Flink进阶教程:数据类型和序列化机制简介
几乎所有的大数据框架都要面临分布式计算、数据传输和持久化问题。数据传输过程前后要进行数据的序列化和反序列化:序列化就是将一个内存对象转换成二进制串,形成网络传输或者持久化的数据流。反序列化将二进制串转换为内存对象,这样就可以直接在编程语言中读写和操作这个对象。一种最简单的序列化方法就是将复杂数据结构转化成JSON格式。序列化和反序列化是很多大数据框架必须考虑的问题,在Java和大数据生态圈中,已有不少序列化工具,比如Java自带的序列化工具、Kryo等。一些RPC框架也提供序列化功能,比如最初用于Hadoop的Apache Avro、Facebook开发的Apache Thrift和Google开发的Protobuf,这些工具在速度和压缩比等方面与JSON相比有一定的优势。
但是Flink依然选择了重新开发了自己的序列化框架,因为序列化和反序列化将关乎整个流处理框架个方便的性能,对数据类型了解越多,可以更早地完成数据类型检查,节省数据存储空间。

Flink支持的数据类型

Flink支持上图所示的几种数据类型:原生类型、数组、符合类型、辅助类型。其中,Kryo是最后的备选方案,如果能够优化,尽量不要使用Kryo,否则会有大量的性能损失。
基础类型
所有Java和Scala基础数据类型,诸如Int、Double、Long(包括Java原生类型int和装箱后的类型Integer)、String,以及Date、BigDecimal和BigInteger。
数组
基础类型或其他对象类型组成的数组,如 String[] 。
复合类型
Scala case class
Scala case class是Scala的特色,用这种方式定义一个数据结构非常简洁。例如股票价格的数据结构:
case class StockPrice(symbol: String, timestamp: Long, price: Double) 复制代码
这样定义的数据结构,所有的子字段都是 public ,可以直接读取。另外,我们可以不用 new 即可获取一个新的对象。
val stock = StockPrice("0001", 0L, 121)
println(stock.symbol)
复制代码
Java POJO
Java的话,需要定义POJO类,定义POJO类有一些注意事项:
- 该类必须用
public修饰。 - 该类必须有一个
public的无参数的构造函数。 - 该类的所有非静态(non-static)、非瞬态(non-transient)字段必须是
public,如果字段不是public则必须有标准的getter和setter方法,比如对于字段A a有A getA()和setA(A a)。 - 所有子字段也必须是Flink支持的数据类型。
下面三个例子中,只有第一个是POJO,其他两个都不是POJO,非POJO类将使用Kryo序列化工具。
public class StockPrice {
public String symbol;
public Long timestamp;
public Double price;
public StockPrice() {}
public StockPrice(String symbol, Long timestamp, Double price){
this.symbol = symbol;
this.timestamp = timestamp;
this.price = price;
}
}
// NOT POJO
public class StockPrice1 {
// LOGGER 无getter和setter
private Logger LOGGER = LoggerFactory.getLogger(StockPrice1.class);
public String symbol;
public Long timestamp;
public Double price;
public StockPrice1() {}
public StockPrice1(String symbol, Long timestamp, Double price){
this.symbol = symbol;
this.timestamp = timestamp;
this.price = price;
}
}
// NOT POJO
public class StockPrice2 {
public String symbol;
public Long timestamp;
public Double price;
// 缺少无参数构造函数
public StockPrice2(String symbol, Long timestamp, Double price){
this.symbol = symbol;
this.timestamp = timestamp;
this.price = price;
}
}
复制代码
如果不确定是否是POJO,可以使用下面的代码检查:
System.out.println(TypeInformation.of(StockPrice.class).createSerializer(new ExecutionConfig())); 复制代码
结果显示这个类在是否在使用 KryoSerializer 。
此外,使用Avro生成的类可以被Flink识别为POJO。
Tuple
Tuple可被翻译为元组,比如我们可以将之前的股票价格抽象为一个三元组。Scala用括号来定义元组,比如一个三元组: (String, Long, Double) 。访问元组中的元素时,要使用下划线。需要注意的是,与其他地方从0开始计数不同,这里是从1开始计数,_1为元组中的第一个元素。
