一文说透去中心化存储架构及 BitTorrent 与 IPFS 等代表项目
从去中心化存储的背景与价值主张谈起,分析 BitTorrent、IPFS 和 Lambda 等偏向基于内容寻址的文件共享网络,以及 Sia、Storj、MaidSafe 等偏向电子网盘的项目。
原文标题:《万字讲透去中心化存储》
作者:陈艺鑫
去中心化存储是一种通过分布式存储技术将文件或文件集分片存储在不同供应方提供的磁盘空间上的存储商业模式。它主张强隐私保护、低存储成本、数据冗余备份存储、高速等价值主张、开源的应用程序和算法,只有全部实现以上主张才可能大范围代替中心化存储。它有利于规避单点故障和数据的价值传递。
去中心化存储的架构自下而上依次为 TCP/IP 协议、区块链、去中心化存储协议和应用层。其中,TCP/IP 协议对应 Layer 0 的网络层,包括网络拓扑结构以及交易的传播机制;区块链属于 Layer 1,它自下而上分别为加密基础设施(一般为 SHA-256 等算法)、存储证明机制(共识机制);去中心化存储协议(服务层)包括存储协议(链上)、检索协议(链下)、身份协议(链上)、内容分发协议、激励协议等,包括 Layer 1 的激励分配机制和 Layer 2 的智能合约与脚本文件;最上层则是应用层,包括客户端软件和加速软件等。
去中心化存储与中心化存储在存储空间来源、带宽来源、安全性、使用方式、行业发展状态等多个维度存在差异,导致其规模和性能远远不如中心化存储系统。虽然 IPFS 等项目通过不同的「非中心化」设计方式弥补了其不同的缺陷,通过对上传方和存储节点给予代币激励的方式使全网存储总规模扩大,但是项目方与用户的利益不一致、费用结构的劣势等方面因素使去中心化存储的发展陷入瓶颈和停滞。本文结合实际情况,对去中心化存储实现其价值主张提供了参考建议。

1 去中心化存储背景与价值主张
1.1. 去中心化存储产生的背景
WEB 3.0 提倡「以数据为中心,数据价值化和隐私保护」,而去中心化存储在其中扮演着至关重要的角色,其中数据安全和隐私保护对应数据冗余存储和备份功能,而数据价值化对应的是文件共享的价值传递。 数据安全方面,相比较于个人,企业往往更加重视公司数据的安全和隐私保护。 企业存储在云端的数据往往是公司的机密,很多数据一旦被泄露很可能将公司在市场竞争上至于不利的地位,传统的公司资料实物存储方法对于大型企业来说早已不足以支撑海量数据存储的需求; 数据价值共享方面,越来越多的人希望共享资源的同时获得相应的交换价值。 比如人大经济论坛和喜马拉雅等平台在共享知识学习和文件的时候需要通过法币或积分的形式换取,而百度网盘和迅雷大多数则是以免费的形式进行价值传递,它们仅仅只是对下载速度等性能收取会员费,而共享内容的种子方并没有获得因共享文件而获得的价值。
近几年来,全球和国内云存储市场发展迅速,从 GB 级别到 TB 级别再上升到 PB 级别,文件存储的种类越来越多,文件的数据量也越来越大。
图表 1:全球云存储和国内云存储市场迅猛发展
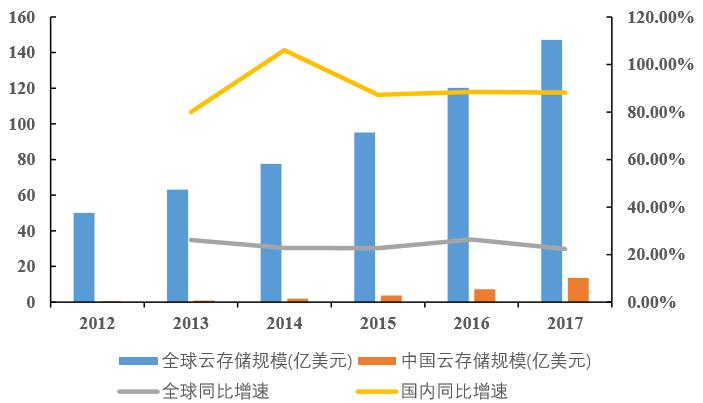 数据来源:中国产业信息研究
数据来源:中国产业信息研究
2012-2017 年,全球云存储市场维持 20% 以上的高复合增速,而国内云存储市场的增速维持在 85%-110%。根据多家机构的预测结果,预计 2022 年全球云存储市场规模将达到 1000 亿美元以上。
虽然云存储市场的规模和用户在飞速增长,但是中心化存储市场却具有四大缺陷: 无法保障版权、无法保障数据安全、随时面临服务商停止运营的风险、数据缺乏价值化。
不论是由亚马逊等公司的第三方中心化存储,抑或者是公司本身存储用户的数据,从法律角度上用户对他们泄露数据信息不具有期待可能性。尤其是在数据为王的商业模式时代,精准数据将对各行各业的重构,控制数据来源或者以比竞争对手更低的成本获取数据的企业,其竞争实力将会显著高于其竞争对手。所以,竞争对手往往会想方设法的获取数据,而将用户数据泄露或出售的行为往往可以让数据存储服务商获得巨大的利益。
用户数据被收集后,中心化的存储使用户数据暴露在巨大的风险之下(泄露、黑客攻击等)。CSO 统计了自 2000 年以来最重大的 18 起用户数据泄露事件,尤其是最近两年,而且数据泄露量级也在呈指数级上升,不论是黑客攻击等外因,还是中心化存储方恶意的内因。例如,印度 10 亿公民身份数据库 Aadhaar 被曝遭受网络攻击事件、Facebook 剑桥分析公司事件等。
图表 2:21 世纪 18 起重大用户数据泄露事件
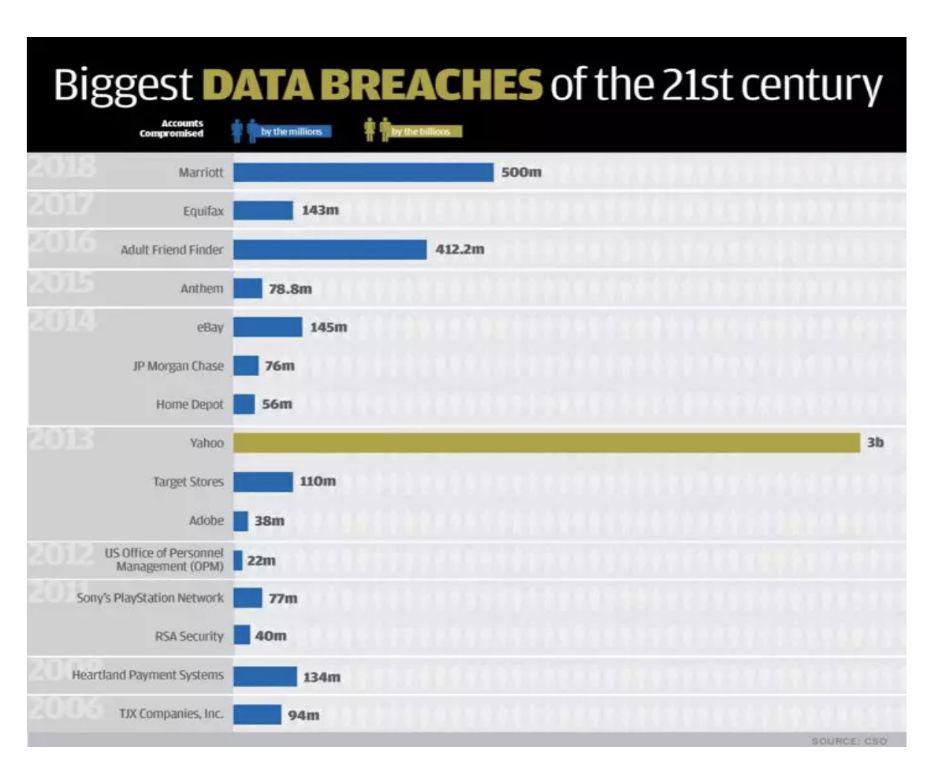 数据来源:CSO
数据来源:CSO
由此,去中心化存储的商业模式就应运而生了。
去中心化存储基于区块链技术,通过非中心化的架构结合中心化与去中心化各自的优势在效益与公平之间探索平衡点,使存储的安全性提升;同时,通过区块链外存储和 API 接口的中心化处理,使得存储网络的 TPS 在现有公有链和联盟链的基础上得到大幅改善;并且,通过对种子节点或文件上传方实施激励措施,让其数据价值化。
1.2. 去中心化存储定义的内涵与外延
存储市场的商业组织形式可以分为中心化存储和去中心化存储。中心化存储是将数据完整的存储在中心化机构开发的服务器上,去中心化存储则是将数据切片分散存储在多个独立的存储供应商上。 二者的技术实现方式通常会以分布式存储来体现。分布式存储是一种数据存储技术,它是将数据分散的存储于多台独立的机器设备上,通过纠删码(Erasure Encoding)技术实现数据的冗余存储。 分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,解决了传统集中式存储系统中单存储服务器的瓶颈问题,并提高了系统的可靠性、可用性和扩展性。
需要注意的是,分布式存储仅仅是一种存储的技术方式,而中心化或去中心化存储是存储的商业模式。因为设备服务器与存储供应者是一对多的关系,即一个存储供应商可以控制多个存储节点,所以去中心化存储一定会使用分布式存储技术;但是,中心化存储可以使用分布式存储技术,也可以不使用分布式存储技术。
图表 3:分布式存储技术在去中心化存储和中心化存储的体现
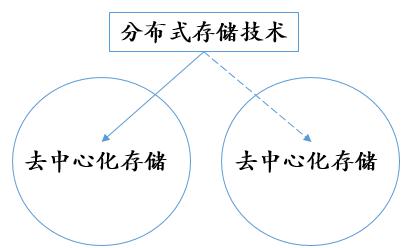 注:实线箭头表示「一定会用分布式存储技术」,虚线箭头表示「不一定会用分布式存储技术」,数据来源:HashKey Hub
注:实线箭头表示「一定会用分布式存储技术」,虚线箭头表示「不一定会用分布式存储技术」,数据来源:HashKey Hub
1.3. 去中心化存储的价值主张
去中心化存储代表着大规模存储的效率和经济的根本转变,它的价值主张主要体现在以下几个方面:
(1)增强安全性和用户隐私。去中心化存储对数据的加密处理不仅仅局限于用户和软件终端,而且在存储网络所有环节上都在进行加密处理,并通过私有网络访问密钥、零知识证明等方法保护用户隐私。
