聊聊 HashMap 和 TreeMap 的内部结构
点击上方“ 高性能服务器开发 ”,选择“置顶公众号”
技术文章第一时间送达!
作者:Java一日一条
cloud.tencent.com/developer/article/1401451
一、HashMap
1、基于哈希表的 Map 接口的实现。
此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
2、HashMap 的实例有两个参数影响其性能: 初始容量 和 加载因子 。
容量是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。
加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
按照key关键字的哈希值和buckets数组的长度取模查找桶的位置,如果key的哈希值相同,Hash冲突(也就是指向了同一个桶)则每次新添加的作为头节点,而最先添加的在表尾。
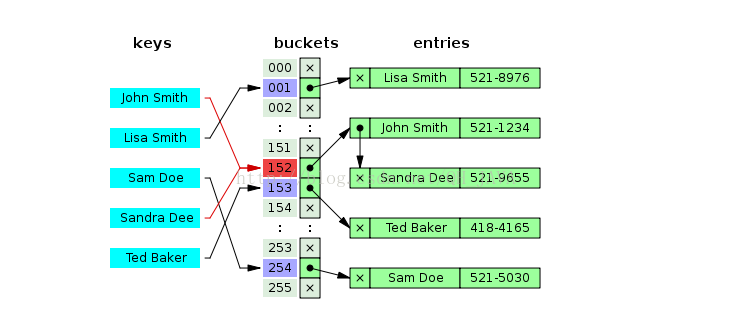
HashMap中的桶的个数就是下图中的0- n的数组的长度,存储第一个entry的位置叫 桶(bucket) 而桶中只能存一个值也就是链表的头节点,链表的每个节点就是添加的一个值(HashMap内部类Entry的实例Entry有哪些属性之后在详说)。
也可以这样理解,一个entry 类型的存储链表的数组。数组的索引位置就是一个个桶的索引地址。

从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。
一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12、28%16=12、108%16=12、140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap简单总结:
1、HashMap 是链式数组(存储链表的数组)实现查询速度可以,而且能快速的获取key对应的value;
2、查询速度的影响因素有 容量和负载因子,容量大负载因子小查询速度快但浪费空间,反之则相反;
3、数组的index值是(key 关键字, hashcode为key的哈希值, len 数组的大小):hashcode%len的值来确定,如果容量大负载因子小则index相同(index相同也就是指向了同一个桶)的概率小,链表长度小则查询速度快,反之index相同的概率大链表比较长查询速度慢。
4、对于HashMap以及其子类来说,他们是采用hash算法来决定集合中元素的存储位置,当初始化HashMap的时候系统会创建一个长度为capacity的Entry数组,这个数组里可以存储元素的位置称为桶(bucket),每一个桶都有其指定索引,系统可以根据索引快速访问该桶中存储的元素。
5、无论何时HashMap 中的每个桶都只存储一个元素(Entry 对象)。由于Entry对象可以包含一个引用变量用于指向下一个Entry,因此可能出现HashMap 的桶(bucket)中只有一个Entry,但这个Entry指向另一个Entry 这样就形成了一个Entry 链。
6、通过上面的源码发现HashMap在底层将key_value对当成一个整体进行处理(Entry 对象)这个整体就是一个Entry对象,当系统决定存储HashMap中的key_value对时,完全没有考虑Entry中的value,而仅仅是根据key的hash值来决定每个Entry的存储位置。
