一招提速30ms,解密58同镇推荐业务之动态日志级别配置实践
导语
最近在做58同镇推荐数据响应时间优化,在代码重构方面做了很多工作的同时,思考了从日志方面优化响应时间的方法。 希望我们的思路能够对大家有所启发。
背景
推荐场景下,服务的响应时间对用户体验至关重要,200ms以下返回推荐数据对于服务接口来说是一个挑战,一丝一毫的可优化点都值得思考并优化。
然而在后端算法不断迭代、增多的情况下,保证服务响应时间也是不得不面对的难题。从日志级别着手优化是折中的一种方法,有利有弊,存在不能复现某些特定场景下特定Imei的请求情况的可能,不过为防止这种情况,可以分组日志级别对待,这种取舍需要根据实际情况决定是否执行。带来的好处是明显的,最直接的体现就是响应时间加快。
场景
最近在做58同镇推荐数据响应时间优 化,在代码重构方面做了很多工作的同时,思考了从日志方面优化响应时间的方法。 结合58同镇内部SCF(Service Communication Framework)工程(不同于SpringBoot等原生Spring项目)、Log4j框架、JDK8实现线上环境业务日志级别控制。
SCF支持跨平台,具有高并发、高性能、高可靠性、并提供异步、多协议、事件驱动等。读者可以把SCF理解为一种SOA服务框架,类似Dubbo,也有Server端、Client端、Serializer序列化、Protocol传输协议等。
本文重点是想传达种配置思想,这种思想不局限于具体的日志框架、不局限于某种具体SOA框架,所以后文没有对SCF本身做过多的表述,而重点提到在这个大背景下的接口性能优化及问题排查。在服务响应时间优化方面,切实可行的方法很多。在推荐业务中,前期已经做了大量的响应时间优化工作,例如:
-
尽量少用JDK8中已经封装好的简易集合操作。例如Lamda表达式,优化后删除了程序中使用到的Lamda表达式,因为单元测试表明,Lamda表达式并没有通用的For循环省时。
-
对于所使用的第三方依赖库,需要了解响应性能情况。例如对象属性值拷贝时,用传统的对象Set、Get方法,比通用的Copy工具类(CGLib、反射等)用时更节省。
-
