JVM-G1算法和数据结构那些事
人的情况和树相同。它愈想开向高处和明亮处,它的根愈要向下,向泥土,向黑暗处,向深处,向恶——千万不要忘记。我们飞翔得越高,我们在那些不能飞翔的人眼中的形象越是渺小。
—— 尼采《查拉图斯特拉如是说》
往往,最基础最底层的知识里,蕴含着原始而强大的力量。 本文将以 java8 SE HotSpot VM为依据 ,盘点G1里的算法和数据结构。

图1
本文将讲述:
① 三色标记法: 解释了为什么并发类回收器需要重新标记和stw的过程;
② card table & remember set: 解释了G1为什么可以在GC时不用扫描整个年老代从而对大堆更友好;
③ satb: 解释了G1如何处理并发标记过程中的新增对象和引用变更以及浮动垃圾从何而来;
④ collection sets: 简要说明为什么G1可以实现回收时间大致可控。
三色标记法
并发类回收器的并发标记阶段,gc线程和应用线程是并发执行的。 所以一个对象被标记之后,应用线程可能篡改对象的引用关系,从而造成对象的漏标、误标。
其实误标没什么关系,顶多造成浮动垃圾,在下次gc还是可以回收的。但是 漏标 的后果是致命的,把本应该存活的对象给回收了,从而影响的程序的正确性。
为了解决在并发标记过程中, 存活对象漏标 的情况,GC HandBook把对象分成 三种颜色 :
① 黑色 :根对象,或者该对象与它的子对象都被扫描
② 灰色 :对象本身被扫描,但还没扫描完该对象中的子对象
③ 白色 :未被扫描对象,扫描完成所有对象之后,最终为白色的为不可达对象,即垃圾对象。
当GC开始扫描对象时,按照如下图步骤进行对象的扫描:
根对象被置为黑色,子对象被置为灰色;
继续由灰色遍历,将已扫描了子对象的对象置为黑色;
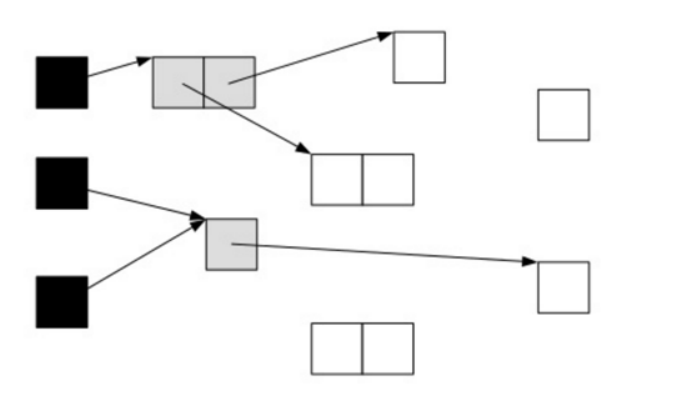
图2
遍历了所有可达的对象后,所有可达的对象都变成了黑色;不可达的对象即为白色,需要被清理。
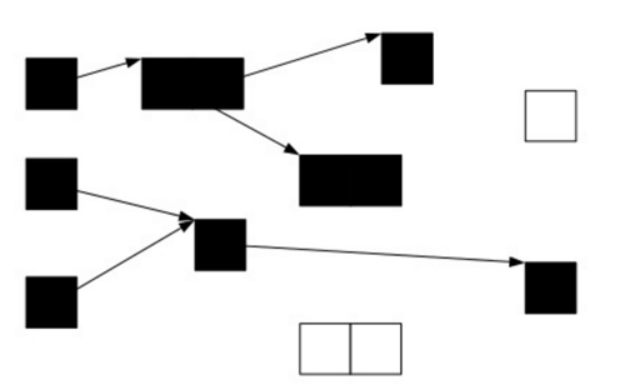
图3
这看起来似乎很美好,然而--如果在标记过程中,应用程序也在运行,那么对象的指针就有可能改变。这样的话,我们就会遇到一个问题: 对象丢失问题
我们看下面一种情况,当垃圾收集器扫描到下面情况时:
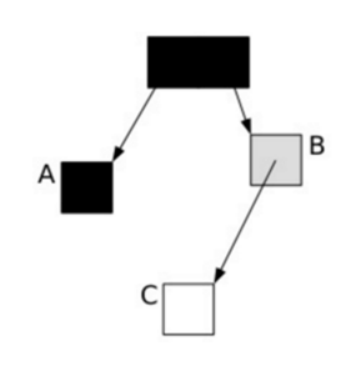
图4