(2)存储平台或网络的算法和代码必须是开源的。由于 2C 端的存储服务已经被中心化存储抢占了大多数市场,由于在开源项目初期进入门槛较高,大多数集中于 2B 端,只有代码开源才能让社区和应用的完善形成有效的正反馈效应。如果算法和代码不公开透明,则存储网络就会变相的中心化。
(3)通过冗余备份防止数据丢失。数据存储于不同的节点,通过数据冗余防止数据丢失(在数据存储或传输出错时存储额外的副本)。
2 去中心化存储系统的架构与运行
2.1. 去中心化存储的工作原理
在文件共享方式上,去中心化存储系统文件共享方式与中心化存储截然不同,中心化存储系统的大型文件上传后,文件以整体或切片的形式存储在单一或分布式的网络或服务器上,需要及其高效的开发、运营团队来维持其运转。然而,去中心化存储必须使用分布式存储技术,初始种子节点(最初拥有完整文件资源的节点)在将大型文件进行切片处理后,使其产生多个 Pieces,每个 Piece 分别存储在不同的节点上,每个一般节点在下载单个 Piece 并上传到去中心化存储网络中让其他节点下载后成为这个 Piece 的种子节点,在多个节点完成相互共享 Piece 的过程中,实现 Piece 在除初始种子节点之外的节点共享,并不断扩大该文件共享网络中的节点数。 所以,在同一时刻其他条件不变时,随着下载人数的增多,下载同一内容的速度越快。因此,去中心化存储系统弥补了中心化存储系统传输速度慢的缺陷,同时克服了单点故障并保证了数据的安全性。
图表 4:去中心化存储工作原理
 数据来源:HaskKey Hub
数据来源:HaskKey Hub
2.2. 去中心化存储的架构
去中心化存储架构自下而上有 4 个组成部分:网络协议(TCP/IP)、区块链或分布式账本、去中心化存储协议和应用程序。其中,网络协议对应的是 Layer 0;区块链或分布式账本对应的是 Layer 1 的底层加密和共识机制;去中心化存储协议对应的是 Layer 1 的激励机制设计和身份协议,以及 Layer 2 对接各类应用程序的智能合约、脚本语言和 API 接口等,直接对接各种服务应用,一般以 API 或者是智能合约的形式呈现;应用程序则对应的是 Layer 2 的应用层 [1]。
图表 5:去中心化存储自下而上的架构层次和对应
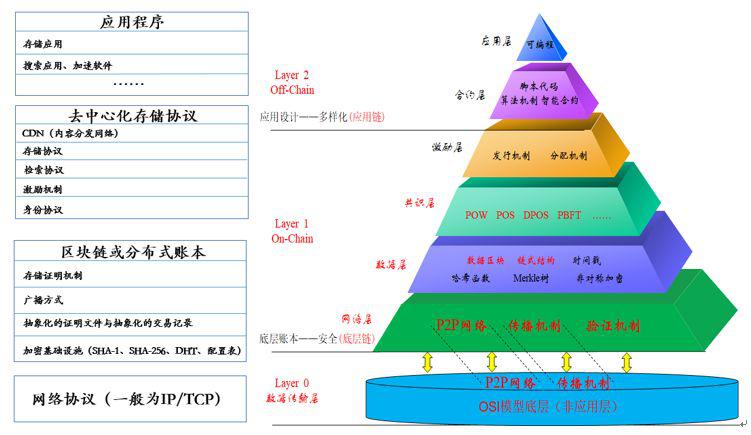 数据来源:HashKey Hub
数据来源:HashKey Hub
2.2.1. 网络协议与网络层
网络协议包括 TCP/IP 的网络协议、存储网络和传播机制。网络拓扑结构的搭建和设计方式往往代表了该系统的价值目标的实现方式,决定了其传播机制和验证机制的运行效率。
存储网络的拓扑结构可以是 P2P 网络,也可以是存在几个联盟的中介服务商或运营商的去中心化网络(本文将此网络拓扑结构定义为非 P2P 网络),但不包括单一或寡头中心化存储服务商构建的基于多个服务器的分布式存储网络。
图表 6:非 P2P 网络和 P2P 网络
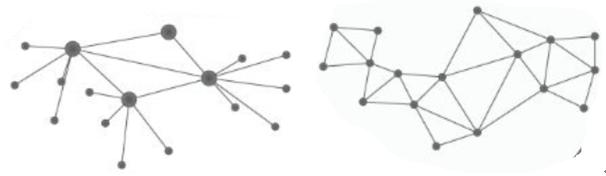 注:左侧为非 P2P 网络,右侧为 P2P 网络,数据来源: https://dwz.cn/6RvaeCgQ
注:左侧为非 P2P 网络,右侧为 P2P 网络,数据来源: https://dwz.cn/6RvaeCgQ
对于 P2P 网络,所有的节点都是对等节点(Peers),它们具有平等的权利和义务,去中心化程度是最高的,也是 BitTorrent、IPFS 和 Storj 等主流去中心化存储项目的网络结构模式,任何节点都可以通过租用和自身的磁盘等硬件为用户节点提供存储空间,也可以通过支付代币或免费的形式将数据分片存储到不同的对等节点上,交易的过程是可逆的,每个节点获得记账权的概率是均等的。 对于非 P2P 去中心化存储网络, 存在部分中介节点,服务器没有充分分散化和边缘化,类似联盟链(许可型区块链)的网络结构,交易信息的传播和沟通必须经过这些中介节点,中介节点与一般节点在权利与义务存在一定的不对等 [2]。
传播机制方面,P2P 网络传播延迟小于非 P2P 网络,并且更容易扩大规模 [3]。假设对同一个内容存在一个非 P2P 共享存储网络(网络 A)和一个 P2P 共享存储网络(网络 B),A 和 B 中均有 100 个节点,其中 A 存在 20 个中介节点,B 存在 100 个对等节点。从主观能动性上来说,因为网络 B 更容易扩大规模,节点上传文件分片(Pieces)的动力强于 A;从客观规律性来说,即便网络 A 和网络 B 的节点数拥有保持在相等的状态,由于存在网络 A 存在中介节点,仅有中介节点充当种子节点的角色,其他 80 个节点就会有搭便车(只下载资源不上传资源)的行为,完全起不到作用,从而导致网络传播延迟大于网络 B。
验证机制方面,P2P 网络的验证动力明显强于非 P2P 网络。P2P 网络可以通过设置奖励代币的方式,激励大量的节点自发地去验证前面交易的真实性,寻找相应证据来佐证;而非 P2P 网络中,具有足够验证动机的节点仅有少数联盟的中介节点,其他节点因利益分配不均缺乏其他交易真实性的动力。显然,从发动 51% 攻击、女巫攻击或者镜像攻击的难易程度上,P2P 网络显然比非 P2P 网络具有更高的难度。
2.2.2. 区块链或分布式账本
去中心化存储系统的区块链或分布式账本自下而上一般包括加密基础设施、交易记录、广播方式和存储证明机制。
对于加密基础设施,其加密方式一般是通过哈希函数加密,包括 SHA-1、SHA-256 等算法或配置表(Allocation Table)连接到默克尔根,在每个环节对数据加密处理后,再通过分布式哈希表(DHT, Distributed Hash Table)、追踪服务器(Tracker)等方式通过主键(Key——种子文件地址)检索到特定存储内容的共享网络。
对于存储证明机制(PoS, Proof-of-Storage),一般是在不通过下载内容的情况下,证明服务器在特定时刻已经存储了特定下载内容,及其数据的完整性,从而降低恶意节点的舞弊空间。它包括数据持有性证明(PDP, Provable Data Possession)和可恢复数据证明(PoR, Proof-of-Retrievability),但是不同项目针对不同的作恶动机和方式对该共识机制进行了完善。比如 IPFS 通过复制证明(PoRep, Proof-of-Replication)和时空证明(PoSt, Proof-of-Spacetime)两个方式分别遏制了女巫攻击、生成攻击和外源攻击 [4]。
对于交易记录,交易记录一般都是以抽象化的形式加密后记录在链上,交易记录的发生与记录必须在完成存储证明之后,将文件名称、时间戳、文件类别等信息组成区块头并存储在链上。
2.2.3. 去中心化存储协议