CAP之间总是要做权衡,用户实时行为及时响应与延迟响应之间也要取舍。例如在推荐算法中,对于大数据量的算法模型实时数据计算改为离线计算,数据预先加载等。
-
直接从内存中取数据。例如服务接口中,涉及的黑白名单数据变动不是很频繁,数据量也不会太大,这种类型的数据可以通过Guava内存缓存在本地,过期时间可以根据业务调整,当数据过期时再从Redis中查询到最新的黑白名单数据,响应用时几乎0毫秒。
-
多线程的灵活运用,空间换时间。通过多线程全并发查询召回候选集、排序模型、融合模型,即通过空间换时间的方式来加快数据计算,对于响应超时的召回走兜底逻辑等。
-
编写代码时,方法命名不宜过长,且慎用以get开头,因为在直接使用框架调用此代码时可能会有问题。例如使用com.alibaba.fastjson.JSON. toJSONString(Object object)方法时要特别注意object对象中以get开头命名的方法。曾经线上使用时出现了服务接口被调用两次的情况,梳理代码时,发现显示的只调用了一次服务接口,可是日志记录显示服务接口被调用了两次,导致此问题的原因就是com.alibaba.fastjson.JSON. toJSONString(Object object)中会调用object中的以get开头的方法。
-
降低IO网络传输消耗,减少服务调用次数。在服务之间依赖调用时,尽量减小传输实体大小,减小序列化传输Size的大小,对于字段值占用过多字节的尽可能不传输,例如文章内容不传输,只传输文章id。对于同一个服务的多次调用改为一次调用等等。
当然,优化日志部分也是其中之一,如果来回修改代码中日志级别部分,然后再上线,这样操作会使人身心俱惫,且操作繁琐费时。日志级别可配置更利于修改或扩展。
同时,对于线上出现的诡异问题,提供种排查问题的思路。
服务优化后访问量耗时平均值下降30ms+。
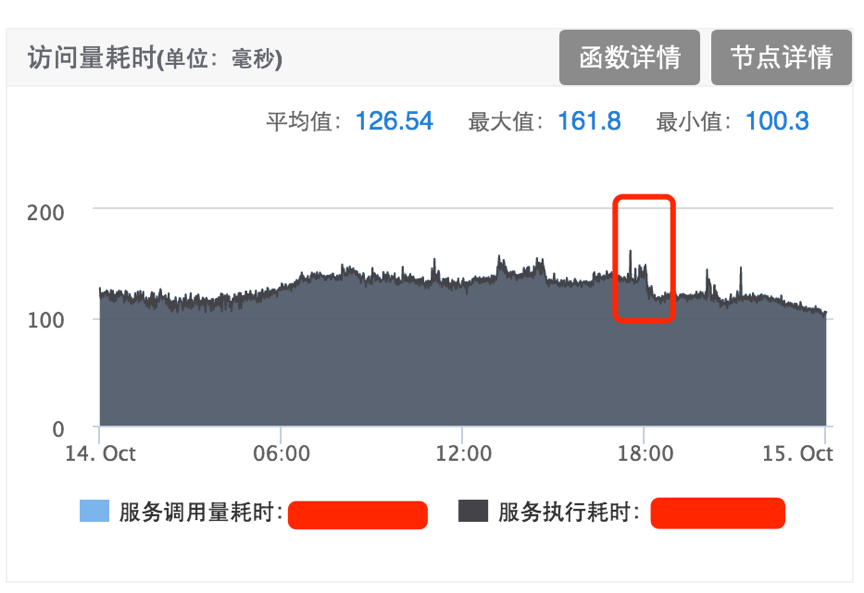
红框部分下降30ms+
配置步骤
配置步骤大概分为以下几步:
-
线上部署机器环境分组
-
不同组设置不同日志级别
-
设置环境变量
-
程序中读取环境变量
