Java爬取喜马拉雅非付费音频【优化】
Java爬取喜马拉雅非付费音频【优化】
本文在 CSDN 同步更新
前言
年初,我写了 Java爬取喜马拉雅非付费音频 这篇文章;后来代码一直没有维护过。前段时间,有个哥们下载了我的代码,发现运行失败,我觉得有点儿对不住这个哥们。但因为前段时间太忙,没顾得上,因此今天抽空重新研究了下。

具体回顾
具体前期研究过程,我就不多说了,大家可以前往 Java爬取喜马拉雅非付费音频 查看。总的来说,这篇文章和程序的目的是使用java批量下载喜马拉雅某个专辑的音频。
回顾一下:
- https://www.ximalaya.com/revision/album?albumId=10710983 这个get请求可以拿到albumId为10710983这个专辑的基本信息,里面包括标题、分页数、总条数等基本信息。
- https://www.ximalaya.com/revision/album/v1/getTracksList?albumId=10710983&pageNum=1&sort=-1 这个get请求可以拿到albumId为10710983在第一页正序排列的列表信息,每一条可以拿到trackId。
- https://www.ximalaya.com/revision/play/v1/audio?id=51685504&ptype=1 这个get请求可以拿到albumId为10710983,trackId为51685504的音频下载链接为: https://fdfs.xmcdn.com/group32/M04/F4/AD/wKgJnFnDkSXBhbD_AD4MWX93TBM147.m4a
注:albumId为10710983的专辑名为:离婚 老舍先生的中篇小说
大家可以把url拷贝到浏览器,仔细看看json数据,于是我们可以知道,第一个url可以拿到某个专辑的基本信息,从而确定页码数;第二个url可以拿到具体某一个音频的专属trackId;第三个url可以通过trackId拿到音频的网络路径。经过此三步,我们便可以下载音频到本地。
上一篇文章的问题
整体逻辑是没有问题的,我看了下我上一篇文章的代码。发现我获取列表的接口是下面这个:
https://www.ximalaya.com/revision/play/album
在这个接口里原本是可以直接获取到列表信息,最主要的是可以直接拿到下载路径;可是,现在这个接口返回的数据为:
[SIGN] no sign or wrong sign
这也是上面那个哥们拿不到json数据的原因。
因此,我们爬取平台的数据的代码是要经常维护的,每个平台都有可能将之前暴露对外的接口进行改造。所以,在爬虫这件事情上我们应该学习分析方法,而不是依赖于一成不变的代码。通过 抓包、分析、模拟请求、获取数据 一整套流程拿到的数据才是真的数据。
改造点
这次的改造主要体现在调用接口上。当然,为了提高效率,我把之前的单线程下载改成了多线程下载。想一睹为快的童鞋可以前往我的 git仓库 。
1.调用处修改
package temt.download;
import temt.bean.AudioBean;
import temt.util.AudioDealUtil;
/**
* @author temt
* @time 2018年12月13日21:45:34
* @time 2019年12月29日14:25:42 修改
*/
public class Main implements Runnable{
private String albumId;//专辑ID
public Main(){}
public Main(String albumId){
this.albumId = albumId;
}
@Override
public void run() {
try {
downAudio(albumId);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void downAudio(String albumId) throws InterruptedException{
//初始化音频列表,修改专辑ID便可下载该专辑的音频内容(非付费)
AudioBean audioBean = AudioDealUtil.initBean(
"https://www.ximalaya.com/revision/album",
"albumId="+albumId);
//修改下载路径
AudioDealUtil.initDownloadAudio("https://www.ximalaya.com/revision/album/v1/getTracksList",
audioBean,
"D://ximalaya03//");
}
public static void main(String[] args) throws InterruptedException{
Main thread01 = new Main("6661211");//《杉杉来吃》顾漫
Main thread02 = new Main("12040477");//人間失格
Main thread03 = new Main("31844110");//老舍名著《茶馆》地道北京话演绎
Main thread04 = new Main("10710983");//离婚 老舍先生的中篇小说
Thread th01 = new Thread(thread01);
Thread th02 = new Thread(thread02);
Thread th03 = new Thread(thread03);
Thread th04 = new Thread(thread04);
th01.start();
th02.start();
th03.start();
th04.start();
}
}
2.获取下载链接的方法修改
/**
* 初始化音频下载列表数据
* @param url
* @param audioBean
* @throws InterruptedException
*/
public static void initDownloadAudio(String url,AudioBean audioBean,String targetUrl) throws InterruptedException{
int trackTotalCount = audioBean.getTrackTotalCount();
int count = 0;
for(int j = 0 ; j < audioBean.getTotalPage() ; j++){
//参数
String param = "albumId="+audioBean.getAlbumId()+"&pageNum="+(j+1)+"&sort=-1";
String result = HttpUtil.sendGet(url,param);
JSONObject resultJson = JSONObject.fromObject(result);
JSONObject dataJson = resultJson.getJSONObject("data");
JSONArray tracksAudioPlayJSONArray = dataJson.getJSONArray("tracks");
for(int i = 0 ; i < tracksAudioPlayJSONArray.size() ; i++){
JSONObject object = tracksAudioPlayJSONArray.getJSONObject(i);
String trackName = object.getString("title");
String trackId = object.getString("trackId");
String audioFinal = HttpUtil.sendGet("https://www.ximalaya.com/revision/play/v1/audio","id="+trackId+"&ptype=1");
JSONObject audioFinalJson = JSONObject.fromObject(audioFinal).getJSONObject("data");
String downloadUrl = audioFinalJson.getString("src");
Thread.sleep(100L);
downloadAudio(downloadUrl,targetUrl,trackName,audioBean.getAlbumTitle());
count++;
System.out.println("还剩"+(trackTotalCount-count)+"条");
}
}
}
在这里,我设置了线程休眠时间为100ms。
3.增加了windows目录特殊字符替换
/**
* 特殊字符处理
* @time 2019年12月29日14:26:32
* @param fileName
* @return
*/
private static String dealFileName(String fileName){
////:*?<>|
String regEx="[////:*?<>|]";
fileName = fileName.replaceAll(regEx,"");
return fileName;
}
| 因为windows目录中不允许出现///:*?<> | 这些字符,因此将这些字符替换成空字符。 |
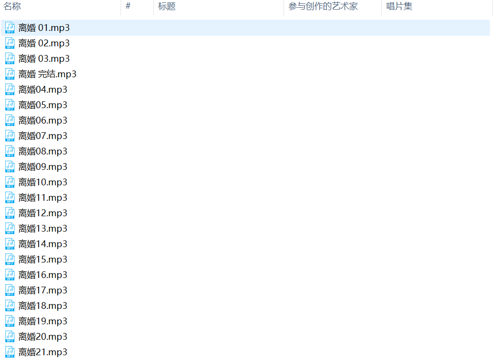
效果


总结
- 代码要时常维护
- 有了好的想法,可以不断迭代,例如将这个程序做成图形化界面
- 多线程写死的四个线程,应该设计成可配置的,获取是智能控制线程的个数
- 每一个小的项目都有很多的点可以优化,希望可以帮助到大家
欢迎关注我的微信公众号: 一辈子的码农先生 ,接下来会有非常多的干货总结,这也是我对自己几年工作的一种总结和交代。谢谢大家!

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