注意点
JDK1.8中使用一个Node数组来存储数据,但这个Node可能是链表结构,也可能是红黑树结构如果插入的key的hashcode相同,那么这些key也会被定位到Node数组的同一个格子里。
如果同一个格子里的key不超过8个,使用链表结构存储。如果超过了8个,那么会调用treeifyBin函数,将链表转换为红黑树。那么即使hashcode完全相同,由于红黑树的特点,查找某个特定元素,也只需要O(log n)的开销。
也就是说put/get的操作的时间复杂度最差只有O(log n)。
需要注意: key的对象,必须正确的实现了Compare接口
二、TreeMap
1、红黑树是一种近似平衡的二叉查找树,它能够确保任何一个节点的左右子树的高度差不会超过二者中较低那个的一倍。具体来说,红黑树是满足如下条件的二叉查找树(binary search tree):
-
每个节点要么是红色,要么是黑色。
-
根节点必须是黑色
-
红色节点不能连续(也即是,红色节点的孩子和父亲都不能是红色)。
-
对于每个节点,从该点至null(树尾端)的任何路径,都含有相同个数的黑色节点。
在树的结构发生改变时(插入或者删除操作),往往会破坏上述条件3或条件4,需要通过调整使得查找树重新满足红黑树的条件。
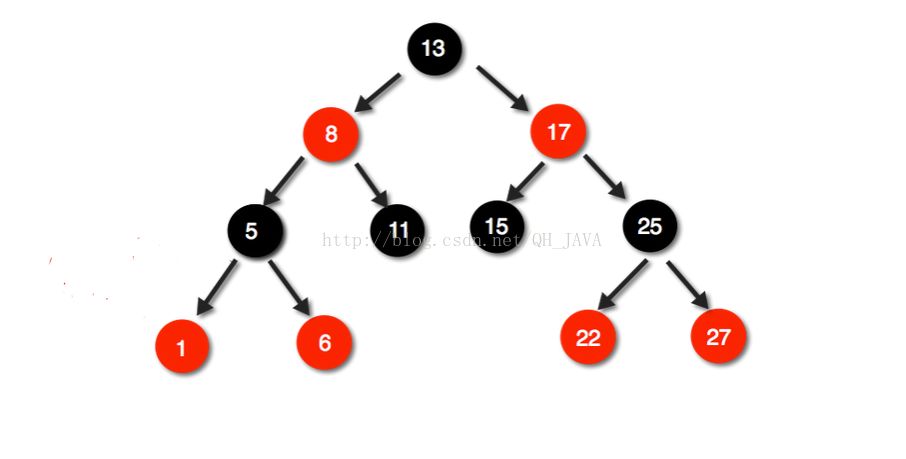
2、TreeMap的底层使用了红黑树来实现,像TreeMap对象中放入一个key-value 键值对时,就会生成一个Entry对象,这个对象就是红黑树的一个节点,其实这个和HashMap是一样的,一个Entry对象作为一个节点,只是这些节点存放的方式不同。
3、存放每一个Entry对象时都会按照key键的大小按照二叉树的规范进行存放,所以TreeMap中的数据是按照key从小到大排序的。
TreeMap总结:
程序添加新节点时,总是从树的根节点开始比较,即将根节点当成当前节点。如果新增节点大于当前节点并且当前节点的右节点存在,则以右节点作为当前节点,如果新增节点小于当前节点并且当前节点的左子节点存在,则以左子节点作为当前节点;
如果新增节点等于当前节点,则用新增节点覆盖当前节点,并结束循环 直到某个节点的左右子节点不存在,将新节点添加为该节点的子节点。如果新节点比该节点大,则添加其为右子节点。如果新节点比该节点小,则添加其为左子节点。
历史精华文章推荐:
1. 我是如何年薪五十万的?
2. 聊一聊程序员如何增加收入
3. 技术面试与 HR 谈薪技巧
4. 我求职后端开发经理的面试经历与总结
5. 如何设计断线自动重连机制
6. 心跳包机制设计详解
7. Linux 网络故障排查的瑞士军刀
8. Linux tcpdump 使用介绍
9. 服务器开发通信协议如何设计
10. 谈一谈如何学习架构11. 谈一谈如何拿大厂offer
12. 如何学习 Modern C++?
欢迎关注公众号『 高性能服务器开发 』,如果你在学习的过程中有任何疑问可以加入高性能服务器开发交流群: 578019391 一起交流,本群汇集 BAT 各类大佬,也欢迎各大互联网公司猎头、HR 进群寻觅人才。

我知道你 “ 在看 ”
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

