Java集合系列之四:HashMap底层原理
HashMap底层原理
HashMap 是最常用的存储键值对的集合,继承了 AbstractMap 类,实现了 Map 等接口,内部原理是基于散列函数计算出元素存储的位置,查询的时候也是根据散列函数继续计算出存储的位置去获取该位置上存储的元素,非并发安全。
-
底层数据结构
值得注意的是1.8版本的
HashMap对底层结构做了优化,所以这里以1.7版本和1.8版本作为对照版本。-
1.7版本
在1.7版本中,底层数据结构是数组和链表,也就是一个数组用来存储
value,那为啥还有链表呢?因为散列函数是很有可能出现哈希碰撞的,也就是两个不同的key计算得出同一个哈希值,结果就存到同一个数组索引上了,那不能覆盖掉前面的值呀,所以数组中存的是链表,如果有冲突了,同一个索引上就使用链表来存储多个值。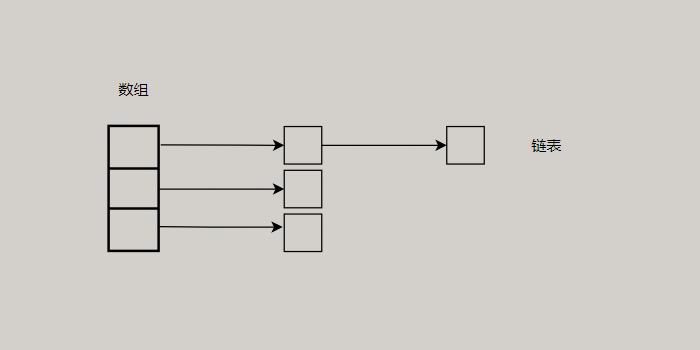
实现链表的内部类
static class Node<K,V> implements Map.Entry<K,V> {...} -
1.8版本
因为链表的查询时间是O(n),所以冲突很严重,一个索引上的链表非常长,效率就很低了,所以在1.8版本的时候做了优化,当一个链表的长度超过8的时候就转换数据结构,不再使用链表存储,而是使用红黑树,红黑树是一个保证大致平衡的平衡树,所以性能相较AVL树这样的高度平衡树来将性能会更好。
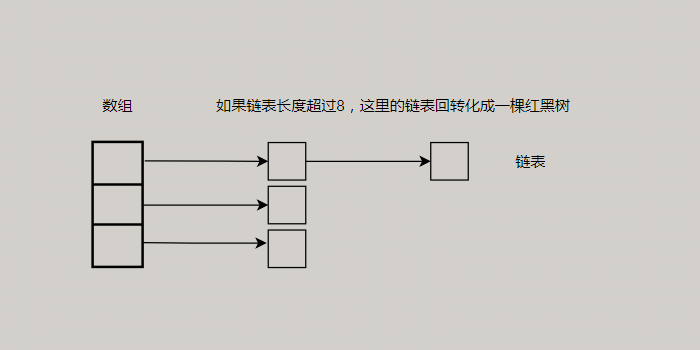
实现红黑树的内部类
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {...}
-
-
构造方法
总共有四个构造方法,第一个默认无参的,第二个是可以设置map大小,第三个是既可以设置大小又可以设置装填因子,装填因子和大小是计算map是否需要扩容的两个必要因素,后面会介绍,第四个是接收另一个map作为参数,创建出来的新map里会包含这个map中所有的值。
HashMap(){}; HashMap(int initialCapacity){}; HashMap(int initialCapacity, float loadFactor){}; HashMap(Map<? extends K, ? extends V> m){}; -
put()方法
-
1.7版本
可以看到1.7版本的
put()方法相对来说比较简单,毕竟固定就是数组加链表的结构,先计算下哈希值,再根据哈希值计算索引,再判断索引上有没有值,有的话就是链表尾部增加节点,注意的是key为null的话直接存到了数组索引为0的位置上,因为会遍历链表覆盖相同key的缘故,所以HashMap中只能有一个key为null,还有就是addEntry()方法里面调用会进行容量判断是否调用扩容方法resize()。public V put(K key, V value) { if (key == null) // 存放null值 return putForNullKey(value); // 计算哈希值 int hash = hash(key); // 根据哈希值计算索引 int i = indexFor(hash, table.length); // 如果索引上已经有值就在链表上添加节点 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; // 索引上没值,直接添加value addEntry(hash, key, value, i); return null; } private V putForNullKey(V value) { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(0, null, value, 0); return null; } -
1.8版本
1.8版本的
put()方法就要复杂的多了,直接新写了一个putVal()方法来调用,在1.7的步骤上还加多了一步,判断是插入链表还是插入红黑树,如果是插入链表则还要判断是否需要转换为红黑树。public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } // 计算哈希值 static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // map还没初始化或者数组长度为0时调用扩容方法来初始化 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 计算哈希值,存储数据,如果该索引上没有数据,数据是节点形式插入 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); // 索引上已经有数据 else { Node<K,V> e; K k; // 对比寻找索引上第一个元素hash值相等,key相等,新插入的值会覆盖旧值 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 如果节点是红黑树节点,插入红黑树 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); // 插入链表 else { // 循环到尾部,插入 for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); // 链表长度大于等于8了,转换为红黑树 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } // 如果插入的数据是相同key直接覆盖 if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; // 判断是否扩容 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