-
程序中设置全局日志级别
配置流程图如下:
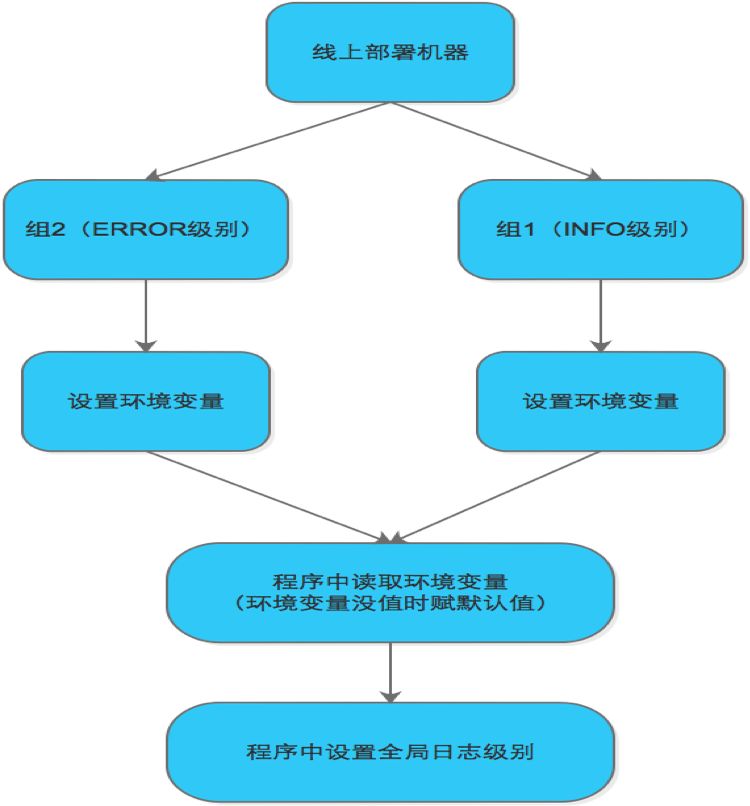
配置流程图
我们可以配置更多组来更细化日志配置,这里配置了两个组,来解决重点关心的响应时间问题。如果您更关心Debug级别日志,当然也可以配置对应级别的分组。
具体配置
机器分组配置
在云管理平台分组管理中点击新建,如下图中建立了两个分组:
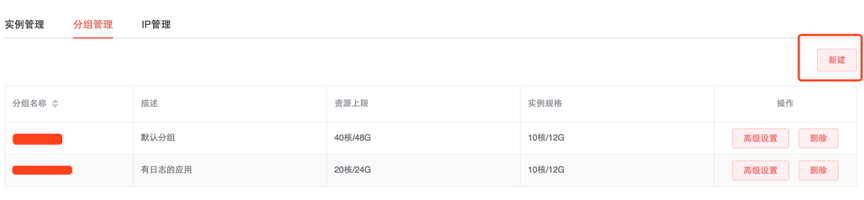
分组管理页面
这样做只是为了做环境区分,任何的部署平台都能够做到环境隔离,例如TeamCity等。这里用的是公司内部的云平台。
点击上图的新建按钮后弹出页面如下图:
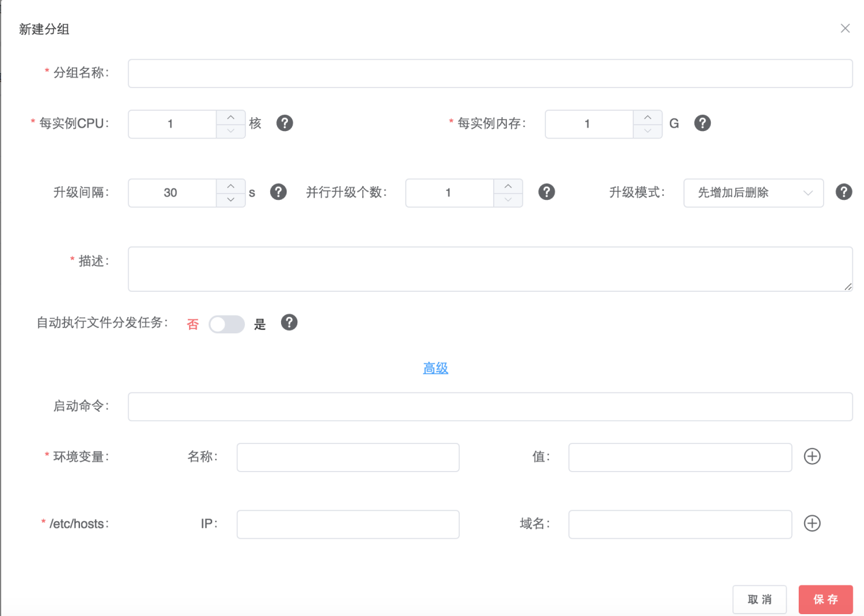
新建页面
当然了,我们也可以不依赖这个页面,而是自己指定把变量存储在某个文件中,然后把这个文件放置在某个服务器的某个路径下,在程序中,我们只需要把变量值读取出来就可以。或者通过中间DB(Redis、Mongodb等)存储,再从程序中读出。
环境变量配置
在实例管理中点击配置分组,并点击高级设置环境变量,例如logLevel
配置分组页面
环境变量名可随意命名,为了见名知意,我们这里设置环境变量名为logLevel,值为INFO,程序中会赋默认值,防止读取变量值为空时的空指针问题。
程序部分配置
主要Java代码如下:
1) 读取环境变量
String logLevel = System.getenv("logLevel");
这里我们通过JDK自带的工具包获得环境变量值,如果此值是存储到某服务器的某个指定目录下或通过中间DB(Redis、Mongodb等)存储的,那程序中读取时,按相应的读取程序编写即可。
2) 设置全局日志级别
import org.apache.log4j.Level;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
LogManager.getRootLogger().setLevel(realLevel);
不同的日志框架设置全局日志级别时的代码可能不同,需要区别对待。
