微服务架构中如何构建一个数据报告服务?
场景描述
在微服务架构中,每个微服务负责自己的数据库,微服务A是不允许直接连接微服务B的数据库进行操作的。
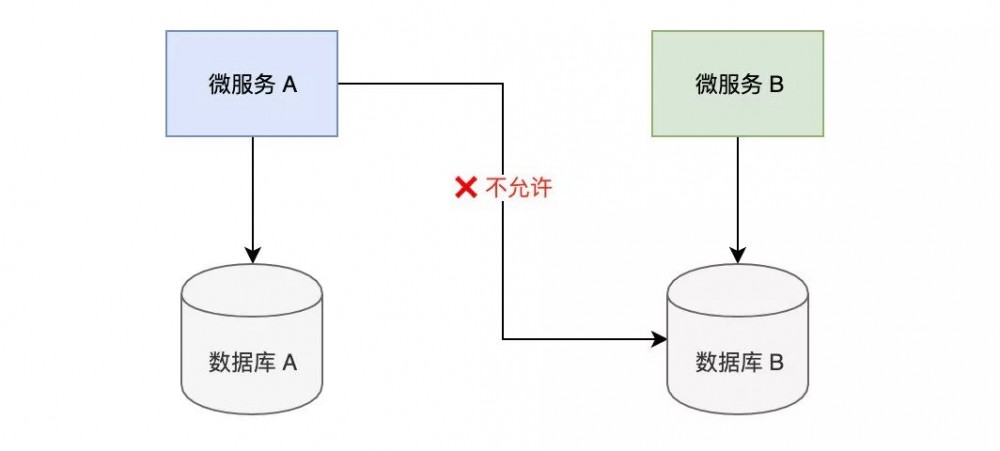
现在有2个微服务,一个是订单服务,一个是用户服务。
有一个数据报告的需求:生成一份 包含用户信息 的 订单报告 。
这就需要获取2个服务中的数据,进行连接汇总。
如何构建这个数据报告的服务呢?
方案1 直接连接数据库
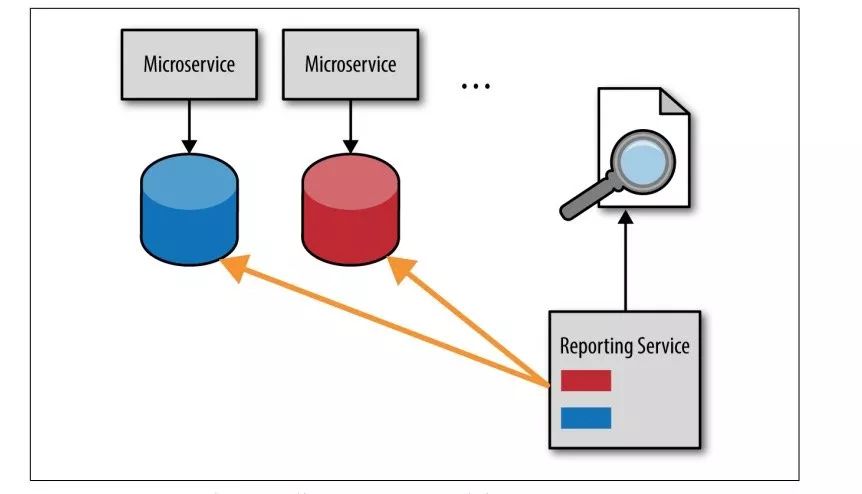
直接连接订单服务、用户服务的数据库,获取所需的数据,拿到后进行加工处理即可。
非常简单,但有明显的问题。
首先是破坏了上面所说的微服务的那个原则,直接去连别人的数据库,太粗暴了。
还有一个更严重的问题,如果订单服务和用户服务的数据库表结构变化了咋办?