去中心化存储协议是整个系统的核心,包括存储协议、检索协议、激励机制和身份协议。其中激励机制和身份协议处于其下层,一般在 Layer 1 (链上);存储协议和检索协议则属于服务层,包含各类智能合约和脚本文件,从而决定了相关应用程序的设计,一般在 Layer 2 (链下)。由于去中心化存储项目的定位不同、进展阶段不同等多方面的因素,导致其去中心化存储协议在不同维度的设计上存在较大差异。
身份协议方面,分为存储用户的身份和节点身份。存储用户的身份一般以去中心化身份(DID, Decentralized Identity)的形成呈现,但是也有 BitTorrent 中心化身份的特例。用户仅仅只在提供最小化满足功能的个人信息的情况下,拥有对自己的身份及其相关数据的控制权、许可权和收益权;节点的身份一般在检索过程中,以哈希字符串的形式存储在链上,通过追踪服务器或哈希表可以有效查询某一特定文件或文件集的种子节点,一般表现形式为 URL。
存储协议方面,协议指出用户节点以支付代币或免费的方式从种子节点下载其感兴趣的文件或文件集,而其对手方节点通过提供存储空间(购买或租用)或带宽资源来赚取代币或获得更高的获得记账权的概率,进而形成一个双向的智能合约或交易订单。首先,文件或文件集需要做切片处理,经过 2.1 节中的流程后,存储磁盘空间由该内容的共享网络(Swarm)中所有的节点提供相关的分片。存储协议中所有的步骤流程均在链上进行,包括订单的生成、共识机制的验证和价值传递等。
检索协议方面,去中心化存储的检索协议一般在链下执行,并由中心化机构进行开发、维护和运营,仅仅只有存在代币经济体系的情况下,其价值传递仍在链上进行,其记录抽象化加密后记录在区块链或分布式账本上。检索方式一般是通过节点身份(URL 形式)对种子节点和共享网络进行检索,通过中心化检索服务器和 DHT (分布式哈希表)的方式使下载者之间连接起来,进行资源检索。而 DHT 是对 Tracker 检索方式的改进,通过 Key (通过检索内容的哈希函数生成的哈希字符串)对特定内容进行检索,并大大提升了检索效率。
图表 7:DHT 检索原理
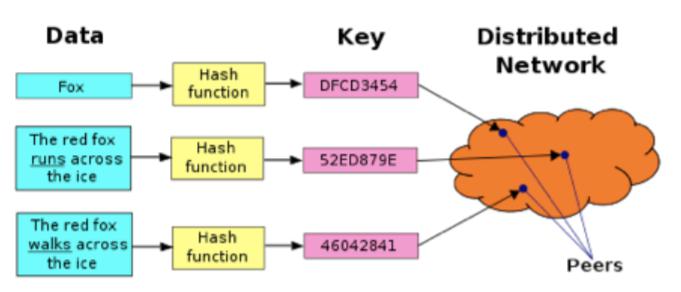 数据来源: https://dwz.cn/hKCgNhEY
数据来源: https://dwz.cn/hKCgNhEY
2.2.4. 应用层
应用层一般包括存储客户端软件(包括存储功能和检索功能)、加速软件和用户代理程序等。通过 SaaS (Software-as-a-Service, 软件即服务)的方式实现盈利,应用软件及其相关基础设施在 Layer 2 (链下)。客户端软件一般与用户进行直接交互,它本质上是一个数据传感器,用来记录用户在存储网络中的行为,评估其转化率、活跃用户数(日活和月活)、搜索记录等,从而为项目未来的发展与经营提供有效参考。通过 DID (去中心化身份)的模式让节点实现数据暴露最小化,使去中心化存储客户端仅仅在实现功能的基础上对用户的存储行为进行画像,而不反映存储和检索功能之外任何的数据信息。
3 去中心化存储与中心化存储的比较
3.1. 比较分析
图表 8:中心化存储 VS 去中心化存储
 数据来源:HashKey Hub
数据来源:HashKey Hub
3.1.1. 存储空间和带宽来源的差异
中心化存储指由单一或寡头第三方机构利用自身搭建的服务器对外提供大规模数据存储服务的商业模式;去中心化存储指大量普通 PC 服务器通过 Internet 互联,对外作为一个整体存储服务。
中心化存储的空间来源是由指定存储服务提供商开发和运营的存储云端,比如 Amazon S3、阿里云和华为云的服务器等,下载的带宽由服务供应商提供;而去中心化存储空间来源是大量能够提供存储空间的 PC、移动终端等设备,同一文件或文件集的共享网络中的所有节点都可以为其下载提供带宽。
3.1.2. 使用方式的差异
由于存储空间的来源不同,进而导致文件存储方式和检索方式截然不同。
存储方面,中心化存储由于存储空间是由中心化存储服务商开发并运营的,因此文件存储空间容量足够大,以至于可以存储海量数据,存储文件(不论是文本、语音还是视频等)整体存入云端,不需要对文件进行切片和去重的处理;去中心化存储由于存储供应者(服务商或个人)相对分散,存储空间也相对分散,需要相应的匹配优化算法在冗余的存储空间中寻找最优的存储空间提供者(即以最快的速度存储并合适的存储空间)。并且为了保证存储数据不会因单点攻击或故障、女巫攻击等外部性因素而丢失,去中心化存储系统在进行加密处理后将文件进行切片处理,并分散存储至不同的存储提供者的磁盘空间中。
内容检索方面,中心化存储以账户范式的形式对已存储数据进行访问,通过输入 HTTP URL 的方式连接到追踪服务器(Tracker),从而实现搜索特定存储内容;去中心化存储因为数据分散存储在不同的节点,所以需要通过 DHT 分布式哈希表将每个节点的链接用哈希函数生成哈希字符串,因此其下载速度随着下载的人数增多而加快。但是也造成了数据的大幅度冗余,很容易造成存储空间资源(如磁盘等)和带宽的浪费。
3.1.3. 安全性和隐私保护的差异
去中心化存储和中心化存储在安全性和隐私保护上具有各有优劣。去中心化存储的优势主要体现在以下两个方面:
一方面,去中心化存储规避了单点故障和部分节点断网或不可用等风险。由于去中心化存储的共享网络为 P2P 网络,而中心化存储的共享网络为以服务供应商为中心的中心化网络,从而导致前者不容易受到单点故障和服务器断网的影响,也不容易受到黑客的攻击。
另一方面,去中心化存储使用户的具体存储内容不因主观原因而泄露。去中心化存储通过零知识证明和非对称加密等技术,将哈希加密的字符串放在区块的最底层,连接到默克尔根,从而将存储内容的分片实现加密处理,其他任何节点包括运营商都无法看到存储的具体内容;而 Amazon S3 等中心化存储系统则通过账号范式,其具体内容服务商都可以看到,从而导致大规模云泄露和云安全事件频发,用户的隐私无法得到有效保障。
但是去中心化存储的劣势也很明显。采用非许可型区块链技术实现去中心化存储模式时,由于出块的全网广播和时间戳技术,导致所有参与节点都知道某一节点在某一特定时刻存储数据,随着节点之间的交互频率提升,全节点可以很容易查找交易发生的区块,从而暴露 Hash 值背后的身份,并用算法推测请求方或存储方的存储余额。再加上分散存储,每个片段如果都一般为 64-512KB,一旦存储网络的大多数存储空间掌握在少数几个存储供应商手中,会比文件整本存储更容易被破解。
3.1.4. 存储费用结构的差异
由于中心化存储系统和去中心化存储系统的存储方式和检索方式的差异,导致二者在服务费用定价上存在差异。
中心化存储系统的收费标准是按月度、季度或年度为单位根据存储数据文件的大小收取存储费用,并且对存储费用实施一定的促销策略(免费试用期等)。比如 Amazon S3 收取存储费用为每月 0.03 美元 /GB;阿里云针对个人和企业采用差异化定价的方式:个人收费为每月 10 元 /GB,企业收费为每月 2.5 元 /GB。