-
-
get()方法
-
1.7版本
1.7版本的
get()方法就很简单了,key是null值直接取数组的第一个元素,否则就计算哈希值找到对应索引,遍历链表查找。public V get(Object key) { if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); } private V getForNullKey() { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) return e.value; } return null; } final Entry<K,V> getEntry(Object key) { int hash = (key == null) ? 0 : hash(key); // 遍历链表 for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; // 查找链表中哪一个节点key和哈希值都对的上 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; } -
1.8版本
1.8版本的
get()方法也要复杂一点,还需要判断当前索引上是链表还是红黑树,不同的结构需要调用不同的方法。public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { // 检查索引上第一个节点来判断 if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && // key匹配就返回value key.equals(k)))) return first; if ((e = first.next) != null) { // 红黑树节点类型,查找红黑树 if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); // 遍历链表 do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; }
-
-
扩容方法
HashMap中最核心的方法,当按照计算规则发现存储的元素超过阀值的时候就需要调用该方法扩容,所有的元素都会重新计算哈希值来重新存储到不同的位置,非常耗费时间。// 默认的初始容量是16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认的填充因子 static final float DEFAULT_LOAD_FACTOR = 0.75f; // 最大容量 static final int MAXIMUM_CAPACITY = 1 << 30; // 阀值,超过这个数就要扩容 int threshold; final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; // 当前元素个数 int oldCap = (oldTab == null) ? 0 : oldTab.length; // 当前阀值 int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { // 当前容量超过最大值就直接把容量设置为Integer.MAX_VALUE if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } // 没超过就把阀值扩充到原来的两倍 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } // 设置了容量的构造方法,设置了阀值,元素个数为0 else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; // 无参构造方法默认初始化 else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } // 计算新的阀值 if (newThr == 0) { // 当前新容量乘以装填因子,比如100*0.75=75 float ft = (float)newCap * loadFactor; // 计算新的阀值 newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; // 将旧数组中的值全部重新计算哈希值和索引位置分配到新数组中 @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; } -
初始化的容量
前面讲到可以初始化的是有指定容量,但是要注意的是并不是说指定多少就一定是多少,可以看到构造方法中调用了一个
tableSizeFor()方法,进行了一系列的位运算,20会计算成32,10000则会计算成16384,然后阀值则是在这个数字的基础上乘以装填因子,这才是真正的容量和阀值。public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); } static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; } - 并发问题
虽然说
HashMap本来就不是线程安全的不应该使用,但是在1.8版本以前的HashMap在并发情况下使用并不仅仅是可能会造成数据不准确,还有可能造成内部链表死循环,大致原因是在并发情况下进行扩扩容,重新计算链表上的元素的哈希值,因为是循环操作,所以并发情况下有概率形成循环链表,不过1.8版本已经修复了循环链表的问题,但还是会有数据丢失问题,所以切记并发情况下使用ConcurrentHashMap。
总结
HashMap HashMap
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