这时候应用程序执行了以下操作:
A.c=C
B.c=null
这样 , 对象的状态图 变成如下情形:
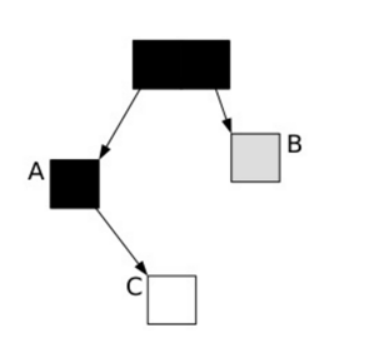
图5
很显然,此时C是白色,被认为是垃圾需要清理掉,显然这是不合理的。
一个已经被灰对象指向白对象,在并发标记阶段会被漏标的 充分必要条件 是:
①Mutator 插入了一个 黑对象 到 该白对象的引用;
②Mutator 删除了所有 灰对象 到 该白对象的引用。
上面两个充要条件,只要打破一个就不会被漏标。就有如下两种可行的方式解决漏标:
①在插入的时候记录对象;
②在删除的时候记录对象。
刚好这对应CMS和G1的2种不同实现方式——
一. CMS 采用的是增量更新 (Incremental update)(post-write barrier) ,致力于第一个条件的打破,只要在写屏障 (write barrier) 里发现要有一个白对象的引用被赋值到一个黑对象 的字段里,那就把这个白对象变成灰色的,即插入的时候记录下来。哪怕删除所有灰对象到该白对象的引用,remark 阶段重新回顾一次就不会漏标了
二. G1 中,使用的是STAB (snapshot-at-the-beginning)(pre-write barrier) 的方式,致力于第二个条件的打破。采用最保守的做法,把变更前的引用对象记录下来,当作是存活对象,让其活过这一周期。
[NextTAMS,top]指针之间的对象是并发标记期间新增对象,也在这一个周期里隐式存活。
因此 G1 的 SATB 会产生更多的浮动垃圾。但是换来的好处就是:不需要像 CMS 那样 remark,再走一遍 root trace 这种相当耗时的流程。
它有三个步骤:
在开始标记的时候生成一个快照图标记存活对象
在并发标记的时候所有被改变的对象入队
(在write barrier里把所有旧的引用所指向的对象都变成非白的)
并发标记期间新增对象记录在ntams和top指针之间,将在下次被收集
产生浮动垃圾
这样,G1到现在可以知道哪些老的分区可回收垃圾最多。当全局并发标记完成后,就开始Mix GC。
Card Table&Remembered Set
年老代在堆中的比例远大于年轻代,年轻代比较小即使全堆扫描也成本不高,但如果每次YGC或Mixed GC都要扫描一次年老代全堆的话,肯定会非常耗时,那么有什么好的解决方案呢?