3) 日志打印
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
private static Logger log = LoggerFactory.getLogger(xxx.class);
这里需要注意,推荐Slf4j框架的日志打印,在log4j的上面加上Slf4j,将要输出的日志提前格式化成一个字符串。加入Slf4j后可以发现的是日志的输出分成两步了,因为执行log.info时,会首先对要输出的内容进行格式化,将其格式化成一个String,所以不会发生死锁。并不推荐以下方式的日志打印:
import org.apache.log4j.Logger;
private static Logger logger = Logger.getLogger(xxx.class);
这种方式可能会出现Locked死锁问题,线上环境也确实出现了这种导致服务不可用的情况,文章后面会提到。
问题排查
通过后台输出日志可以看出,日志级别的配置是成功的。可以做到分组配置日志级别。这样就可以在不修改代码的情况下按情况配置日志级别,按需查看日志及线上问题排查。
当用到日志时,统一日志规范很重要,在线上部署的情况下,看似容易的日志打印也会出现怪异的线上问题,并导致服务接口不可用。例如某天线上服务接口超时量在9点后的某一时刻突增,如下图:
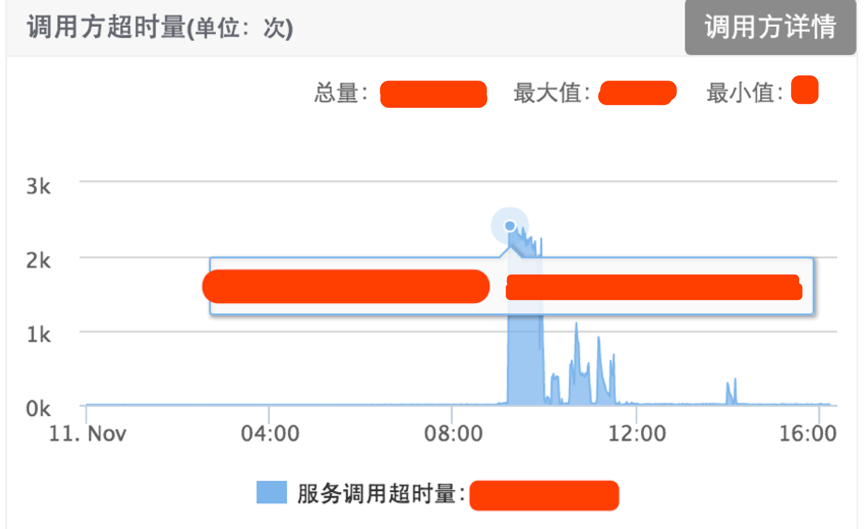
调用方超时量页面
对于这种情况,先入为主的想法可能是SCF服务框架(类似Dubbo)本身有问题了,看后台日志,也确实如此:
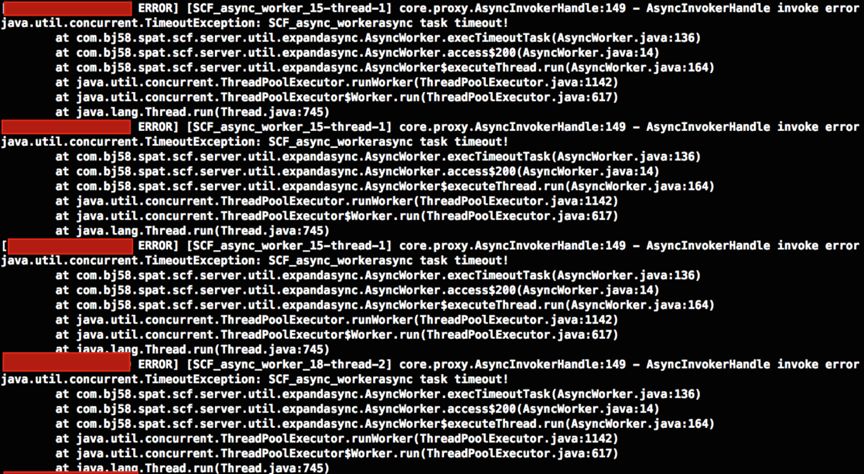
SCF日志
从中看出并发超时TimeoutException异常,不过我们还看不出是哪里导致的框架超时问题。
再细看监控平台发现是FullGC的问题导致服务超时量增多:
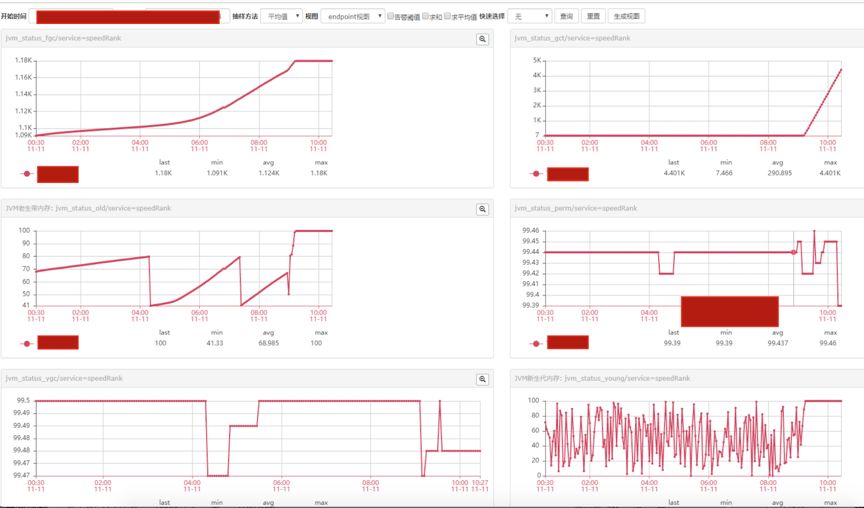
监控页面
为了锁定是什么原因导致的FullGC问题并及时保证线上可用,主要从以下方面入手:
