Java 8 stream 实战
概述
平时工作用python的机会比较多,习惯了python函数式编程的简洁和优雅。切换到java后,对于数据处理的『冗长代码』还是有点不习惯的。有幸的是,Java8版本后,引入了Lambda表达式和流的新特性,当流和Lambda表达式结合起来一起使用时,因为流申明式处理数据集合的特点,可以让代码变得简洁易读。幸福感爆棚,有没有!
本文主要列举一些stream的使用例子,并附上相应代码。
实例
先准备测试用的数据,这里简单声明了一个 Person 类,有名称和年龄两个属性,采用 lombok 注解方式节省了一些模板是的代码,让代码更加简洁。
@Data
@AllArgsConstructor
@NoArgsConstructor
private static class Person {
private String name;
private Integer age;
}
private List<Person> initPersonList() {
return Lists.newArrayList(new Person("Tom", 18),
new Person("Ben", 22),
new Person("Jack", 16),
new Person("Hope", 4),
new Person("Jane", 19),
new Person("Hope", 16));
}
filter
说明
- 遍历数据并检查其中的元素是否符合要求,不符合要求的过滤掉
- filter接受一个函数作为参数(Predicate),该函数用Lambda表达式表示,返回true or false,返回false的数据会被过滤
示例图
数据集合过Predicate方法,留下返回true的数据集合
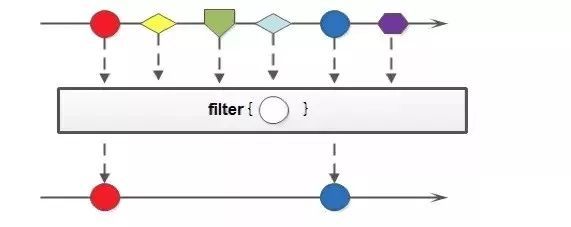
代码
@Test
public void filterTest() {
List<Person> personList = initPersonList();
// 过滤出年龄大于8的数据
List<Person> result = personList.stream().filter(x -> x.getAge() > 18).collect(Collectors.toList());
log.info(JsonUtils.toJson(result));
// filter 链式调用实现 and
result =
personList.stream().filter(x -> x.getAge() > 18).filter(x -> x.getName().startsWith("J")).collect(Collectors.toList());
log.info(JsonUtils.toJson(result));
// 通过 Predicate 实现 or
Predicate<Person> con1 = x -> x.getAge() > 18;
Predicate<Person> con2 = x -> x.getName().startsWith("J");
result =
personList.stream().filter(con1.or(con2)).collect(Collectors.toList());
log.info(JsonUtils.toJson(result));
}
以上是filter的例子,可以使用链式调用实现『与』的逻辑。通过声明 Predicate ,并使用 or 实现『或』逻辑
map
说明
R apply(T t)
示例图
数据集合经过map方法后生成的数据集合,数据个数保持不变,即一对一映射

代码
@Test
public void mapTest() {
List<Person> personList = initPersonList();
List<String> result = personList.stream().map(Person::getName).collect(Collectors.toList());
log.info(JsonUtils.toJson(result));
Set<String> nameSet =
personList.stream().filter(x -> x.getAge() < 20).map(Person::getName).collect(Collectors.toSet());
log.info(JsonUtils.toJson(nameSet));
}
map比较简单,这里不赘述了,直接看代码
flatmap
说明
- 和map不同的是,flatmap是个一对多的映射,然后把多个打平
- flatmap接收的函数参数也是Fuction,但是还和map的入参Function相比,可以看到返回值不同。flatmap,返回的是Stream<R>,map返回的是R,这就是上面说的一对多映射
示例图
从图中也可以看到一对多映射,例如红色圆圈经过flapmap后变成了2个(一个菱形、一个方形)
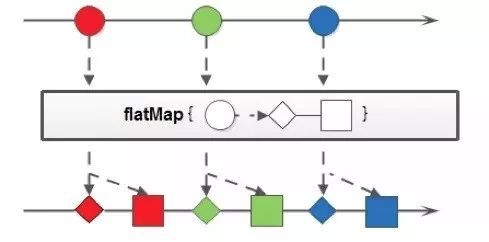
代码
@Test
public void flatMapTest() {
List<Person> personList = initPersonList();
List<String> result =
personList.stream().flatMap(x -> Arrays.stream(x.getName().split("n"))).collect(Collectors.toList());