JVM G1回收器使用了card table和remember set两个结构处理年老代全堆扫描的问题。
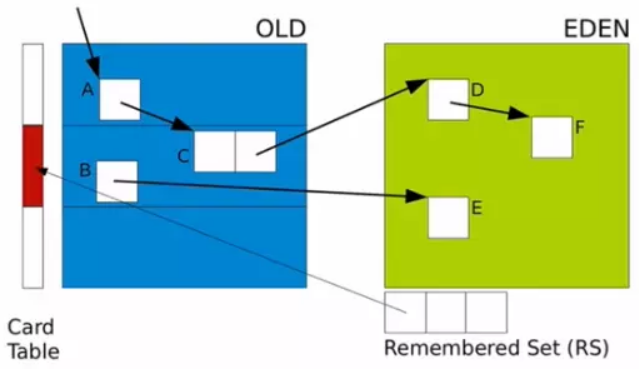
图5
Card Table
基于卡表 (Card Table ) 的设计,通常将堆空间划分为一系列2次幂大小的卡页 ( Card Page) ,HotSpot JVM的卡页大小为512字节。
卡表维护着所有的Card Page 。Card Table的结构是一个字节数组,每个卡表项映射着一个Card Page,为1个字节,用于标记卡页的状态。
Card Page中对象的引用发生改变时,写屏障逻辑将会把Card Page在Card Table数组中对应的值标记为dirty,就称这个Card Page被 脏化 了。
所以Card Table其实就是映射着内存中的对象,在进行Young GC的时候,便可以不用扫描整个老年代。
而是在卡表中寻找脏卡,并将脏卡中的对象加入到Minor GC的GC Roots里。当完成所有脏卡的扫描之后,所有脏卡的标识位清零。
对于一些热点Card Page会存放到Hot Card Cache中。同Card Table一样,Hot Card Cache也是全局的结构。
OpenJDK/Oracle 1.6/1.7/1.8 JVM默认的卡标记简化逻辑如下:
CARD_TABLE [this address >> 9] = 0;
首先:计算对象引用所在卡页的卡表索引号。将卡页地址右移9位,相当于用地址除以512 (2的9次方) 。 可以这么理解:假设卡表卡页的起始地址为0,那么卡表项0、1、2对应的卡页起始地址分别为0、512、1024 (卡表项索引号乘以卡页512字节) 。
其次:通过卡表索引号,设置对应卡标识为dirty。
Card table随着堆内存一起初始化,全局唯一,通过具体的垃圾收集策略进行创建。


Remembered Set
每一个Region都有自己的RSet 。
虚拟机发现程序在对Reference类型的数据进行写操作时,会产生一个Write Barrier暂时中断写操作,检查Reference引用的对象是否处于不同的Region之中。 如果是,便通过Card Table把相关引用信息记录到被引用对象所属的Region的Remembered Set之中。
维系RSet中的引用关系靠post-write barrier&Concurrent refinement threads来维护,操作伪代码如下:
void oop_field_store(oop* field, oop new_value) {
// pre-write barrier: for maintaining SATB invariant
// the actual store
pre_write_barrier(field);
*field = new_value;
// post-write barrier: for tracking cross-region reference
post_write_barrier(field, new_value);
}
RSet里面记录了引用-- 就是其他Region中指向本Region中所有对象的所有引用,也就是谁引用了我的对象。
RSet其实是一个Hash Table,Key是其他的Region的起始地址,Value是一个集合,里面的元素是Card Table 数组中的index,既Card对应的Index,映射到对象的Card地址。
比如A对象在regionA,B对象在regionB,且B.f = A,则在regionA的RSet中需要记录一对键值对,key是regionB的起始地址,Value的值能映射到B所在的Card的地址,所以要查找B对象,就可以通过RSet中记录的卡片来查找该对象。
本分区对象引用本分区自己的对象,这种引用不用落入RSet中;同时,G1 GC每次都会对年轻代进行整体收集。
因此young->old和young->young也不需要在RSet中记录。而对于old->young和old->old的跨代对象引用,需要拥有RSet。