// Scala Tuple Example
def main(args: Array[String]): Unit = {
val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream: DataStream[(String, Long, Double)] =
senv.fromElements(("0001", 0L, 121.2), ("0002" ,1L, 201.8),
("0003", 2L, 10.3), ("0004", 3L, 99.6))
dataStream.filter(item => item._3 > 100)
senv.execute("scala tuple")
}
复制代码
Flink为Java专门准备了元组类型,比如3元组为 Tuple3 ,最多支持到25元组。访问元组中的元素时,要使用 Tuple 类准备好的公共字段: f0 、 f1 ...或者使用 getField(int pos) 方法,并注意进行类型转换。注意,这里是从0开始计数。
// Java Tuple Example
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple3<String, Long, Double>> dataStream = senv.fromElements(
Tuple3.of("0001", 0L, 121.2),
Tuple3.of("0002" ,1L, 201.8),
Tuple3.of("0003", 2L, 10.3),
Tuple3.of("0004", 3L, 99.6)
);
dataStream.filter(item -> item.f2 > 100).print();
dataStream.filter(item -> ((Double)item.getField(2) > 100)).print();
senv.execute("java tuple");
}
复制代码
Scala的Tuple中所有元素都不可变,Java的Tuple中的元素是可以被更改和赋值的,因此在Java中使用Tuple可以充分利用这一特性,这样可以减少垃圾回收的压力。
Double price = stock.getField(2); stock.setField(70, 2); 复制代码
辅助类型
Flink还支持Java的 ArrayList 、 HashMap 和 Enum ,Scala的 Either 和 Option 。
泛型和其他类型
当以上任何一个类型均不满足时,Flink认为该数据结构是一种泛型(GenericType),使用Kryo来进行序列化和反序列化。但Kryo在有些流处理场景效率非常低,有可能造成流数据的积压。我们可以使用 senv.getConfig.disableGenericTypes() 来禁用Kryo,禁用后,Flink遇到无法处理的数据类型将抛出异常,这种方法对于调试非常有效。
TypeInformation
以上如此多的类型,在Flink中,统一使用 TypeInformation 类表示。比如,POJO在Flink内部使用 PojoTypeInfo 来表示, PojoTypeInfo 继承自 CompositeType , CompositeType 继承自 TypeInformation 。下图展示了 TypeInformation 的继承关系,可以看到,前面提到的诸多数据类型,在Flink中都有对应的类型。 TypeInformation 的一个重要的功能就是创建 TypeSerializer 序列化器,为该类型的数据做序列化。每种类型都有一个对应的序列化器来进行序列化。
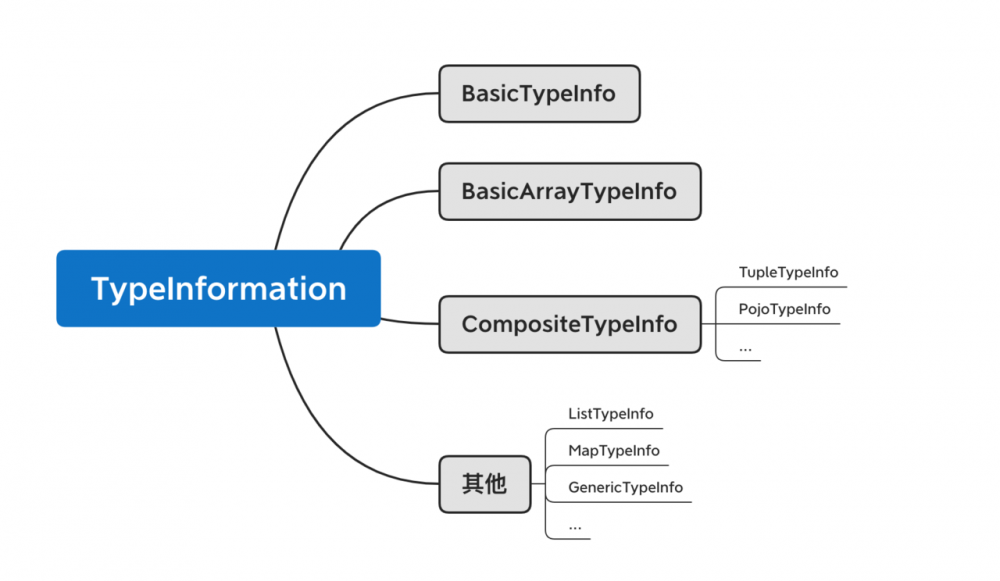
使用前面介绍的各类数据类型时,Flink会自动探测传入的数据类型,生成对应的 TypeInformation ,调用对应的序列化器,因此用户其实无需关心类型推测。比如,Flink的 map 函数Scala签名为: def map[R: TypeInformation](fun: T => R): DataStream[R] ,传入 map 的数据类型是T,生成的数据类型是R,Flink会推测T和R的数据类型,并使用对应的序列化器进行序列化。
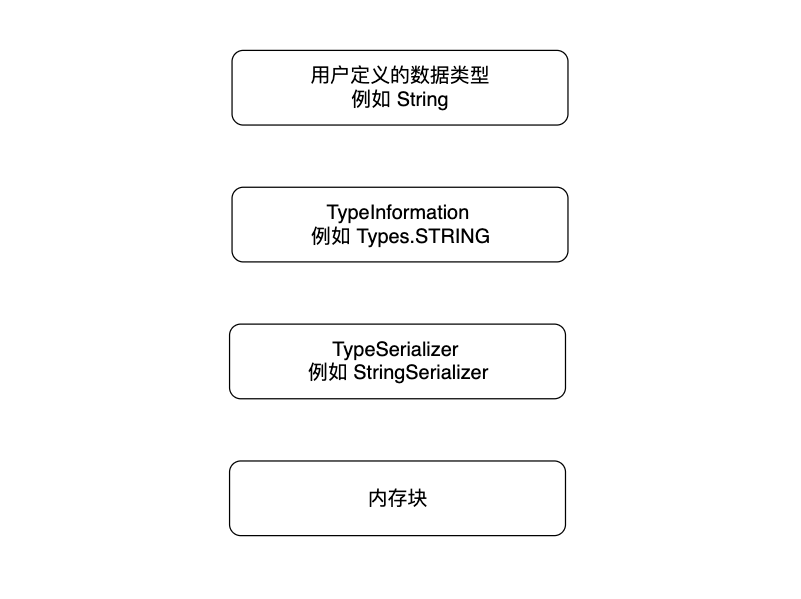
上图展示了Flink的类型推断和序列化过程,以一个字符串 String 类型为例,Flink首先推断出该类型,并生成对应的 TypeInformation ,然后在序列化时调用对应的序列化器,将一个内存对象写入内存块。
注册类
如果传递给Flink算子的数据类型是父类,实际运行过程中使用的是子类,子类中有一些父类没有的数据结构和特性,将子类注册可以提高性能。在执行环境上调用 env.registerType(clazz) 来注册类。 registerType 方法的源码如下所示,其中 TypeExtractor 对数据类型进行推断,如果传入的类型是POJO,则可以被Flink识别和注册,否则将使用Kryo。
// Flink registerType java源码
public void registerType(Class<?> type) {
if (type == null) {
throw new NullPointerException("Cannot register null type class.");