由于大多数去中心化存储网络平台处于项目运营初期,大部分产品处于开发阶段或 MVP 阶段,因此以低廉的存储费用来吸引用户流量。但是,相比较中心化的相对固定的服务费用,除了存储费用之外,去中心化存储还有检索费用、手续费和交易费。因此,去中心化存储仅仅适合冷数据存储,在检索数据量较少的情况下其费用比中心化存储低得多。而对于热数据,因检索频繁导致其成本可能高于中心化存储的费用。对于去中心化存储,因存储共享网络在扩大规模的同时必须伴随着检索热度的增加,而搜索热度的增加必然伴随着检索费用的上升,这在某种程度上是一个难题与挑战。
3.1.5. 可用性的差异
可用性方面,中心化存储在当前状态下具有显著优势。
一方面,中心化存储的文件存储形式采用整本上传,其数据完整性优于去中心化存储。一般来说,可用性的度量维度是客户端直接可用的文件(或文件集)的完整副本数。比如说对于种子节点,因其已上传完整的内容资源,所以其可用性为 1,而对于去中心化存储分片后将不同的 Piece 存储在不同的节点,其共享网络中的单个节点的可用性通常小于 1。
另一方面,中心化存储由一个或寡头的服务供应商运营并维护其共享网络的可持续性,特定共享内容网络的持续期较长。其 HTTP URL 的有效性在上传者不主动删除的情况下,链接将永久有效;而去中心化存储在存储内容可用性的可持续性上比较短暂,主要原因是缺乏有效的激励机制。
3.1.6. 存储文件大小与类型的差异
中心化存储在存储文件大小与类型没有任何限制,不论是视频、音频、文档都可以上传和存储,具有显著优势。
去中心化存储不同项目存在不同的适合存储的文件类型和大小,比如 Storj 定义小文件是 1MB 以下的而大文件是 4MB 以上的。显然文件越大切片的难度也就越高,有些去中心化存储网络只能存储文本文档和图像,有些则可以存储视频和音频,导致市场相对分散。
去中心化存储可减轻数据故障和中断的风险,同时提高对象存储的安全性和私密性。它还使市场力量能够以比任何一家单一提供商都无法承受的更高价格优化价格更低廉的存储。尽管有很多方法可以构建这样的系统,但是任何给定的实现都应该解决一些特定的责任。基于我们在 PB 级存储系统方面的经验,我们引入了一个模块化框架来考虑这些责任并构建我们的分布式存储网络。另外,我们描述了整个框架的初始具体实现。而对于大型文件(一般大于 1GB),在通过哈希加密产生的字符串太多,以至于用户无法记住其哈希字符串,从而导致去中心化存储对用户的接受性减弱。
3.1.7. 下载速度评估方式的差异
去中心化存储和中心化存储在对下载速度评估上存在显著差异。
中心化存储通过中心化的服务器为用户提供带宽进行下载,只要缴纳会员费或者提升会员等级就可以显著提升下载速度,比如用户在使用百度网盘时,在没有会员的情况下下载速度仅为 200KB/s,而在成为会员的情况下下载速度高达 2-5MB/s,而且还会有限速措施;去中心化存储的下载速度取决于其贡献程度,即该节点当前上传内容分片的数量,在其他条件不变的情况下,种子节点的数量越多,下载的人数越多,上传的内容越多,其下载速度越快。同时,对「只下载,不上传」的搭便车节点以限速的形式进行适当的惩罚 [5]。
3.1.8. 发展程度的差异
中心化存储市场占主导,处于成熟期;去中心化存储仍然处于初创期,技术架构和体系尚未成熟。
从行业周期理论角度出发,行业的发展阶段分为初创期、成长期、成熟期和衰退期。存储市场总收入规模达到了 130 亿美元以上,中心化存储 2019 年上半年目前已经形成了寡头垄断的竞争格局,以 Dell Technology、H3C、IBM、联想、华为等巨头为主,并且前 10 家中心化存储公司的市场份额达到 62.9%。
而 Sia、BitTorrent、IPFS 等去中心化存储项目部分仍在开发阶段,而且进度较为缓慢,而开发完成的 Sia 和 Storj 的存储空间总量仅为 2PB,而实际使用空间仅为全网总存储空间的 40% 不到,与中心化存储的收入相去甚远。
图表 9:存储市场份额分布
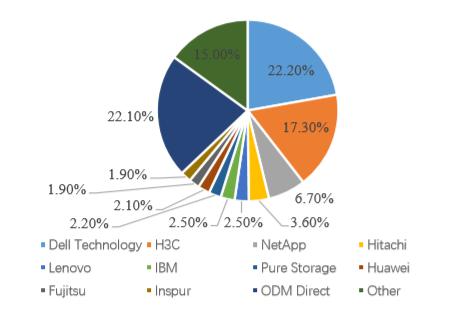 数据来源: http://www.cnbp.net/news/detail/22363
数据来源: http://www.cnbp.net/news/detail/22363
3.2. 去中心化存储的挑战
相比较于中心化存储,去中心化存储虽然在隐私保护和安全性上具有一定的优势,但是在技术、治理、激励机制等方面仍存在诸多不足,比如对于大型文件的用户体验减弱、费用不稳定、激励机制设计上存在规模与效益的矛盾等。因此,未来去中心化存储市场需要引入稳定的费用定价、建立恰当的激励机制等方式来逐步完善,在保持安全性的优势基础上,实现规模与性能的兼顾。接下来将简析现有的去中心化存储项目,并对其优缺点进行相应评价。
4 去中心化存储项目简析
4.1. 代表性项目
目前,已经部署的去中心化存储项目无法从单一的维度进行分类,每个项目都有各自的特点,只能在大致上进行初步划分。
按功能实现的模式划分,以 BitTorrent、IPFS 和 Lambda 为代表的项目更加偏向于基于内容寻址的文件共享网络,而以 Sia、Storj、MaidSafe 为代表的项目则更加偏向于提供电子网盘。
BitTorrent 是最早的去中心化存储项目,但是因其大部分缺乏激励机制,只有少部分引入了 TRON 网络的 BTT 经济,所以作为去中心化存储模式的雏形;IPFS 则是去中心化项目中融资额度最大的,累积融资额高达 2.57 亿美元,通过出块奖励、手续费和服务费等方式激励点对点存储,并通过优化的 Kademelia 算法匹配存储的供应和需求;Lambda 在 IPFS 的基础上引入了 TBB 经济,通过质押 TBB 代币变相地降低了存储矿工的进入壁垒;Storj 和 Sia 更倾向于提供电子网盘,不要求实际存储,只要提供足够的存储空间就可以挖矿;Sia 则是通过内置智能合约的方式为 P2P 存储网络中不同的节点提供协商和沟通的空间。
图表 10:代表性去中心化存储项目比较
 数据来源:HashKey Hub
数据来源:HashKey Hub
4.2. BitTorrent——去中心化存储项目的雏形
(1)项目介绍
BitTorrent 简称 BT,是一种开源的内容分发协议,由布拉姆科恩于 2003 年自主开发 [6]。它采用高效的软件分发系统和点对点技术共享大体积文件(如一部电影或电视节目),并使每个用户像网络重新分配结点那样提供上传服务。常用的应用软件包括 BitTorrent、μTorrent 等。
(2)工作原理
