线上RPC远程调用频繁超时问题排查,大功臣Arthas
转自:Java艺术
两耳不闻窗外事,一心只读圣贤书。又是一个美好的周末,一觉睡到自然醒,写写文章看看书!这周原计划是写Dubbo注册中心的,但这周先说故事。
上次服务雪崩还是一个月前的事情,虽然上次雪崩事件之后加了熔断器,但这次服务崩溃原因并未达到限流的QPS值。 由于前一次雪崩后做了些参数上的调整,比如取消dubbo重试机制,减小超时时间,添加mock机制等,不至于服务完全瘫痪,但请求平均耗时异常彪升,超出临界值的请求全部处理异常。
项目不断新增需求,难免不会出现问题,特别是近期新增的增加请求处理耗时的需求。 以及一些配置的修改而忽略掉的问题,如dubbo工作线程数调增时,忽略了redis连接池的修改。由于redis可用连接远小于工作线程数,就会出现多个线程竞争redis连接,影响性能。
在发现请求平均耗时超出异常,而并发量却未有异常突增时,查看服务器日记发现日记打印了密密麻麻的远程调用超时异常,看日记就能很清楚的知道是哪个服务哪个接口调用超时。日记内容大致如下,详细信息能够看到调用的类、方法名以及参数。
org.apache.dubbo.remoting.TimeoutException:
Waiting server-side response timeout by scan timer.
对外服务(下文统称服务A)处理终端一次请求的平均耗时在25ms左右,正常情况下并发量突增到服务所能承受的最高点时,最大耗时也在200ms以内,而一次请求中调用某个服务(下文统称服务B)的耗时必然会小于一次请求的处理耗时,所以我把服务A调用服务B的rpc调用超时设置为500ms,避免因调用阻塞等待导致请求堆积问题,所以本次服务崩溃并未看到文件句柄数达上限的异常,也因如此,只会有部分请求处理失败,不止于整个服务完全不可用。
看到请求处理耗时,首先想到的是redis,但通过redis-cli工具排除了redis性能问题。通过SSH连上到服务B的某个节点,也并未发现jedis连接超时或是查询超时异常,暂时排除redis性能问题。最后通过htop命令,发现cpu使用率一直居高不下,根据经验判断,要么程序中出现什么死循环,要么就是代码执行计算任务耗时,非IO操作,比如大量for循环计算。

从日记中已经能定位到服务B的某个接口执行耗时,但接口的实现很复杂。通过过滤器链封装了具体调用逻辑,而过滤器链中大概有六七个过滤器,过滤器链按照注册顺序调用过滤器的filter方法,当某个过滤器返回true时,后面的过滤器就不会执行。
如果项目中加入分布式系统调用链追踪系统,比如Zipkin+Brave+Elasticsearch,那么排查问题就会非常简单,但需要为此花费大日记存储的费用,因此我们项目中并未使用。除此之外,要定位到线上问题,找出哪个方法耗时,或者都有哪些方法比较耗时,就需要借助一些Agent工具,监控或取样每个方法的执行耗时,从而定位到具体的过滤器具体的某个方法,比如Jprofile、 Arthas。