对于G1进行YGC时的跨代引用,以及进行Mixed GC时的old 间跨region引用,只要到本Region RSet所记录的region中扫描引用了脏card区域的对象,再如法溯源,判断其是否存活存活,进而确定本分区内的对象存活情况。而不需要扫描整个堆了。
为了防止RSet溢出,对于一些比较热点的RSet会通过存储粒度级别来控制。
RSet有三种粒度—Sparse (稀疏) &Fin e (细) &Coarse (粗)
对于热点RSet在存储时,根据细粒度的存储阀值,可能会采取粗粒度。这三种粒度的RSet都是通过Per Region Table来维护内部数据的。一个Per-Region-Table (PRT) 是 RSet存储颗粒度级别一个抽象。
Sparse PRT是一个包含Card目录的Hash Table :G1收集器内部维护这些Card。Card包含来自Region的引用,这个Region的引用是Card到Owning Region的关联的地址。
Fine-Grain PRT是一个开放的Hash Table :每一个Entry代表一个指向Owning Region的引用的Region,Region里面的Card目录,是一个Bitmap。
当达到Fine-Grain PRT的最大容量,Coarse Grain Bitmap里面的相应的Coarse-Grained bit被设置,相应地Entry从Fine-Grain PRT删除。
Coarse bitmap有一个每个Region对应的bit。Coarse Grain map设置bit意味着关联的Region包含到Owning Region的引用。
SATB
SATB (S napshot-At-The-Begin) 之所以叫这个名字,就是在初始标记开始时,G1 收集器打了一个快照,形成一个所谓的 对象图 (Object Graph) 。
这个对象图记录在 next marking bitmap 之中 ,在并发标记阶段会在这个 bitmap 中 记录对象存活标记。最终Remark阶段结束后,完成对快照对象图所有标记。
图中可以很明确看到两个bitmap数据结构—— G1 是借助 bitmap 来存放 对象存活标记 。 每一个 bit 表示每个region中的某个对象起始地址,如果 bit 标记为 1 ( 黑色) ,则表示该对象存活,bit 与对象 对应有一套算法:
⁃ Bottom 指向 Region起点位置;
⁃ Top 永远指向当前Region 最新分配的对象,记录其起始位置;
⁃ PrevTAMS 和 NextTAMS 分别标记前后两次并发标记周期开始时 , Top 指针的位置 (TAMS - top at mark start) ;
⁃ End 表示 Region 终点位置。
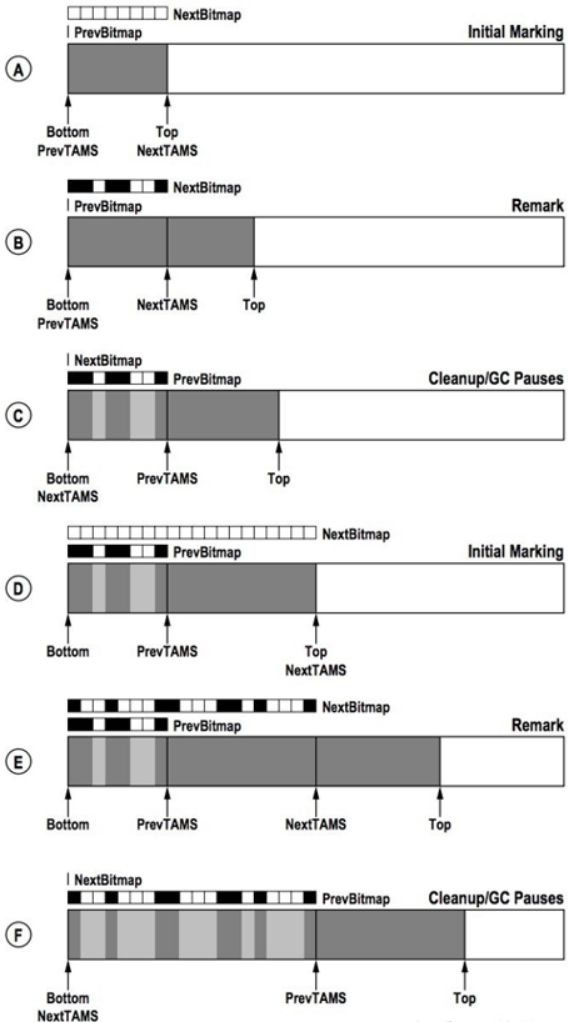
图6
[Bottom,PrevTAMS)-> 这部分的存活信息会在previous marking bitmap体现;
[Bottom, NextTAMS)-> 当清理时,PrevTAMS指向NextTAMS地址,NextTAMS归零,所有垃圾对象能通过[ Bottom, previousTAMS ]之间的对象快照被识别出来;
[NextTAMS, Top)-> 这部分对象在第 n 轮全局标记周期是隐式存活,SATB能够确保这部分的对象都会被标记,保障并发标记期间新增的对象不会被清理;
SATB利用pre-write barrier,将所有即将被修改引用关系的白对象旧引用记录下来,最后以这些旧引用为根重新扫描一遍,以解决白对象引用被修改产生的漏标问题。在引用关系被修改之前,插入一层pre-write barrier,代码如下:
pre-write barrier最终执行逻辑:
//openjdk/hotspot/src/share/vm/gc_implementation/g1/g1SATBCardTableModRefBS.cpp lines 52 ~ 65
void G1SATBCardTableModRefBS::enqueue(oop pre_val) {
// Nulls should have been already filtered.