BitTorrent 的工作原理与一般的去中心化存储协议无差异,如上文 2.1 节阐述,将文件进行切片处理,再将每个 Piece 分割成多个大小为 64-512KB 的块,每块生成一个哈希字符串,然后利用 SHA-1 算法加密后分发给该文件或文件集的共享网络(Swarm)中的各个节点。具有完整文件的对等节点为种子节点,其他为非种子节点。然后,共享网络中的所有节点相互传输文件资源,让更多的节点变成种子节点,并且通过 Opitimistic Unchoked 算法选出 2 个共享网络外的节点,以扩大共享网络。
(3)项目架构
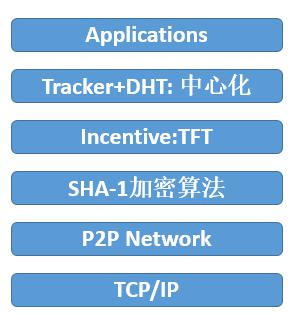
图表 11:BitTorrent 自下而上的架构图
 数据来源:HashKey Hub
数据来源:HashKey Hub
BitTorrent 的架构采用「P2P+中心化」的双层模式进行布置,其中存储共享网络采用 P2P 的模式,而检索协议采用中心化检索模式,其索引文件后缀为」.torrent」。
检索方面,正如本文 2.2.3 节所述,BitTorrent 检索中以加密后的链接为节点的身份,采用哈希分布表对接追踪服务器的模式对特定存储文件或文件集进行有效检索。其中,Torrent 文件包括 Announce 和 info 两个部分组成, Announce 为检索所需的 URL,其数据类型为字符串;info 是一个字典型的数据,其索引包括 Name(内容名称)、Piece Length(每个切片的字节大小 , 除了最后一片,其他等分)、Pieces(利用 SHA-1 哈希加密后的每个 Piece,以便于通过 hash 验证)、length or files(内容是单一文件还是文件集)。
存储方面,通过对特定 Torrent 文件切片后分散存储在不同节点上,在此之前必须通过 Tit-for-Tat(TFT) 的激励机制来筛选该内容共享网络中的节点。BitTorrent 将该内容共享网络中的所有节点分为阻塞节点(Choked)和非阻塞节点(Unchoked),只有非阻塞节点拥有足够的速度或带宽下载或上传该内容,而阻塞节点则无法传输内容。 通过以下三种情况将被判定为阻塞节点:
(a)贡献过少或搭便车过多(只下载不上传)而因此被列入黑名单的节点;
(b)接受节点本身就是种子节点;
(C)存储空间已经满负荷的节点。
在 TFT (Tit-for-Tat)算法配合的激励机制下,一方面根据以上判定方法在该内容的共享网络中确认阻塞节点,共享网络中的其他节点为非阻塞节点,再随机抽样出 2 个共享网络外的节点作为乐观非阻塞节点(Optimistic Unchoking)。 一方面,遏制了该共享网络内节点搭便车(Leech)行为;另一方面,有利于共享网络的扩大。
(4)项目评价
BitTorrent 项目作为最早的分布式存储项目,在激励机制和共享网络上的设计上是比较成功的,并通过免费的模式让其普遍受到用户的青睐,并且通过 P2P 网络实现了下载人数越多速度越快的目标。
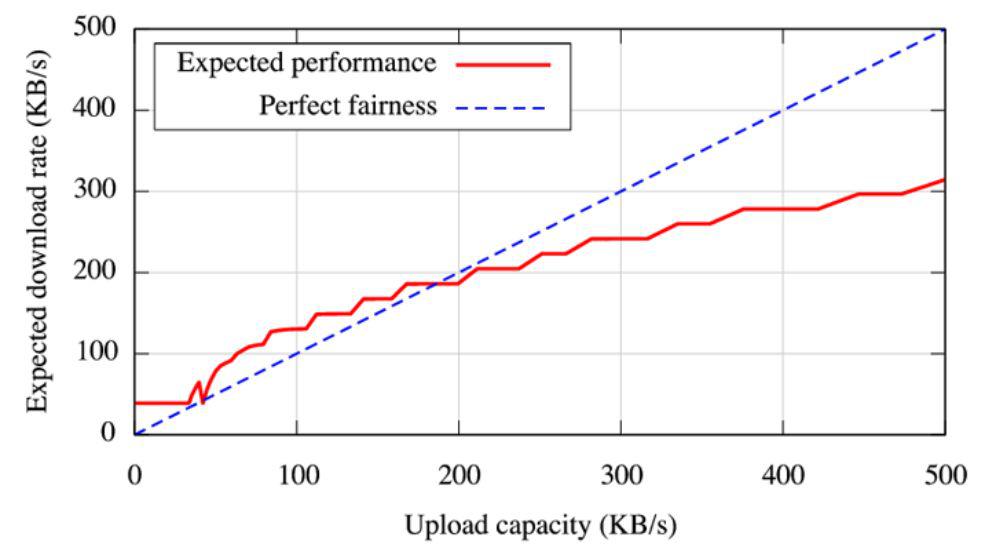
但 BitTorrent 仍存在一定的改进空间。首先,BitTorrent 只能将该激励机制局限在同一内容的共享网络范围之内,而对用户下载后保持内容的可用性方面缺乏有效的激励手段;其次,因 BitTorrent 的协议开源导致盗版猖獗,甚至通过该网络传播暴力、色情等不良内容,从而导致部分重视知识版权的国家(如法国等)全面禁止使用 BitTorrent;再者,BitTorrent 对贡献带宽高的节点不公平,在其他条件不变时,节点贡献的带宽越高,TFT 算法的时延越长,下载速度的边际增长越低 [7]。
图表 12:下载速度随着带宽的提升而边际递减
 数据来源: http://bittorrent.org/bittorrentecon.pdf
数据来源: http://bittorrent.org/bittorrentecon.pdf
4.3. IPFS——融资额度最高的项目
(1)项目介绍
IPFS 本质上是一个底层的开源文件传输协议,旨在对基于 HTTP URL 检索协议进行补充甚至替代,其代币为 Filecoin。虽然 Filecoin 目前尚未正式在交易所上市或者发行,但是 Filecoin 期货早在 2017 年 8 月上线。Filecoin 在上线之初就获得超过 2.5 亿美元的融资,其融资额远超其他去中心化存储项目,目前项目处于开发阶段,Protocol Labs 目前对 Filecoin 激励机制和经济模型的仍在处于开发阶段。
(2)项目架构
图表 13:自下而上的 IPFS 架构
 数据来源:HashKey Hub
数据来源:HashKey Hub
架构最底层为 Libp2p,包括路由层(网络协议)和交换层(P2P 网络),确保数据能够在点对点网络上实现点对点的传输。
上一层为 Multiformat,用于加密数据并将数据抽象成放在链上的格式,它本质上是一个针对未来系统的协议集合,通过增强的自我描述格式(包括自我描述的哈希值、网络地址、编码值、序列化值、网络传输流和分组网络协议来实现互操作性并避免被锁定。
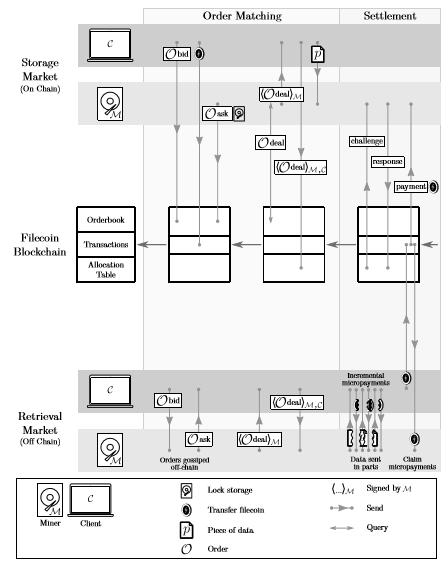
再上一层是 Filecoin 协议作为激励层,该协议包括链上存储市场、链下检索市场和 Filecoin 区块链三部分 [4]。存储市场方面,矿工通过抵押 Filecoin 租用或购买存储空间,接着用户向其发起定向存储请求,并生成 bid (用户)和 ask (矿工)双向订单,并进行 PoRep (复制证明)和 PoSt (时空证明),最后用户获得有效存储(完成两种共识后的存储大小),矿工获得存储费用,注意不论是订单、交易记录还是 Filecoin 的价值转移全部在链上完成。 检索市场方面, 用户先发起检索请求,接着矿工获得检索订单并提供检索服务,最后用户通过支付 Filecoin 获得服务,注意仅有 Filecoin 的价值转移被记录到链下,其他均在链下完成。 Filecoin 区块链方面, 分为订单簿(Orderbook)、交易记录(Transactions)、配置表(Allocation Table)。其中最底层的配置表通过连接到默克尔根对链上信息加密,用于存放双方的数字签名,对矿工发起质询并接受其回复;交易记录用来实现 Filecoin 的价值转移功能;订单簿用来记录存储订单。
图表 14:自下而上的 Filecoin 架构
 数据来源:《Filecoin 白皮书》
数据来源:《Filecoin 白皮书》
