点自己的工具类还是有好处的,以后遇到什么问题就没必要重新写了,直接拿来用就可以了。没什么好说的了,下面直接贴出源码
SpiderKugou.java
package com.bing.spider;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.bing.download.FileDownload;
import com.bing.html.HtmlManage;
import com.bing.http.HttpGetConnect;
import net.sf.json.JSONObject;
public class SpiderKugou {
public static String filePath = "F:/music/";
public static String mp3 = "https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery191027067069941080546_1546235744250&"
+ "hash=HASH&album_id=0&_=TIME";
public static String LINK = "https://www.kugou.com/yy/rank/home/PAGE-8888.html?from=rank";
//"https://www.kugou.com/yy/rank/home/PAGE-23784.html?from=rank";
public static void main(String[] args) throws IOException {
for(int i = 1 ; i < 23 ; i++){
String url = LINK.replace("PAGE", i + "");
getTitle(url);
//download("https://www.kugou.com/song/mfy6je5.html");
}
}
public static String getTitle(String url) throws IOException{
HttpGetConnect connect = new HttpGetConnect();
String content = connect.connect(url, "utf-8");
HtmlManage html = new HtmlManage();
Document doc = html.manage(content);
Element ele = doc.getElementsByClass("pc_temp_songlist").get(0);
Elements eles = ele.getElementsByTag("li");
for(int i = 0 ; i < eles.size() ; i++){
Element item = eles.get(i);
String title = item.attr("title").trim();
String link = item.getElementsByTag("a").first().attr("href");
download(link,title);
}
return null;
}
public static String download(String url,String name) throws IOException{
String hash = "";
HttpGetConnect connect = new HttpGetConnect();
String content = connect.connect(url, "utf-8");
HtmlManage html = new HtmlManage();
String regEx = "/"hash/":/"[0-9A-Z]+/"";
// 编译正则表达式
Pattern pattern = Pattern.compile(regEx);
Matcher matcher = pattern.matcher(content);
if (matcher.find()) {
hash = matcher.group();
hash = hash.replace("/"hash/":/"", "");
hash = hash.replace("/"", "");
}
String item = mp3.replace("HASH", hash);
item = item.replace("TIME", System.currentTimeMillis() + "");
System.out.println(item);
String mp = connect.connect(item, "utf-8");
mp = mp.substring(mp.indexOf("(") + 1, mp.length() - 3);
JSONObject json = JSONObject.fromObject(mp);
String playUrl = json.getJSONObject("data").getString("play_url");
System.out.print(playUrl + " == ");
FileDownload down = new FileDownload();
down.download(playUrl, filePath + name + ".mp3");
System.out.println(name + "下载完成");
return playUrl;
}
}
HttpGetConnect.java
package com.bing.http;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.security.NoSuchAlgorithmException;
import java.security.cert.CertificateException;
import java.security.cert.X509Certificate;
import javax.net.ssl.SSLContext;
import javax.net.ssl.TrustManager;
import javax.net.ssl.X509TrustManager;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.conn.ClientConnectionManager;
import org.apache.http.conn.scheme.Scheme;
import org.apache.http.conn.scheme.SchemeRegistry;
import org.apache.http.conn.ssl.SSLSocketFactory;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.BasicHttpClientConnectionManager;
import org.apache.http.params.HttpParams;
/**
* @说明:
* @author: gaoll
* @CreateTime:2014-11-13
* @ModifyTime:2014-11-13
*/
public class HttpGetConnect {
/**
* 获取html内容
* @param url
* @param charsetName UTF-8、GB2312
* @return
* @throws IOException
*/
public static String connect(String url,String charsetName) throws IOException{
BasicHttpClientConnectionManager connManager = new BasicHttpClientConnectionManager();
CloseableHttpClient httpclient = HttpClients.custom()
.setConnectionManager(connManager)
.build();
String content = "";
try{
HttpGet httpget = new HttpGet(url);
RequestConfig requestConfig = RequestConfig.custom()
.setSocketTimeout(5000)
.setConnectTimeout(50000)
.setConnectionRequestTimeout(50000)
.build();
httpget.setConfig(requestConfig);
httpget.setHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
httpget.setHeader("Accept-Encoding", "gzip,deflate,sdch");
httpget.setHeader("Accept-Language", "zh-CN,zh;q=0.8");
httpget.setHeader("Connection", "keep-alive");
httpget.setHeader("Upgrade-Insecure-Requests", "1");