Jprofile对线上高并发服务影响比较大,且需要在本地使用Jprofile应用远程连接。关于Jprofile的介绍以及使用可以查看我的历史文章: 使用Jprofiler远程监控线上服务 。Arthas 在线文档 https://alibaba.github.io/arthas/watch.html 。
在此次问题排除过程中,watch、monitor、trace这三个命令都起了很大的作用。
首先使用 watch 监控服务B对外提供服务(provider)的接口处理耗时,通过' #cost>500 '输出耗时大于500ms的调用日记, -x 指定参数和返回打印的深度,在不关心方法具体参数内容时,也可去掉“ {params,returnObj} ”。
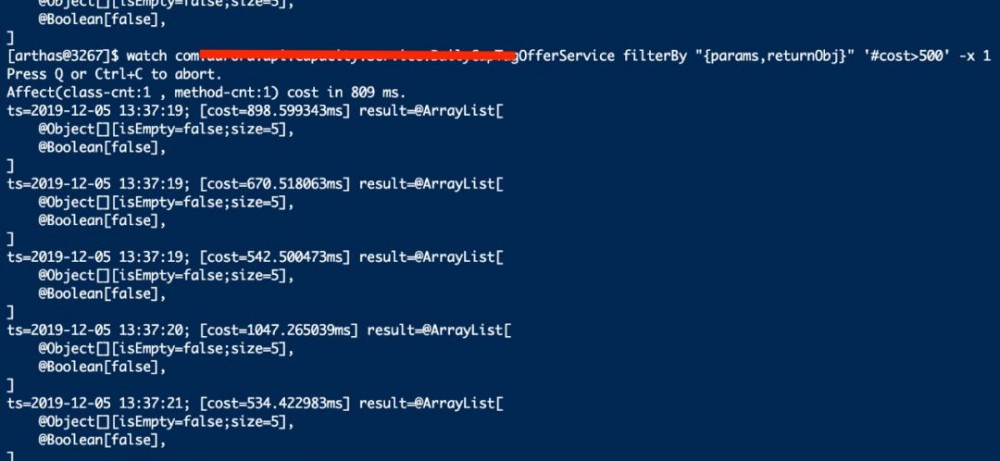
通过 watch 命令发现,服务B暴露给其它服务调用的接口,调用耗时大于500ms的非常多,因此,根据代码层面的理解,大概定位到会出现耗时如此高的过滤器。继续使用 watch 监控具体某个过滤器的过滤方法的耗时。
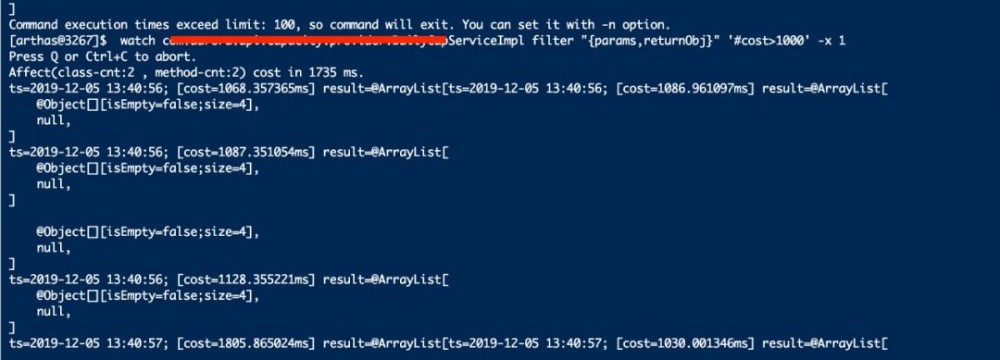
在监控某个过滤器的方法执行耗时上找到了答案。arthas频繁打印记录,单个过滤器的一个过滤方法执行耗时就超过1000ms,将' #cost '降到到500ms后更多。
继续使用 monitor 命令监控某个方法的执行信息,包括执行总数、执行成功次数、异常失败次数、平均耗时、失败率等,通过 -c 1 指定统计周期为1s。
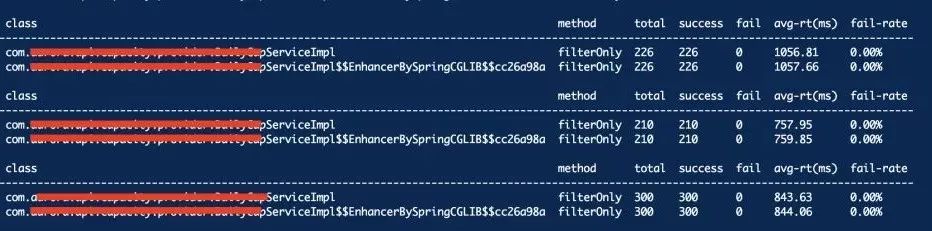
当前服务B配置的Dubbo工作线程池的大小为256,图中接口的平均耗时最大达到1s,图中最大QPS为300,此时CPU使用率接近百分百,假设该服务部署两个节点,以此估算最大QPS为600。
当服务A并发数达到11w每分钟时,三个节点,转为QPS就是每节点每秒处理611个请求,刚好就是服务B的QPS,所以当服务A并发量超过11w/min的阈值时,服务就变得不可用,大量请求得不到处理,平均耗时异常飙升。
由于之前根据每请求耗时最大25ms计算的QPS,设置限流规则,而当前rpc远程调用并未达到限流的条件,远端没有空闲线程能够处理rpc调用,所以consumer端就会收到provider端线程池已满无法处理请求的异常,以及大量的rpc远程调用超时异常。
我们还可以使用Arthas的 trace 命令输出方法调用栈上的每个方法执行耗时。 --skipJDKMethod true 指定跳过jdk的函数调用," #cost>100 "指定只会展示耗时大于100ms的调用路径。

使用 --skipJDKMethod true 跳过jdk方法在此处会有问题。因为我用jdk的List存放过滤器,通过遍历List来顺序调用过滤器链,过滤了jdk方法调用链就断开了。
Dubbo处理远程调用配置使用固定线程池,当所有线程都处于工作状态时,并不会将新请求放入阻塞队列,而是放弃请求,抛出异常。解决方案有三,一是优化代码,如果代码实在优化不了,那就方案二,改用非固定线程池或增加线程数,但200个线程已经让cpu处于百分百的使用率,且增加线程也并不能解决耗时问题,反而耗时会上涨,那么,最后就只剩方法三,横向扩展节点。