1) 服务应用重启(Error级别分组(组2))
2) Info级别分组(组1)服务节点从线上摘除,并不重启
3) 增大新生代、老生代等JVM参数重新上线(首先保证服务可用)
4) 登录Info级别容器后台查看堆栈信息或GC信息等等
排查时,用以下命令
jstack -l pid >> /tmp/1.log
或
jstat -gc pid
*注意: 确认部署容器是否有jstack或jstat操作命令,及是否有相关目录操作权限。打印出线上环境的堆栈信息,如下图:
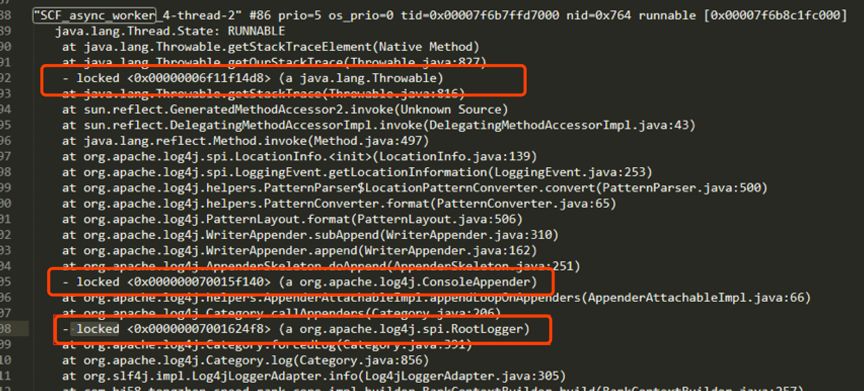
堆栈日志
从中可以看到Locked字样,可以锁定是因为日志框架的死锁问题导致服务不可用。感兴趣的读者可以了解log4j的死锁问题,可以看出这并不是咱们配置日志分组导致的问题,而是log4j框架本身就存在这种死锁问题,使用时需要特别注意。相应的解决方法一般有两方面:
1) 用log4j2或Slf4j日志框架替换log4j。
2) 注意定义日志变量时加入static声明,或在打印日志配置中设置缓冲区
<appender name="MyLog" class="org.apache.log4j.DailyRollingFileAppender">
<param name="File" value="/data/logs/feeds/log_info.log" />
<param name="encoding" value="UTF-8" />
<param name="DatePattern" value="'.'yyyy.MM.dd" />
<param name="Append" value="true" />
<param name="BufferSize" value="8192" />
<param name="ImmediateFlush" value="false" />
<param name="BufferedIO" value="true" />
线上日志有死锁问题,那奇怪了,之前也用log4j日志框架,为什么之前没出现这个问题? 具体程序中是什么原因导致的死锁问题呢?
