TaurusDB 挑战赛系列六:优胜奖 wangkai 作品解析

华为云TaurusDB结束有一段时间了,这几天抽时间写一下参赛总结,我是从阿里第三届中间件比赛开始参加类似比赛的,TaurusDB这次是第三次,虽然有过两次参赛经验,但是数据库比赛还是第一次,报名也是无意中看到朋友在朋友圈的分享,正好想要学习一下数据库相关知识,于是报名参加了比赛,熬了无数个夜晚,很幸运最终以第10名的成绩擦边入围,主要还是cpp大佬和其他选手承让。
赛题回顾
比赛分成了初赛和复赛两个部分,初赛要求实现一个简化、高效的本地 kv(为简化开发,K固定大小8B,V固定大小4KB)存储引擎,其中每个KVStore为一个实例,每个线程操作独立的KV实例,线程间互不影响,复赛在初赛的基础上增加了计算存储分离的架构,计算节点需要通过网络传输将数据递交给存储节点存储。
程序主要提供三个接口:
public interface KVStoreRace {
// 用于数据库初始化/崩溃恢复
public boolean init(final String dir, final int thread_num) throws KVSException;
// 用于将数据持久到磁盘
public long set(final String key, final byte[] value) throws KVSException;
// 用于从磁盘读取出来
public long get(final String key, final Ref<byte[]> val) throws KVSException;
}
评测程序分为2个阶段
正确性评测
此阶段评测程序会并发写入随机数据(key 8B、value4KB),写入数据过程中进行任意次进程意外退出测试,引擎需要保证异常中止不影响已经写入的数据正确性。
异常中止后,重启引擎,验证已经写入数据正确性和完整性,并继续写入数据,重复此过程直至数据写入完毕。
只有通过此阶段测试才会进入下一阶段测试。
性能评测
随机写入:16个线程并发随机写入,每个线程使用Set各写400万次随机数据(key 8B、value4KB)。
顺序读取:16个线程并发按照写入顺序逐一读取,每个线程各使用Get读取400万次随机数据。
热点读取:16个线程并发读取,每个线程按照写入顺序热点分区,随机读取400万次数据,读取范围覆盖全部写入数据。热点的逻辑为:按照数据的写入顺序按10MB数据粒度分区,分区逆序推进,在每个10MB数据分区内随机读取,随机读取次数会增加约10%。
评测环境
计算节点:内存占用不得超过4G(CPP), 5G(JAVA),不得写入和读取磁盘空间。
存储节点:内存占用不得超过2G(C++),3G(JAVA),磁盘占用不得超过320G。
注:后台将CPU统一限制为16核。
语言限定
CPP & Java,一起排名
赛题分析
拿到赛题后首先我们对赛题已知条件做下分析:
-
数据总量为4M*16(64M)条数据
Key数据总量为64M*8(B),索引可以完全加载到内存
-
定长Key(8B)和Value(4KB)
极大简化索引构建和写入缓存设计
-
读取分为顺序和逆序遍历(10M内随机)
可以考虑使用LRU作为缓存策略
-
kill -9保证数据不丢
需使用mmap保证数据最终落盘
-
因为我们比系统更了解程序的缓存策略
读写考虑使用DirectIO+自管理缓存
-
计算存储分离
可把存储节点当作一块磁盘对外提供read, write接口,把索引构建及索引查找放到计算节点
-
因为DB是分布式的
应考虑使用大块网络传输来减少rtt带来的性能损耗可以看出此次大赛的核心考察点是计算存储分离,因为计算量不大,存储介质性能又非常强悍,程序的瓶颈可能是在网络层面,如何高效利用网络是本次比赛重点思考内容。
程序设计
1 功能设计
首先要考虑的是功能评测,即保证kill -9数据不丢,因为一个程序只有功能正确才能谈性能,保证kill-9数据不丢有两种方式,第一种是来一条数据写一次盘,每条数据都即时落盘,这个方式虽然可以保证数据不丢,但是性能堪忧,好在操作系统给我们提供了另一种方式mmap(memory mapping),通过mmap可以将文件直接映射到user内存区,user可以直接操作这块内存,程序可以通过主动(force)或者被动(程序结束或崩溃)方式将内存中的数据持久到磁盘,这个过程不经过kernel内存区,省去一次内存拷贝,同时也保证了数据安全。
保证了存储节点数据不丢后下面要考虑在有网络传输的情况下数据不丢,如果允许数据丢失则可以使用异步io方式传输数据,但是要保证数据不丢则计算机点需要一直阻塞直到存储节点数据落盘并返回ack后计算节点set方法才能返回,这样网络模型为PING/PONG模型。
2 文件分布设计
因为程序是多实例数据库,实例之间互不干扰,这里没有对数据进行分片操作,其实换一个角度看我们可以把每个实例看作一个数据库分片,因为分片的目的是为了让分片之间互不干扰,提高程序并行能力,每个实例(分片)内的写操作都比较简单,采用追加写的方式。
每个实例包含3个文件:
MergeIO(mmap): merge io
索引文件(mmap): Key实际存储文件
数据文件: Value实际存储文件