此次代码层面的优化包括,使用 zcount 替换redis的 hgetall 优化了业务逻辑,以及以内存换性能,在redis缓存上再加一层内存缓存,内存缓存缓存方法返回结果,在redis数据更新时移除内存记录。优化后,服务B的QPS有了显著的提升,像极了牙膏,挤挤又省几台机器。

上图是我在服务达到同样并发量的条件下,用arthas验证调优后的效果截图。可以看到,请求平均耗时降低了100倍,QPS上去了。 但是,事情并未结束,好戏才刚刚开始。
墨菲定律,每到下班时间准没好事,果然,服务又崩溃了。 但这次内部服务都正常,cpu使用率在正常范围内,各个服务都没有任何异常日记,服务A的rpc远程调用超时问题也不存在了。可 服务A打印的每个请求的处理耗时都超过500ms,明显的非常不正常,于是又是一波Arthas操作。
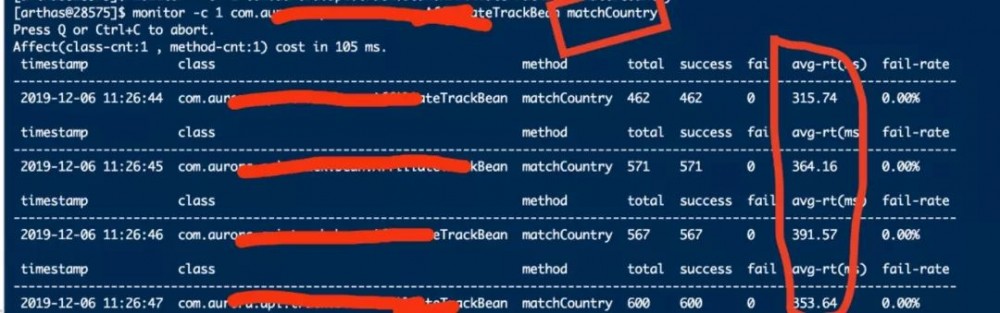
终于找到问题,所以我说,这次Arthas是大功臣。 在调用IP库服务提供的restful接口出了问题,耗时全在这里。最后的优化是 把IP位置信息的查询由调用接口改为直接依赖封装的组件从redis缓存中查,问题得以解决。 关于IP库可看我往期文章: 基于Redis实现范围查询的IP库缓存设计方案 。
我们一直忽略了一个问题,就是并发量上升时,只考虑为接收外部请求的服务A添加节点,却忘了大部分业务逻辑都是由内部的两个服务去处理的,解决内部服务的性能问题才是提高对外服务A的QPS的关键。加节点应该先看各各服务的状态,给最需要加节点的服务添加节点才是重中之重。否者服务A加的节点越多,接收的请求越多,越容易打垮内部服务。
也因此得出,现在我们的服务部署方案是有问题的。太关注对外服务A的处理能力而忽略了内部提供业务支持的服务。但这结论也会随着外部服务不断添加新需求的情况下被推翻,定期检查各服务状态将变得非常有必要。
排查项目性能瓶颈需要考虑到各方面,一是缓存redis的性能瓶颈,二是外部服务性能瓶颈,三是内部各服务的性能瓶颈,最后数据库性能瓶颈。调优包括:业务逻辑优化、代码调优、缓存调优、SQL调优、JVM调优。遇到问题一定要去找到问题的根源,只通过加机器处理问题,问题将会恶化得越来越严重,因为毒瘤一直都在!

正文到此结束
- 本文标签: zip 线程 GitHub 参数 http zipkin Agent ssh 数据库 RESTful REST 统计 高并发 QPS java IDE list src 分布式 缓存 https redis 遍历 lib id 连接池 git 数据 HTML consumer IO JVM 部署 ip UI 时间 provider 线程池 注册中心 并发 服务器 配置 需求 dubbo 文章 分布式系统 重试机制 apache sql 代码 性能问题 ACE Elasticsearch 限流
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