首先,我们用Top命令查看CPU信息等
top
显示如下:
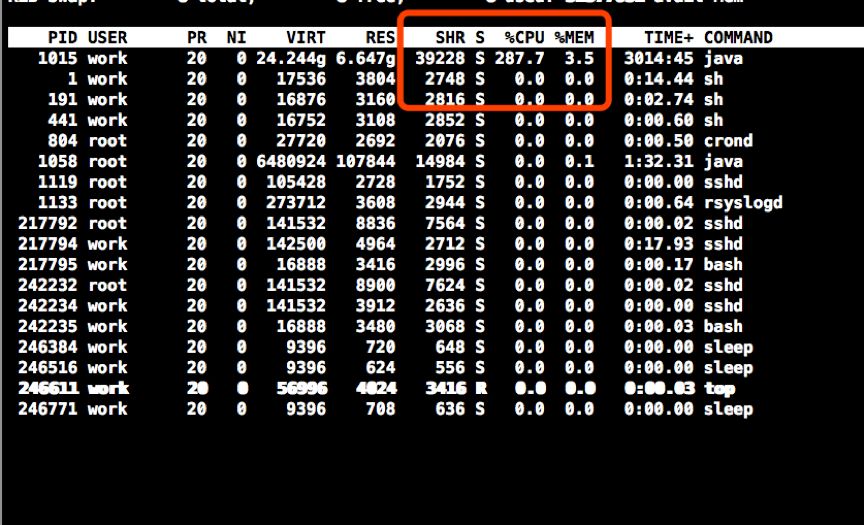
top页面
可以看出线上CPU的占用率特别高,用命令查看GC情况
jstat –gccause pid
显示如下:
jstat页面
从中可以看出YGC特别的频繁,用命令打印堆栈信息
jmap –heap pid
显示如下:
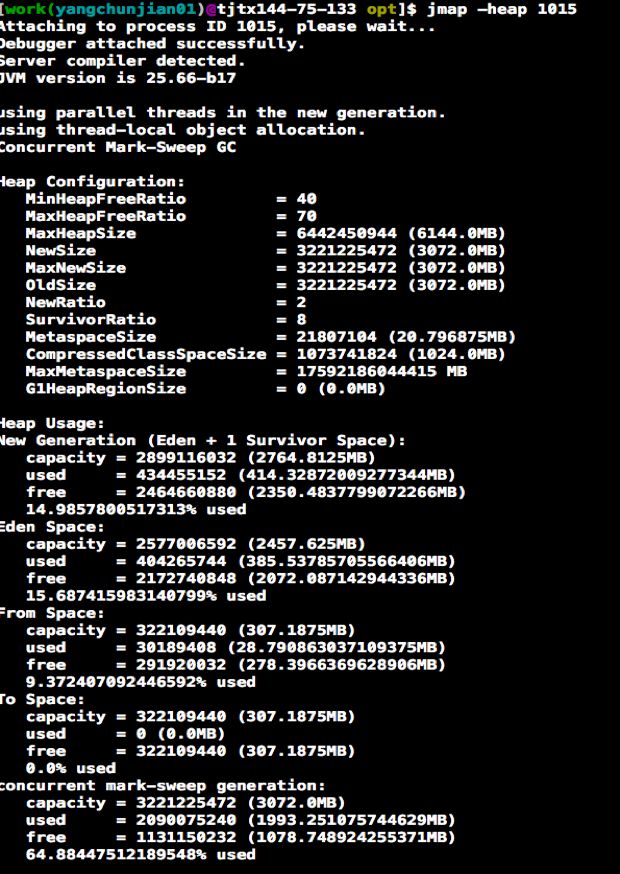
jmap页面
可以看出新生代、老生代等配置及使用情况,用命令:
jmap -dump:live,format=b,file=/opt/heap2.bin pid
导出dump文件,并sz命令到本地。通过MAT(Eclipse Memory Analyzer)工具分析出可以看出某个class占用过多:
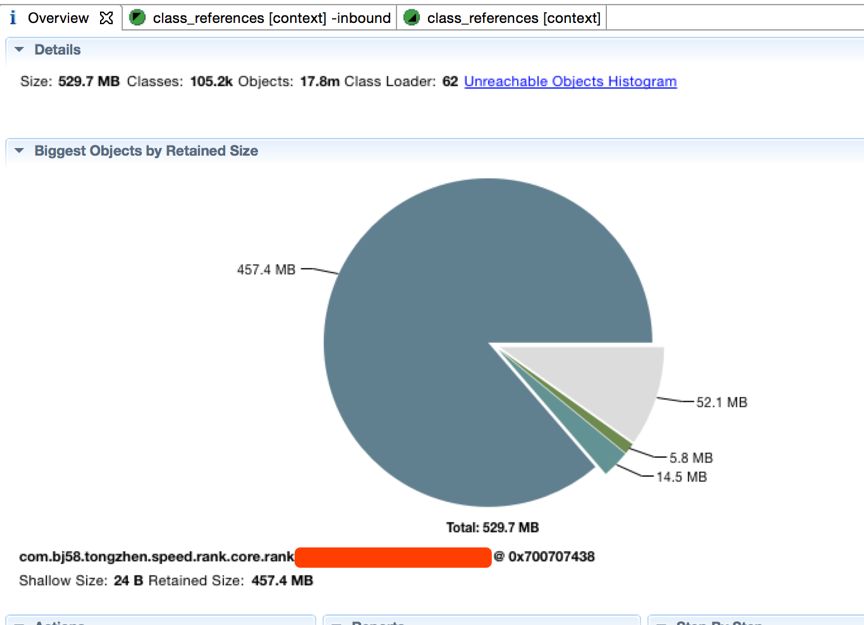
mat页面
至此锁定到具体代码,点击by outgoing references后显示如下:

by outgoing references页面
点击Leak Suspects时,如下图:
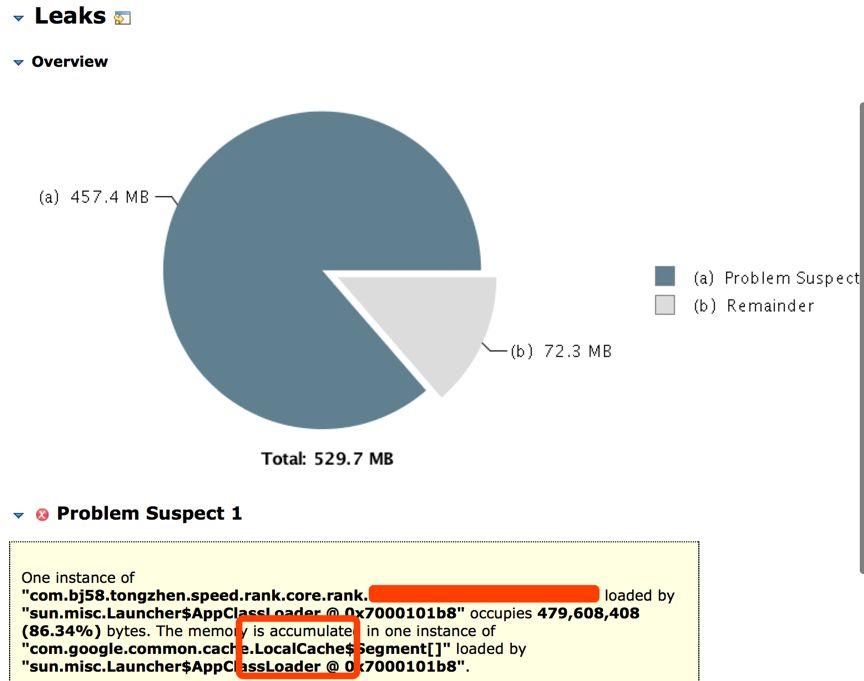
可以看出,在使用Guava缓存时,可能有内存泄漏的情况发生,具体看代码再结合具体业务场景,发现Guava缓存的设置有问题。
public LoadingCache<String, Map<String, List<Double>>> contentVecCache = CacheBuilder.newBuilder()
.maximumSize(40000)
.expireAfterWrite(2, TimeUnit.HOURS)
.build(new CacheLoader<String, Map<String, List<Double>>>() {