IPLD 包括命名层、对象层和文件层,用于定义和查找数据,从而实现文件从命名到编程再到检索的过程。 对于命名层,IPFS 通过 IPNS 使在文件名变更的情况下锁定到其最新状态,它采用自我认证证明的方式,给每个用户分配一个可变的命名空间(路径为 /ipns/),用户可以在此路径下发布一个用自己私钥签名的对象,当其他用户获取对象时可以检测签名与公钥和节点 ID (IPFS 之前生成的链接)是否匹配; 对于对象层, IPFS 使用 Merkle DAG 技术,构建了一个有向无环图数据结构,用于存储对象数据,通常由 Base58 编码的散列引用,该数据结构具有内容可寻址、防篡改、重复数据删除的特点; 对于文件层, 将大于 256KB 的数据文件分割成多个块(每块 256KB),每块的数据类型为 blob 对象,list 对象由几个 blob 对象组成(可能重复),而 Tree 则是一个 json 格式的从名字到哈希值的映射表,由于 Tree 比 blob 小从而便于通过 DHT 进行检索。
(3)项目评价
IPFS 在治理上采用了 PoRep 和 PoSt 的证明有效遏制了女巫攻击、生成攻击和外源攻击等投机行为,并且通过强制购买 GPU 矿机使 PoSt 可以在每隔 45s 可以证明「任意节点是否在该特定时刻已经存储了某一特定大小的文件」,通过默克尔树让每个文件分片(Piece)保留一个根哈希值,大大减少了数据冗余。但是因项目处于初步公测阶段,仍有以下几点值得探讨:
(a) IPFS 的市场非常小众,仅仅是对私存储(因为容量有限),并且由于 GPU 矿机的挖矿成本较高,家庭户无法直接参与到存储挖矿,只能参与检索过程并赚取服务费,仅仅只是对大型规模的矿池或者合伙存储供应商具有较大吸引力,从而不利于全网总存储集中于少数存储供应商或矿池分散化,容易陷入 Filecoin 供过于求的困境;
(b)如果数据量较大(超过 1TB),用户必须记住和保留多个根 Hash 值,从而不利于用户体验,如何控制少数家庭用户的流失率将会成为 IPFS 发展的挑战;
(c)与 BitTorrent 相比,即便 IPFS 初期存储免费,检索费用根据数据热度决定,不提供永久的存储,仅仅只是租用存储空间,高额的存储费用和检索费用以及高投入(GPU 矿机)导致用户门槛巨高;
(d) IPFS 网络没有特定服务器的 P2P 节点,效率有待于进一步加强;
(e)无法充分遏制存储矿工上传大量垃圾数据作为有效存储的行为;
(f) PoRep 共识机制决定了无法进行全网校验,付费存储的方式才可以进行挖矿,如果规模扩大,由于 Filecoin 的出块率等于挖矿节点的有效存储除以全网总存储量,挖矿难度将会大增,无法赚取收益,容易陷入价格战。
4.4. Lambda——基于 IPFS 的延伸
(1)项目介绍
Lambda 是一个区块链数据存储的基础设施,通过对 Lambda Chain 和 Lambda DB 的逻辑解耦和分别实现,通过 Dapp 提供可无限扩展的数据存储能力,并实现了多链数据协同存储、跨链数据管理、数据隐私保护、数据持有性证明、分布式智能计算等服务。
(2)项目架构
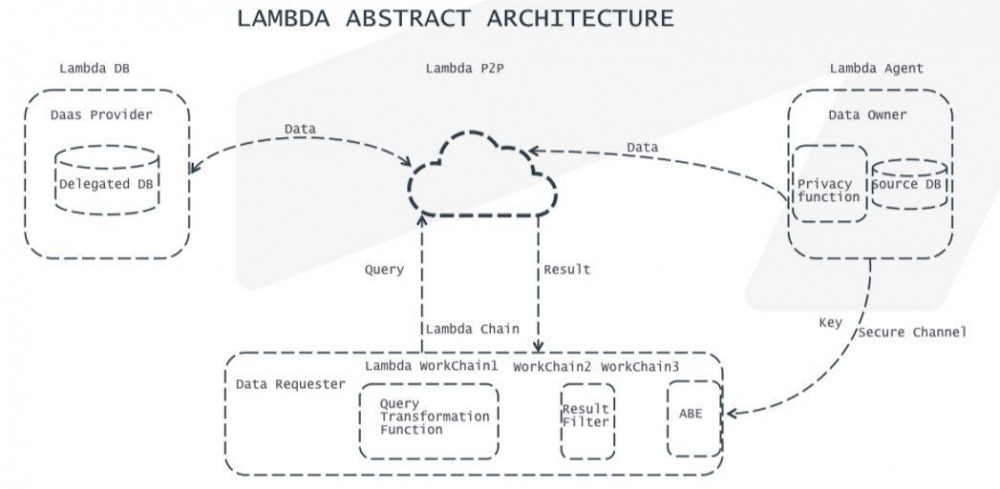
Lambda 包括 Lambda Chain (同构多链的链系统)、Lambda DB (同构多链的链系统)、Lambda Agent (提供内存数据存储、性能监控、安全监控和 Metrics 数据上传能力的探针系统)、Lambda P2P (提供数据检索功能)[8]。Lambda 采用链库分离的架构设计的原因有二:
(a)因为区块链系统更新导致分叉,所以将主要数据处理能力放在数据库(Lambda DB)上;
(b)通过功能子链保证其可扩展性,从而实现隐私保护(基于多授权机构属性加密)和数据持有证明(PDP, Provable Data Possession)。
图表 15:链库分离的 Lambda 架构
 数据来源:《Lambda 白皮书》
数据来源:《Lambda 白皮书》
(3)经济设计
Lambda 项目采用 LAMB 和 TBB 双层代币的方式分别对存储挖矿和质押存储实施激励和惩罚手段。其中,LAMB 是原生代币,用于区块奖励发放,流通、支付交易手续费和生态应用费用结算;TBB 则是存储网络的存储空间资产,主要作用是质押和锚定存储资产权益。
Lambda 网络中主要角色有 5 个:存储矿工(提供存储空间)、验证节点(负责运营和维护共识网络)、存储资产做市商(为存储矿工提供存储资源流通性)、合伙人节点(负责生态建设,不参与存储网络)、出块节点(由验证节点结合质押容量量按照权重选出,负责区块数据的打包以及共识的发起)[9]。
出块奖励有 2 种:对于存储挖矿方面,43% 的出块奖励给矿工及其验证节点;对于质押挖矿方面,50% 的出块奖励给矿工及其验证节点。二者的区块打包收益则根据该验证节点收集投票的多少决定打包区块收益(出块总奖励的 1%-5%),社区收益占总收益的 2%,验证人可以自定义佣金费率。
当验证节点对区块进行双签、对近 10000 个块中少于 500 个签名、质押少于 666.66TBB 时会受到「扣除质押 TBB 和提出验证节点候选人」的惩罚。
(4)项目评价
Lambda 通过非中心化的方式,在存储做市商和数据库上以中心化的形式部署,大大提高了全网的数据吞吐量,使网络未来的可扩展性大大增强。它本质上是 IPFS 项目的延伸与扩展,并且通过引入 TBB 抵押存储机制降低了使用门槛,但是仍然不利于家庭用户参与到存储挖矿。
但是,Lambda 仍有值得商榷的地方。比如 Lambda 通过 NPoS(Nominated Proof-of-Stake) 和 PDP(Provable Data Possession) 的存储证明机制无法证明存储矿工恶意存储大量垃圾数据从而提升其打包概率赚取 LAMB 的行为,一旦验证节点候选人被「黑化」,甚至全网总存储份额无法得到充分稀释,使 51% 攻击的难度较低,大多数挖矿的收益集中于少数人手上,从而导致用户的存储需求和质押需求大幅下降,从而导致 LAMB 逐渐供过于求,导致 LAMB 兑美元大幅下跌和贬值。
4.5. Storj ——基于 ETH 网络的分布式存储协议
(1)项目介绍
Storj 是一个基于以太坊的分布式云存储协议,由盈利性公司 Stroj Labs 开发,旨在利用未使用的硬盘和带宽,让 P2P 网络上任何节点之间都可以进行磋商、数据传输、验证数据完整性和可用性、检索数据、价值传递,存储节点通过提供存储空间收取租金,而其对手方承租磁盘空间支付租金。当前,Storj 全球总存储量已经超过了 150PB,存储费用为每月 0.015 美元 /GB,下载 1GB 所需的带宽费用为 0.05 美元。
(2) Storj 协议架构
Storj 协议包括文件切片处理、Storj 网络、PoR 证明机制、支付协议、广播协议。对于同一内容的共享网络,节点分为存储节点、卫星节点和上连节点 [10]。
存储节点方面,通过出租磁盘和提供带宽而赚取 Storj 代币,如果没有通过随机审查,则该节点会从存储节点池中剔除,它们不为存储数据的初始传输(带宽入口)付费,不为节点发现支付任何费用,有效遏制了存储节点为了更多存储空间而删除原有存储数据的行为(延长内容共享网络的可用性的持续期)。 存储节点将允许管理员在最近 30 天内配置最大的磁盘空间和每个卫星的带宽使用量,在跟踪以上 2 个指标后拒绝没有有效签名的操作。