assert(pre_val->is_oop(true), "Error");
if (!JavaThread::satb_mark_queue_set().is_active()) return;
Thread* thr = Thread::current();
if (thr->is_Java_thread()) {
JavaThread* jt = (JavaThread*)thr;
jt->satb_mark_queue().enqueue(pre_val);
} else {
MutexLocker x(Shared_SATB_Q_lock);
JavaThread::satb_mark_queue_set().shared_satb_queue()->enqueue(pre_val);
}
}
通过
G1SATBCardTableModRefBS::enqueue(oop pre_val)
把原引用保存到satb_mark_queue中,和RSet的实现类似,每个应用线程都自带一个satb_mark_queue。在下一次的并发标记阶段,会依次处理satb_mark_queue中的对象,确保这部分对象在本轮GC是存活的。
然而,SATB也是有副作用的。 如果被修改引用的白对象就是要被收集的垃圾,这次的标记会让它躲过GC,这就是float garbage。因为SATB的做法精度比较低,所以造成的float garbage也会比较多。
Collection Sets
Collect Set (CSet) 是指 :在Evacuation阶段,由G1垃圾回收器选择的待回收的Region集合。G1垃圾回收器的软实时的特性就是通过CSet的选择来实现的。
对于年轻代收集:CSet只容纳Eden Regions、Survivor Region;
对于混合收集:CSet还会容纳1/8的老年代Region。
G1将调整young的Region的数量来匹配软实时的目标;old region的选择将依据在Marking cycle phase中对存活对象的计数,G1选择存活对象最少的Region进行回收。
回收后CSet所有分区都会被释放,内部存活的对象都会被转移到分配的空闲Region中。
成文时间所限,难免校对勘误疏漏,诸位看官还请宽容本人的愚钝,欢迎补充指正。
参考文献:
[1] https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/
[2] https://docs.oracle.com/javase/8/docs/technotes/tools/unix/index.html
[3] https://www.jishuwen.com/d/2MMn#tuit
[4] https://docs.cloudera.com/HDPDocuments/HDP3/HDP3.1.0/data-
[5] https://storage/content/recommended_settings_for_g1gc.html
☆ END ☆
招聘信息
OPPO商业中心数据标签团队招聘多个岗位,我们致力于穿透大数据来理解每个OPPO用户的商业兴趣。 数据快速拓展和深挖中,诚邀对数据分析、大数据处理、机器学习/深度学习、NLP等有两年以上经验的您加入我们,与团队和业务一同成长!
简历投递:ping.wang#oppo.com
OPPO互联网运维云存储团队急缺多个岗位, 如果对MongoDB内核源码、Wiredtiger存储引擎、RocksDB存储引擎、数据库机房多活、数据链路同步系统、中间件、数据库等有兴趣的同学。 欢迎加入OPPO大家庭,一起参与OPPO百万级高并发文档数据库研发。
工作地点: 成都 / 深圳
邮箱: yangyazhou#oppo.com
你可能还喜欢
广告场景中的机器学习应用
Spark ML的特征处理实战
图平台技术及应用实践
主流Gradient Boosting算法对比
更多技术干货
扫码关注
OPPO互联网技术

我就知道你“在看”
正文到此结束
- 本文标签: root tar UI MongoDB http Collection 并发 update Region HTML src IO 存储引擎 java 家庭 map 空间 同步 深度学习 JVM 目录 https 互联网 时间 value cache 索引 云 db 线程 代码 key queue mongo tab 广告 大数据 Document 招聘 高并发 unix 数据库 IDE parse ACE id 源码 Oracle 数据 遍历 删除 垃圾回收
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