log.info(JsonUtils.toJson(result));
}
以上代码打印: ["Tom","Be","Jack","Hope","Ja","e","Hope"] ,对每个人的姓名用字母n做了切分
reduce
说明
R apply(T t, U u)
示例图
下面是1+2+3+4+5的例子,可以用reduce来解决
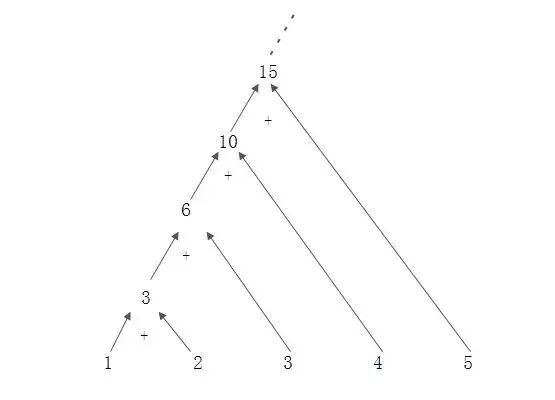
代码
@Test
public void reduceTest() {
Integer sum = Stream.of(1, 2, 3, 4, 5).reduce(0, Integer::sum);
Assert.assertEquals(15, sum.intValue());
sum = Stream.of(1, 2, 3, 4, 5).reduce(10, Integer::sum);
Assert.assertEquals(25, sum.intValue());
String result = Stream.of("1", "2", "3")
.reduce("0", (x, y) -> (x + "," + y));
log.info(result);
}
对应示例图的代码实现,有数字求和的例子和字符串拼接的例子
collect
collect在流中生成列表,map,等常用的数据结构。常用的有 toList(), toSet(), toMap()
下面代码列举了几个常用的场景
@Test
public void collectTest() {
List<Person> personList = initPersonList();
// 以name为key, 建立name-person的映射,如果key重复,后者覆盖前者
Map<String, Person> result = personList.stream().collect(Collectors.toMap(Person::getName, x -> x,
(x, y) -> y));
log.info(JsonUtils.toJson(result));
// 以name为key, 建立name-person_list的映射,即一对多
Map<String, List<Person>> name2Persons = personList.stream().collect(Collectors.groupingBy(Person::getName));
log.info(JsonUtils.toJson(name2Persons));
String name = personList.stream().map(Person::getName).collect(Collectors.joining(",", "{", "}"));
Assert.assertEquals("{Tom,Ben,Jack,Hope,Jane,Hope}", name);
// partitioningBy will always return a map with two entries, one for where the predicate is true and one for where it is false. It is possible that both entries will have empty lists, but they will exist.
List<Integer> integerList = Arrays.asList(3, 4, 5, 6, 7);
Map<Boolean, List<Integer>> result1 = integerList.stream().collect(Collectors.partitioningBy(i -> i < 3));
log.info(JsonUtils.toJson(result1));
result1 = integerList.stream().collect(Collectors.groupingBy(i -> i < 3));
log.info(JsonUtils.toJson(result1));
}
- 建立name-person的映射,如果key重复,后者覆盖前者。
Collectors.toMap的第三个参数就是BiFunction,和reduce中的一样,输入两个参数,返回一个参数。(x, y) -> y就是(oldValue, newValue) -> oldValue,如果不加这个方法,那么当出现map的key重复,会直接抛异常 - 将list转化为一对多的map,可以采用
Collectors.groupingBy,上述例子就是用person的name做为key,建议一对多映射关系 - 这里提到了
groupingBy和partitioningBy的区别,前者是根据某个key进行分组,后者是分类,看他们的入参就明白了,groupingBy的入参是Function,partitioningBy的入参是Predicate,即返回的是true/false。所以partitioningBy的key就是两类,true和false(即使存在空列表,true 和 false 两类还是会存在)
代码下载
- Java 8 stream 实战: 代码 commit , 源码下载
参考文档
- 使用 Stream API 优化代码
- Java 8 - Stream 集合操作快速上手
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