文件切片和加密方面,对于特定文件集 Bucket,每个文件可以根据特定路径进行检索。对每个文件,首先将其切分成多个 Segments (分片大小由用户自定义),若某个 Segment 小于其元数据的大小,则节省了存储空间,该 Segment 被称为内联 Segment。在通过 AES256-CTR 算法加密后,将加密后的哈希字符串拆分成多个 Stripe,每个 Stripe 执行纠删码编码(通过调整原数据块和校验数据块的比例来提升网络节点的容错能力,使数据安全性提升),将相同索引的纠删码片段拼接组成一个 Piece。最后,将每个 Piece 分发给共享网络中不同的节点,并通过指针实现对不同文件片段的检索。
Storj 网络方面,为了使承租节点和存储节点进行磋商和交互,Storj 将合约和磋商系统建立在 Kademlia 分布式哈希表上,以实现传递所需的确认信息最小化。通过增强核心 Kademlia 功能,传递 Ping (确认节点是否在线)、STORE (在 DHT 上存入哈希值)、FIND_NODE (寻找 DHT 上有存储空间的节点)、FIND_VALUE (寻找 DHT 上的哈希值)四种信息,促进不同节点的交流。首先,如果某个节点要加入某个文件的共享网络,必须先创建一个公钥私钥对,Kademlia 节点的 ID 必须与通过 SHA-256 加密后的公钥哈希字符串一致,因此每个节点的 ID 也是一个有效的比特币地址,在发送信息前必须通过数字签名对信息进行验证。
共识机制方面,Storj 通过「质疑-回复」的形式来实现 PoR (检索证明),确保远程主机确实存储了特定文件分片,并验证文件的完整性和可用性。Storj 采用默克尔根和默克尔树的深度两个指标,通过验证其叶子集合的元素个数是否与默克尔树的深度相等,并且提供的哈希值会重新创建存储的根。通过执行简单的 Tit-for-Tat 模式,如果存储节点未通过审核或无法证明自己仍然有数据,那么承租节点就不必付款;如果租户下线或未能按时付款,则存储节点可以删除数据,并从其他人那里寻找新合同。
图表 16:Storj 文件存储工作原理
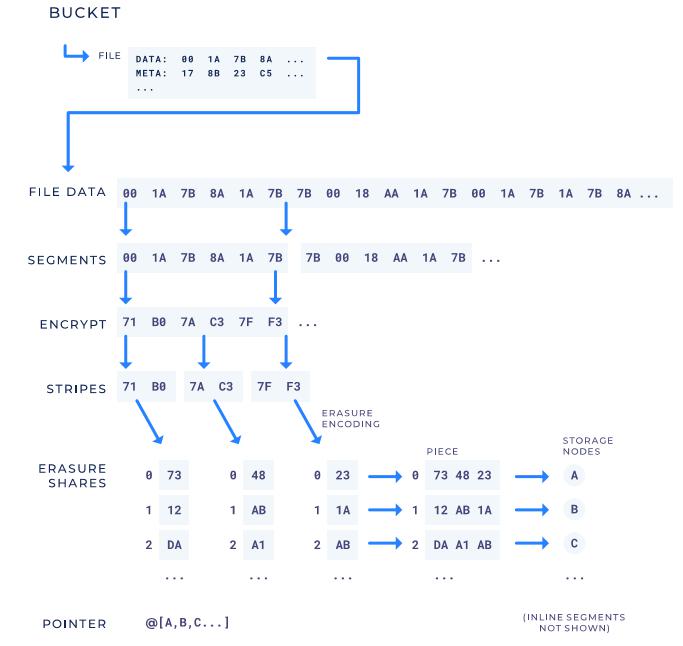 数据来源:《Storj 白皮书》
数据来源:《Storj 白皮书》
图表 17:Stroj 节点分类
 数据来源:HashKey Hub
数据来源:HashKey Hub
(3)项目评价
Storj 在技术上通过 Bridge 客户端实现了对 Amazon S3 等其他存储格式的兼容,并且通过以美元计价的标准避免了存储费用的大幅波动,其存储费用远远低于中心化存储平台,并且通过 Kademlia 算法优化了检索模式,大大减少了数据的冗余和资源浪费。
但是有些地方仍值得商榷。首先,由于 Storjcoin 的波动率较高,从而导致存储节点获得的出块奖励大幅波动,从而无法在长期上保证更多的用户提供更多的存储空间。其次,由于缺乏有效措施延长文件可用性维持的时间,这将不利于共享网络的扩大。再者,随着 Filecoin 加入市场,Storj 不具备显著的竞争优势和资金优势。更重要的是,Storj 本质上只是完成存储资源的对接,缺乏有效的内容寻址方法,不利于文件共享(如电影、音频等),只是适用于大规模数据的存储(如监测数据、交易数据等)。
4.6. Sia——BTC 在去中心化存储的变体应用
(1)项目介绍
Sia 是一个分布式云存储协议,由 Nebulous 公司负责开发与运营,倾向于在 P2P 和 2B 端与现有存储解决方案进行竞争。Sia 支持存储网络的对等节点之间形成合约,为下载特定存储内容定价,旨在让承租节点以更便宜、更快捷的方式租赁到合适的存储空间,通过 Siacoin 经济设计促进承租节点和出租节点双方达成一致。目前,Sia 的存储空间总容量仅为 2PB,已存储的空间仅为 206TB,而存储节点为 333 个,累计下载总量仅为 1.2MB。
(2)项目架构
交易结构方面,Sia 交易包括协议版本号、Arbitrary Data (任意数据字段,以便于数据的检索)、矿工奖励、Inputs (收入资金)、Outputs (支出资金)、文件合约、存储证明、数字签名(所有输入都应当进行数字签名)[11]。Sia 通过在所有交易中使用 M-N 多重签名方案,完全避开了脚本系统,减少了复杂性和攻击可能性。每个区块头的输入必须来自上一个区块头的输出,因此该区块的输入必须是上一个区块头的输出的哈希值,输出包含其 Merkle 根;Siacoin 的支出条件是「时间锁定已经超且足够的指定公钥添加了它们的签名」,签名的数量、公钥组和时间锁定写入 Merkle 树的叶子节点,而该树的默克尔根作为 Siacoin 发送的地址,交易双方可以自主选择披露公钥的数量和签名的数量。
文件合约方面,文件合约是存储节点和其客户之间的存储协议,文件被分片成多个散列在哈希加密后,生成其默克尔根(合约的核心),根散列以及文件的总大小可用于验证存储证据。合约进一步规定持续时间、挑战频率和支付参数( 有效证明的奖励、无效或缺少证据的奖励以及可以错过的最大证明数量 )。其中挑战频率规定提交存储证明的次数,在挑战期间提交一份有效证明将触发转账交易;若没有在持续期内提供有效证明,合约将会发送到「错过证明」地址(有效防止 DDOS 攻击)。支付参数中「可以错过的最大证明数量」为 1 个阈值,如果错过证明数量超过该阈值,合同无效。
存储证明方面,存储证明仅需要合约的身份(哈希值)和证明数据。首先,通过原文件分片存储在默克尔树的叶子节点,生成的哈希根将与之前预先生成的根哈希进行对比,若二者相同,则可证明这些分片确实来源于原文件。Sia 通过让客户端指定很高的挑战频率,并对丢失的证据进行大量处罚,从而阻止低于全网总算力 50% 以下的任何攻击,并遏制私自挖矿的行为。另一方面,由于用户节点有权拒绝任何交易,所以当恶意矿工人为以「是否将存储证明上链」为名来勒索高额交易费时,用户可以直接终止交易。
(3)项目评价
Sia 协议本质上是 BTC 在去中心化存储的一个变体应用,但是其机制设计有些地方仍值得商榷。在 Siacoin 经济方面,Siacoin 的发行数量是递增的,但是其增长率是递减的(初始区块产生 30 万个 Siacoin,之后每产生一个区块减少 1 个 Siacoin,直到减少到 30000 个区块,平均每 10 分钟产生 1 个区块),从而导致随着 Siacoin 数量的增加而带来较大幅度的贬值,从而导致其存储费用波动较大。对于挖矿体系来说,随着 Siacoin 的贬值与滥发,导致算力较强的矿工会产生不成比例的优势,最终挖矿人数将会大幅下降,不利于调动矿工参与的积极性。因此,Sia 不论是从存储规模上还是交易效率上都远远低于 Storj,更不用说和 BitTorrent 相比。