报告服务必须跟着一起改变,敏感度太高。
方案2 数据汇聚
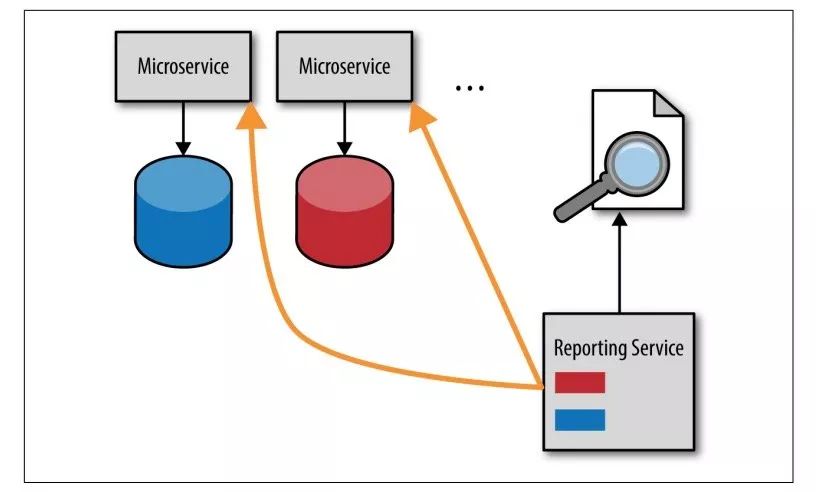
不直连数据了,调用这两个服务的 REST API 接口获取想要的数据。
解决了上个方案的问题,但此方法最大的问题是 性能差 。
报告服务需要最新的数据,就会经常访问这2个服务,随着数据规模的增加,3个服务的性能都会越来越低。
方案3 批量拉取数据
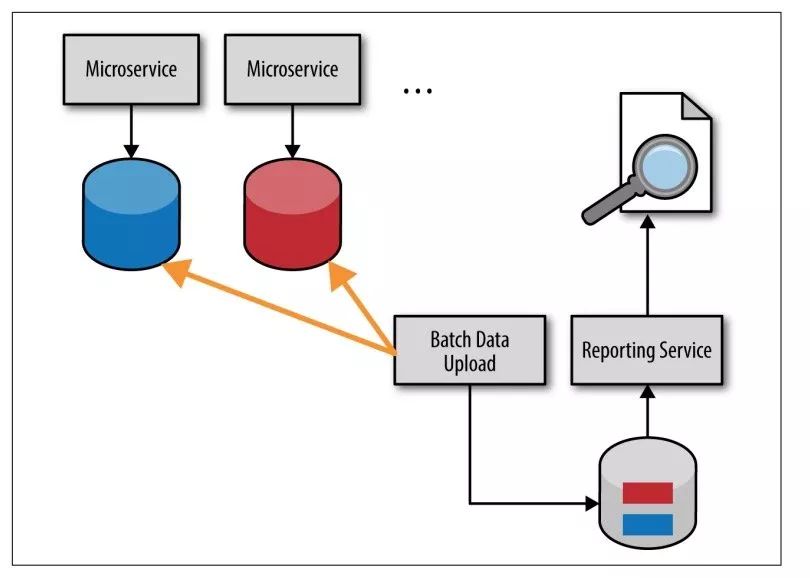
为报告服务建立一个自己的数据库,使用一个定时程序,批量从2个服务的数据库中拉数据,存入自己的数据库。
解决了上个方案的问题,性能明显提升,但好像又回到了第一个方案的问题,破坏了微服务的原则,而且对数据表结构的变动极其敏感。
好处是因为有了自己的数据库,方便多了,性能更好了。
方案4 事件推送模型
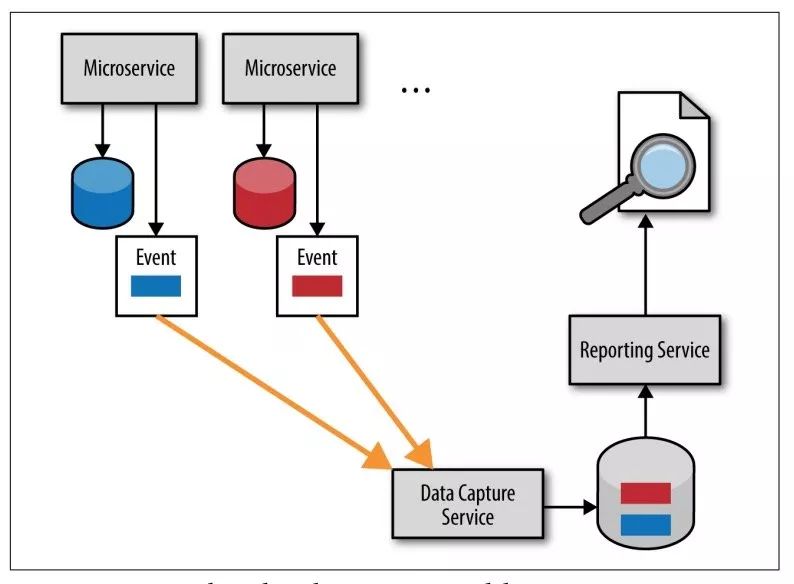
订单服务、用户服务中,数据表更后,产生一个事件,发布到消息系统中(例如 kafka),报告服务订阅相关主题,把接收到的数据写入自己的数据库。
好处:
-
松耦合,业务服务和报告服务没有调用关系,不管是业务接口层,还是数据库层。
-
数据一致性好,准实时,业务服务数据表更后立即发送事件消息,报告服务可以快速消费。
-
性能好,数据吞吐量增加后,报告服务可以增加处理事件的 worker,提供处理能力。
-
扩展性好,方便以后添加更多的数据处理需求,例如实时分析,而且,以后可能不止是做订单报告,可能会对更多的业务系统数据进行分析,到时,新服务只需把自己的数据变更事件发送到消息系统中即可。
翻译整理自:
https://medium.com/@muneeb.ahmed20/building-a-reporting-service-in-microservice-architecture-8d5bf3b90fb70
正文到此结束
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

