Java并发编程系列-(9) JDK 8/9/10中的并发

9.1 CompletableFuture
CompletableFuture是JDK 8中引入的工具类,实现了Future接口,对以往的FutureTask的功能进行了增强。
手动设置完成状态
CompletableFuture和Future一样,可以作为函数调用的契约,当向CompletableFuture请求数据时,如果数据还没有准备好,请求线程就会等待。但是,我们可以手动设置CompletableFuture的完成状态。
下面的例子中,创建了CompletableFuture对象实例进行计算,同时另外一个线程进行等待,接着,模拟等待一段时间之后,设置完成状态为完成,此时等待线程继续执行。
public class CompletableFutureTest {
public static class waitThread implements Runnable {
CompletableFuture<Integer> resultCompletableFuture = null;
public waitThread(CompletableFuture<Integer> resultCompletableFuture) {
super();
this.resultCompletableFuture = resultCompletableFuture;
}
@Override
public void run() {
int myResult = 0;
try {
System.out.println("Waiting for the result...");
myResult = resultCompletableFuture.get();
System.out.println("Result got, it's " + myResult);
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
final CompletableFuture<Integer> future = new CompletableFuture<Integer>();
new Thread(new waitThread(future)).start();
// 模拟等待过程
Thread.sleep(2000);
// 设置完成的结果
future.complete(666);
}
}
异步执行任务
CompletableFuture提供了很方便的异步执行接口,

其中supplyAsync方法用于需要返回值的场景;runAsync方法用于没有返回值的场景。注意到,这两个方法中都可以接受Executor参数,可以方便的让任务在指定的线程池中运行。

流式调用
CompletableFuture提供了类似于JDK 8中list的流式操作,下面例子中,首先利用supplyAsync()执行一个异步任务,接着使用流式操作对任务结果进行处理。

注意到在最后面,调用了get方法,用于获取结果,否则由于CompletableFuture异步执行,main函数不会等待计算完成,直接退出,随着主线程的结束,所有的Daemon线程也会退出,从而导致计算方法无法正常完成。
异常处理
CompletableFuture在执行中遇到异常时,同样的可以利用函数式编程的方法来处理异常,CompletableFuture中提供了一个异常处理方法exceptionally():

组合多个CompletableFuture
CompletableFuture中可以组合多个CompletableFuture,主要有如下两种方法:
1. thenCompose方法
public <U> CompletableFuture<U> thenCompose(
Function<? super T, ? extends CompletionStage<U>> fn) {
return uniComposeStage(null, fn);
}
例子如下:

2. thenCombine方法
public <U,V> CompletableFuture<V> thenCombine(
CompletionStage<? extends U> other,
BiFunction<? super T,? super U,? extends V> fn) {
return biApplyStage(null, other, fn);
}
例子如下:

支持timeout
在JDK9之后的CompletableFuture增加了timeout功能,如果任务在指定时间内没有完成,则直接抛出异常。

9.2 改进的读写锁:StampedLock
StampedLock是JDK 8中引入的新的锁机制,可以认为是读写锁的一个改进版本,读写锁虽然分离了读和写,使得读与读之间可以完全并发,但是读和写之间仍然是冲突的。读锁会阻塞写锁,它使用的仍然是悲观的策略,如果有大量的读线程,可能引起写线程的饥饿。
stampedLock提供了一种乐观的读策略,这种乐观的策略类似与无锁的操作,使得乐观锁完全不会阻塞写线程。

上面的例子中,首先试图尝试乐观获取锁,方法会返回一个类似于时间戳的stamp,然后进行相应的读取操作,当然为了保证没有其他线程修改了x、y的值,需要调用validate方法来进行验证,判断这个stamp在读过程中是否发生了修改。如果没有修改,则直接进行接下来的计算,否则,升级乐观锁为悲观锁,使用readLock获取读锁。如果当前有其他线程已经获取了锁,当前线程可能被挂起。
9.2 更快的原子类:LongAdder
JDK引入了LongAdder,对之前的atomicInteger的性能进行了增强,AtomicLong 的 Add() 是依赖自旋不断的 CAS 去累加一个 Long 值。如果在竞争激烈的情况下,CAS 操作不断的失败,就会有大量的线程不断的自旋尝试 CAS 会造成 CPU 的极大的消耗。
对于同样的一个 add() 操作,上文说到 AtomicLong 只对一个 Long 值进行 CAS 操作。而 LongAdder 是针对 Cell 数组的某个 Cell 进行 CAS 操作 ,把线程的名字的 hash 值,作为 Cell 数组的下标,然后对 Cell[i] 的 long 进行 CAS 操作。简单粗暴的分散了高并发下的竞争压力。
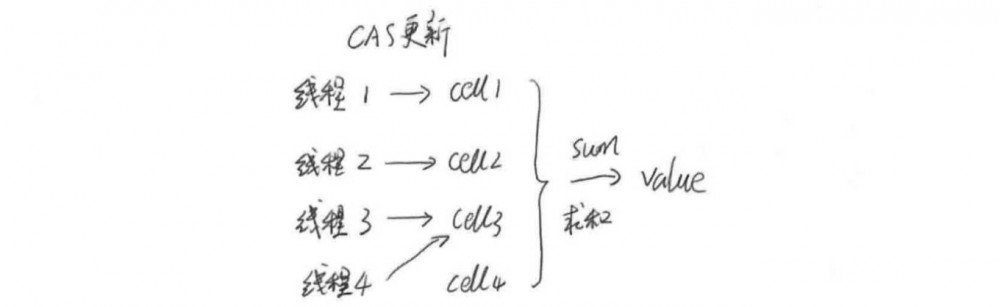
在实际的操作中,LongAdder并不会一开始就动用数组进行处理,而是将所有数据都记录在一个称为base的变量中,如果在多线程的条件下,大家修改base没有冲突,也没有必要扩展成cell数组,但是,一旦base修改发生冲突,就会初始化cell数组,使用新的策略。如果使用cell数组之后,发现在某一个cell上的更新依然存在冲突,那么系统就会尝试创建新的cell,以减少冲突。
AtomicLong可否可以被LongAdder替代?
有了传说中更高效的LongAdder,那AtomicLong可否不使用了呢?当然不是!
答案就在LongAdder的java doc中,从我们翻译的那段可以看出,LongAdder适合的场景是统计求和计数的场景,而且LongAdder基本只提供了add方法,而AtomicLong还具有cas方法(要使用cas,在不直接使用unsafe之外只能借助AtomicXXX了)
LongAdder有啥用?
从java doc中可以看出,其适用于统计计数的场景,例如计算qps这种场景。在高并发场景下,qps这个值会被多个线程频繁更新的,所以LongAdder很适合。
参考:
- https://www.jianshu.com/p/22d38d5c8c2a
- 《实战Java高并发程序设计》
本文由『后端精进之路』原创,首发于博客 http://teckee.github.io/ , 转载请注明出处
搜索『后端精进之路』关注公众号,立刻获取最新文章和 价值2000元的BATJ精品面试课程 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