5 去中心化存储未来展望
5.1. 去中心化存储的发展陷入瓶颈或停滞
从严格意义上,去中心化存储并非真正意义上的去中心化,而是非中心化,比如 Filecoin 在存储方面是去中心化的,而在检索方面是中心化的。尽管中心化存储在隐私保护、收费标准、数据安全性方面存在诸多不足,但是去中心化存储由于法律因素以及经济设计等诸多问题,从而导致大多数去中心化存储平台的客户仍然十分小众,提供的存储空间远远小于中心化存储网络,难以满足数据大规模存储和检索的要求,与 1.3 节中提到的去中心化存储的价值主张发生严重背离。以下两点主要原因导致去中心化存储网络难以做大:
(1)存储成本不稳定,费用结构不合理
一方面,去中心化存储网络的存储成本存在较大波动性。比如 Sia、MaidSafe 和 Lambda 等项目因其代币波动较大,而且代币发行机制设计不合理,容易导致代币超发,从而导致其代币价格长期呈下跌趋势,进而导致存储费用和检索费用不稳定,从而导致用户流失率较高。 另一方面,数据检索不是免费的,从而使费用结构不合理。 尽管去中心化存储网络的存储费用远远低于中心化存储,比如 Storj 的存储费用仅为每月 0.015 美元 /GB,远远低于 Amazon 的每月 2.5 美元 /GB,但是如果考虑检索费用或者对数据检索和调用频率的话,那么去中心化存储费用很可能高于中心化存储的成本。
(2)利益多方冲突导致项目方的短期行为严重
为了克服传统非许可型区块链(如 BTC、ETH 和 EOS)等可扩展性不足的缺陷,相当一部分去中心化存储项目采用非中心化的方式,比如 Lambda 在存储资产做市商的中介化与链下的 Lambda DB 和 Filecoin 检索协议的链下处理。 但是,项目方和用户的利益在诸多情况下存在不一致,从而导致项目方的短期行为。 存储网络规模的扩大和交易公平性往往是存在矛盾的,例如 Filecoin 的项目方为了短期扩大全网存储规模而基于有效存储占全网总存储的比例设计挖矿成功的概率,导致用户存储和挖矿的动力减弱,具有高存储空间的节点可以获得比线性增量更高的回报和收益,而项目方本身可能就会扮演具有高存储空间的角色,使去中心化存储项目的价值观出现扭曲。
(3)代币发行通胀率设计陷入两难
去中心化存储网络的商业目标是吸引更多的用户提供更多的存储空间,并且将存储空间的利用率最大化,而实现此目标的前提是保证代币的高流动性并且不让其币值稳定,但是这往往是矛盾的。如果代币发行的通胀率偏低,在未来一定时期内代币的发行量是递减的,很容易造成代币走向升值趋势,存储网络参与者倾向于囤积代币以实现资产增值,从而不利于维持存储市场的高流动性,全网存储总量将会受到抑制;如果代币发行的通胀率偏高,在未来一定时期内代币的发行量是递增的,很容易造成代币兑法币(一般是美元)长期呈贬值趋势,那么矿工的铸币交易产生的收益会大幅缩水,从而导致矿工买入磁盘的投入高于因提供存储空间产生的收益,若买入 GPU 矿机挖矿则更会入不敷出,从而导致进入项目壁垒较高。目前,MaidSafe、Storj、Sia 和 Lambda 等项目陷入了第二种困境。
(4)如何快速稀释全网总存储的集中度
去中心化存储项目在初期,全网总存储将不可避免地集中在少数存储供应商手中,它们大多数以合伙人的身份参与到其中。全网总存储的大规模集中容易发生 51% 攻击,不论攻击方是单个存储供应商还是矿池,甚至是「多方合谋」。导致大多数家庭用户掌握的存储份额越来越低,导致存储区块链从「非许可型」变质成「许可型」,从而导致其代币的需求下降并陷入长期贬值趋势,全网的流动性大幅减弱,甚至大型存储供应商的流失。
5.2. 去中心化存储发展建议
针对 5.1 节的去中心化存储的发展瓶颈,我们对未来去中心化存储项目的布置提供以下参考建议:
(1) 引入稳定币的机制使费用趋于稳定;
(2) 检索应当免费;
(3) 使用 Hash 加密时让区块头上的根哈希值与上一个区块头的根哈希值高度相关,让特定存储内容的共享网络的其他节点有更强的动力去验证其存储文件的完整性和可用性;
(4) 设计合理的共识机制,让出块概率与提高有效存储总量呈线性正相关;
(5) 降低提供存储的进入壁垒,让家庭用户可以以存储矿工的身份参与到存储网络当中,不要让过多的全网总存储集中在少数存储供应商的手上,建议以存储空间的绝对值为度量实施有效奖励,而非比例。
参考文献
[1] 袁煜明 , 刘洋 .《区块链技术可扩展方案分层模型》
[2] 彭俊 . 复杂网络的拓扑结构及传播模型的研究 [D]. 西安 : 西安电子科技大学 .2009
[3] 海沫 , 朱建明 . 区块链网络最优传播路径和激励相结合的传播机制 [J]. 计算机研究与发展 .2019,56(6):1205-1218
[4]《Filecoin 白皮书》: https://filecoin.io/filecoin.pdf
[5] E. Adar and B. A. Huberman. Free riding on gnutella. First Monday, 5(10), 2000
[6]《BitTorrent 白皮书》: https://dwz.cn/dKuhcIRR
[7] Bram Cohen. Incentives Build Robustness in BitTorrent. bram@bitconjurer.org . 2003
[8]《Lambda 技术白皮书》: https://dwz.cn/yktCaGCp
[9]《Lambda 经济白皮书》: https://dwz.cn/ftm1Wl6d
[10]《Storj V3 白皮书》: https://storj.io/storj.pdf
[11]《Sia 白皮书》: https://sia.tech/sia.pdf
来源链接: mp.weixin.qq.com
正文到此结束
- 本文标签: TCP 组织 一对多 企业 运营 kk 希望 web 索引 node 合伙人 密钥 开源项目 时间 list 参数 Uber 统计 免费 工作原理 云 session IBM 标题 NSA 需求 value 快的 Amazon entity 下载 IO bus tab 家庭 cat IDE key DDoS 攻击 src ACE 个人信息 架构设计 认证 2019 js 产品 数据 代码 json 阿里云 开源 lib 删除 ORM 本质 协议 部署 https 资金 黑客 亚马逊 App 软件 百度 dist http Service 模型 服务器 加密 ip 数据库 UI API 智能 数据泄露 锁 build 主机 Action 分布式 备份 lambda mina find 配置 管理 空间 文件上传 开发 回报 ask 黑客攻击 id 探针 Agent db 科技 安全 Facebook
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