写入Value时先写入MergeIO文件,Merge满后批量写入数据文件,即使程序被kill,也可以从MergeIO文件恢复Value数据。
这里感谢一下徐靖峰(岛风)同学开源的kdio(java操作DirectIO的库)
3 索引设计
数组二分查找: 构建索引时需要排序,单点查询对cpu分支预测不友好,但是方便进行范围
LongIntMap(开放寻址法): 可以动态构建索引,单点查询可快速定位(key冲突量不大时),难以范围查询
因为这里考虑只有单点get没有范围查询,所以用了LongIntMap
4 读取设计
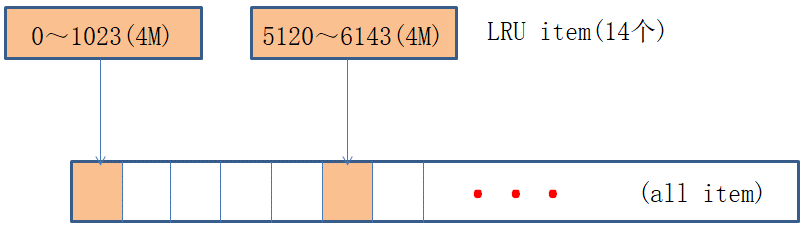
读取采用LRU算法对数据进行缓存读取,每个LRU Item包含4M Value数据(1K个Value,参数可调)每个实例包含14个LRUItem,包含4M(总消息数)/1K个空Item,比如说通过Key找到Index为1,对1取模得到缓存位置0,因为缓存已存在则直接使用item.get(),如果Index为1024,因为缓存不存在,则根据缓存最后访问时间找到需要失效的缓存,通过read方法从存储节点读取该缓存的内容,然后get出结果。
5 网络传输设计
存储节点: 存储节点采用Epoll EventLoop模式,节点启动16条线程,计算节点与存储节点tcp连接均匀分布在16条线程上,后面数据交互均在固定线程完成,充分利用多核优势。
计算节点: 计算节点采用bio方式与存储节点建立连接,计算节点与存储节点交互均采用req/res阻塞模式交互。 计算节点从存储节点read数据时,存储节点dio读取的数据直接使用ByteBuf.wrap,没有内存拷贝(程序层面),直接发送给计算节点。
连接建立后开启tcp_nodelay以减少网络延迟。
在比赛结束最后一天之前计算节点一直用的nio开发,写入耗时始终在719秒往上,因为一直觉得虽然nio在发送接收时与set/get线程有cpu切换,但是这些切换耗时与网络rtt相比应该不算什么,可事实总是在啪啪啪打脸,最后一天(其实也就写好两三天的样子,java环境最后几天才好,(/□ /))把nio改写成bio传输,写入时间从725降到560左右(不确定是否是因为cpu切换导致),总结一下就是不能搞经验主义,一定要benchmark everything。
可探索的改进
一般情况下我们使用nio都是将其fd绑定到某个event loop上,该event loop监听该fd的事件,这里其实我们可以改变nio使用方式,在set/get当前线程监听fd事件来读写数据,由set/get线程充当event loop,可能会有一个不错的提升。
第一次参加数据库相关的比赛,收获颇多,对数据库相关知识有了初步的了解,也学到了其他选手不错的分享,同时也非常感谢举办方举办这次比赛,给选手提供一个展示和学习的平台,预祝比赛越办越好。
-END-

点击 下方原文链接
可以查看文中 源码地址
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