@Override
public Map<String, List<Double>> load(String key) {
String itmeId = key.split("_")[0];
int dataSource = Integer.valueOf(key.split("_")[1]);
Map<String, List<Double>> map = new HashMap<>();
List<Double> titleVec = wordEmbeddingService.getContentEmbedding(itmeId, dataSource, EmbedContentType.TITLE);
map.put("title", titleVec);
List<Double> keywordVec = wordEmbeddingService.getContentEmbedding(itmeId, dataSource, EmbedContentType.KEYWORD);
map.put("keyword", keywordVec);
return map;
}
});
缓存的Key数量,还有过期时间配置要结合具体业务、具体的硬件配置来定,不可盲目追求高性能而存入大量数据至撑爆硬件资源。至此,排查出具体哪里出现的问题。
经验总结
1. 部署后,线上环境推荐业务对外SCF服务接口的平均响应时间大概下降了30ms,服务超时量也有明显下降。服务响应时间优化是持续迭代的过程,任何的可优化点都值得思考是否可行,是否还能更优,响应时间下降5ms、10ms都是胜利。
2. 这种配置思想不止于Log4j框架的日志,对于LogBook等任何日志框架一样适用,只需要通过程序设置全局日志级别即可。 这种配置思想中,环境变量的配置并不局限于某个具体系统,可以把环境变量配置在任何可以通过程序读取到的地方,当然为了响应时间考虑可以优先考虑内存形数据库等。