}
TypeInformation<?> typeInfo = TypeExtractor.createTypeInfo(type);
if (typeInfo instanceof PojoTypeInfo) {
config.registerPojoType(type);
} else {
config.registerKryoType(type);
}
}
复制代码
注册序列化器
如果数据类型不是Flink支持的上述类型,需要对数据类型和序列化器进行注册,以便Flink能够对该数据类型进行序列化。
// Java代码 // 使用对TestClassSerializer对TestClass进行序列化 env.registerTypeWithKryoSerializer(TestClass.class, new TestClassSerializer()); 复制代码
其中 TestClassSerializer 要继承 com.esotericsoftware.kryo.Serializer 。
static class TestClassSerializer extends Serializer<TestClass> implements Serializable {
private static final long serialVersionUID = -3585880741695717533L;
@Override
public void write(Kryo kryo, Output output, TestClass testClass) {
...
}
@Override
public TestClass read(Kryo kryo, Input input, Class<TestClass> aClass) {
...
}
}
复制代码
相应的包需要添加到pom中:
<dependency> <groupId>com.esotericsoftware.kryo</groupId> <artifactId>kryo</artifactId> <version>2.24.0</version> </dependency> 复制代码
对于Apache Thrift和Protobuf的用户,已经有人将序列化器编写好,我们可以直接拿来使用:
// Google Protobuf env.getConfig().registerTypeWithKryoSerializer(MyCustomType.class, ProtobufSerializer.class); // Apache Thrift env.getConfig().addDefaultKryoSerializer(MyCustomType.class, TBaseSerializer.class); 复制代码
Google Protobuf的pom:
<dependency> <groupId>com.twitter</groupId> <artifactId>chill-protobuf</artifactId> <version>0.7.6</version> <exclusions> <exclusion> <groupId>com.esotericsoftware.kryo</groupId> <artifactId>kryo</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>3.7.0</version> </dependency> 复制代码
Apache Thrift的pom:
<dependency> <groupId>com.twitter</groupId> <artifactId>chill-thrift</artifactId> <version>0.7.6</version> <exclusions> <exclusion> <groupId>com.esotericsoftware.kryo</groupId> <artifactId>kryo</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.thrift</groupId> <artifactId>libthrift</artifactId> <version>0.11.0</version> <exclusions> <exclusion> <groupId>javax.servlet</groupId> <artifactId>servlet-api</artifactId> </exclusion> <exclusion> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> </exclusion> </exclusions> </dependency> 复制代码
正文到此结束
- 本文标签: list http 分布式 apache 大数据 json src id java js Facebook CTO lib 垃圾回收 tk https IDE CEO client IO BigInteger servlet 数据 空间 example ORM stream pom 调试 代码 final Twitter zab Hadoop UI 开发 scala ArrayList 源码 map Google 参数 ACE HashMap 翻译 压力 API
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