httpget.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36");
//httpget.setHeader("Hosts", "www.oschina.net");
httpget.setHeader("cache-control", "max-age=0");
CloseableHttpResponse response = httpclient.execute(httpget);
int status = response.getStatusLine().getStatusCode();
if (status >= 200 && status < 300) {
HttpEntity entity = response.getEntity();
InputStream instream = entity.getContent();
BufferedReader br = new BufferedReader(new InputStreamReader(instream,charsetName));
StringBuffer sbf = new StringBuffer();
String line = null;
while ((line = br.readLine()) != null){
sbf.append(line + "/n");
}
br.close();
content = sbf.toString();
} else {
content = "";
}
}catch(Exception e){
e.printStackTrace();
}finally{
httpclient.close();
}
//log.info("content is " + content);
return content;
}
private static Log log = LogFactory.getLog(HttpGetConnect.class);
}
HtmlManage.java
package com.bing.html;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.bing.http.HttpGetConnect;
/**
* @说明:
* @author: gaoll
* @CreateTime:2014-11-13
* @ModifyTime:2014-11-13
*/
public class HtmlManage {
public Document manage(String html){
Document doc = Jsoup.parse(html);
return doc;
}
public Document manageDirect(String url) throws IOException{
Document doc = Jsoup.connect( url ).get();
return doc;
}
public List<String> manageHtmlTag(Document doc,String tag ){
List<String> list = new ArrayList<String>();
Elements elements = doc.getElementsByTag(tag);
for(int i = 0; i < elements.size() ; i++){
String str = elements.get(i).html();
list.add(str);
}
return list;
}
public List<String> manageHtmlClass(Document doc,String clas ){
List<String> list = new ArrayList<String>();
Elements elements = doc.getElementsByClass(clas);
for(int i = 0; i < elements.size() ; i++){
String str = elements.get(i).html();
list.add(str);
}
return list;
}
public List<String> manageHtmlKey(Document doc,String key,String value ){
List<String> list = new ArrayList<String>();
Elements elements = doc.getElementsByAttributeValue(key, value);
for(int i = 0; i < elements.size() ; i++){
String str = elements.get(i).html();
list.add(str);
}
return list;
}
private static Log log = LogFactory.getLog(HtmlManage.class);
}
FileDownload.java
package com.bing.download;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
/**
* @说明:
* @author: gaoll
* @CreateTime:2014-11-20
* @ModifyTime:2014-11-20
*/
public class FileDownload {
/**
* 文件下载
* @param url 链接地址
* @param path 要保存的路径及文件名
* @return
*/
public static boolean download(String url,String path){
boolean flag = false;
CloseableHttpClient httpclient = HttpClients.createDefault();
RequestConfig requestConfig = RequestConfig.custom().setSocketTimeout(2000)
.setConnectTimeout(2000).build();
HttpGet get = new HttpGet(url);
get.setConfig(requestConfig);
BufferedInputStream in = null;
BufferedOutputStream out = null;
try{
for(int i=0;i<3;i++){
CloseableHttpResponse result = httpclient.execute(get);
System.out.println(result.getStatusLine());
if(result.getStatusLine().getStatusCode() == 200){
in = new BufferedInputStream(result.getEntity().getContent());
File file = new File(path);
out = new BufferedOutputStream(new FileOutputStream(file));
byte[] buffer = new byte[1024];
int len = -1;
while((len = in.read(buffer,0,1024)) > -1){
out.write(buffer,0,len);
}
flag = true;
break;
}else if(result.getStatusLine().getStatusCode() == 500){
continue ;
}
}
}catch(Exception e){
e.printStackTrace();
flag = false;
}finally{
get.releaseConnection();
try{
if(in != null){
in.close();
}
if(out != null){
out.close();
}
}catch(Exception e){
e.printStackTrace();
flag = false;
}
}
return flag;
}
private static Log log = LogFactory.getLog(FileDownload.class);
}
到这就结束了,有可能有些代码没贴全,主要代码已经差不多,应该可以跑起来,多多指教。
正文到此结束
- 本文标签: App Agent value zip client ip IDE cache Document 参数 ssl find Word CTO ArrayList key java build node 开发者 Security parse Chrome PHP http Apple Keep-Alive XML 正则表达式 Connection windows UI Logging jsoup tag 谷歌 web js entity 代码 id json final 源码 jquery 下载 HTML stream list apache src https API IO Select 开发 编译 cat ACE
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