3. 遇到线上问题,沉着、冷静应对是必须的,把恢复线上稳定摆在第一位,然后在追踪问题根源,抽丝剥茧,最终把问题解决并尽量防止再发生。
4. 建议线上环境用Slf4j日志框架,可防止日志死锁问题。从项目一开始,日志框架的选择就要慎之又慎,防止后面更改日志框架时成本过高。
5. 对于其它部门线上环境日志级别如何区分配置也有现实参考意义,从日志层面着手优化也是切实可行的思考方向。
参考文献
1、 https://blog.csdn.net/zl378837964/article/details/84884934
2、 https://yq.aliyun.com/articles/271448
作者简介
杨春建,Java高级开发工程师,现就职于58 SLG-流量智能部。
开奖啦 !!!
恭喜“封刀看海”同学获得2020年官方正品单向历!
祝福新的一年一切顺利,开心快乐!

正文到此结束
- 本文标签: bug 单元测试 root js 数据 代码 实例 开发 src cache 缓存 apache https UI SDN MongoDB 解决方法 lib ORM 模型 cglib java ip 配置 多线程 HTML 参数 client Service springboot JVM spring eclipse map SOA App 经验总结 build 文章 高并发 HashMap 目录 db cat 管理 智能 list dataSource Word 监控平台 性能优化 部署 云 测试 线程 大数据 CTO value dubbo jstack id mongo 并发 协议 数据库 IDE 空间 key 总结 删除 希望 工程师 log4j2 服务器 redis 时间 json 锁 http IO
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

