用Java构建基于Twitter的比特币情感分析器
比特币 创建于2009年,仍然是一个相当年轻的项目。但其市场价格非常不稳定。此外,比特币对大众效应更为敏感,比如像2017年底那样大众为占据的FOMO感觉一样。在大众的兴奋情绪推动下,比特币价格曾高达到2万美元的历史高点。
能够衡量围绕比特币的这种类型的情绪,可以很好地表明未来几个小时内等待比特币价格的因素。一个好的解决方案是分析像Twitter这样的社交网络上围绕比特币的活动。在本文中,我将教您如何创建一个Java程序,从Twitter上检索的tweets中分析关于比特币的所有大众情绪。
比特币情绪分析器规范
您将学习开发的比特币情绪分析器在执行过程中将执行以下操作:
1. 在Twitter上检索包含关键字bitcoin的推文
2. 分析每条检索到的推文,以及检测与之相关的大众情绪
3. 在Twitter上显示以下5种比特币情绪各自的百分比:非常消极,消极,中立,积极,非常积极
该程序将在每次执行后结束,由于Twitter是使用其免费的开发人员API设置的配额,将不会连续执行此分析。
创建Java项目
第一步是创建一个Java项目。我们将使用Maven作为依赖关系管理器。
在依赖性方面,我们将具有以下代码库:
1. Twitter4J是Twitter API的非官方Java客户端
2. Stanford CoreNLP是一个用于自然语言处理的开源库
Twitter4J将允许我们以一种简单的方式从Twitter中检索tweets的推文样本。Stanford CoreNLP代码库将使我们能够检测与每个相关推文相关的情绪。
这为我们的项目提供了以下POM:
<?xml version=”1.0″ encoding=”UTF-8″?>
<project xmlns=”http://maven.apache.org/POM/4.0.0″ xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance” xsi:schemaLocation=”http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd”>
<modelVersion>4.0.0</modelVersion>
<groupId>com.ssaurel</groupId>
<artifactId>bitcoinsentiment</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>bitcoinsentiment</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>edu.stanford.nlp</groupId>
<artifactId>stanford-corenlp</artifactId>
<version>3.9.2</version>
</dependency>
<dependency>
<groupId>edu.stanford.nlp</groupId>
<artifactId>stanford-corenlp</artifactId>
<version>3.9.2</version>
<classifier>models</classifier>
</dependency>
<dependency>
<groupId>org.twitter4j</groupId>
<artifactId>twitter4j-core</artifactId>
<version>[4.0,)</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
创建一个Twitter应用程序
使用Twitter API需要创建开发者帐户。它是免费的,但会有一定调用次数和配额限制使用。作为我们用于展示目的的项目的一部分,这是完全足够的。使用Twitter API所需的开发者帐户的创建在此处完成:
开发者地址https://developer.twitter.com/
创建此帐户后,您将转到下一页:
您将需要创建一个新的应用程序。我选择将我的应用程序命名为“ Bitcoin_Sentiment_Analyzer”。在创建此应用程序期间,您将必须填写有关它的一定数量的信息。最后,您将到达“Keys and tokens””屏幕,在该屏幕上,您将找到使您在调用Twitter API来检索与比特币相关的推文时正确进行身份验证的信息:
检索推文
现在已经创建了与比特币情绪分析器关联的Twitter应用程序,我们将能够继续检索程序中的推文。为此,我们将依靠Twitter4J代码库。
Twitter4J具有TwitterFactory和Twitter类作为其入口点。
TwitterFactory类将包含与Twitter API的连接信息的Configuration对象实例作为输入:
· 使用者API公钥
· 使用者API密钥
· 访问Token
· 访问Token密钥
然后,我将通过调用其getInstance方法从TwitterFactory检索Twitter对象实例的实例。有了这个对象,我们将能够在Twitter API上启动查询。我们将使用其搜索方法来检索符合特定条件的推文。
在Query对象中对查询建模,该对象以与您要通过Twitter API执行的查询相对应的字符串作为输入。对于比特币情绪分析器,我想检索包含关键字bitcoin的推文,而不是转发,链接,答案或图片。
该查询用以下字符串表示:
bitcoin -filter:retweets -filter:links -filter:replies -filter:images
Query类的setCount方法允许您定义要检索的结果数。如果使用免费的开发人员API,则此数量限制为100个结果。
最后,仍然需要通过从Twitter对象实例的search方法传递该查询来执行此查询 返回一个QueryResult对象,将其保留在其上以调用getTweets方法以检索Status对象的列表。每个Status对象代表一条推文。最终可以通过后一个对象的getText方法访问其文本内容。
所有这些提供了以下searchTweets方法:
public static List < Status > searchTweets(String keyword) {
List < Status > tweets = Collections.emptyList();
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true).setOAuthConsumerKey(“YOUR_CONSUMER_KEY”)
.setOAuthConsumerSecret(“YOUR_CONSUMER_SECRET”)
.setOAuthAccessToken(“YOUR_ACCESS_TOKEN”)
.setOAuthAccessTokenSecret(“YOUR_ACCESS_TOKEN_SECRET”);
TwitterFactory tf = new TwitterFactory(cb.build());
Twitter twitter = tf.getInstance();
Query query = new Query(keyword + ” -filter:retweets -filter:links -filter:replies -filter:images”);
query.setCount(100);
query.setLocale(“en”);
query.setLang(“en”);;
try {
QueryResult queryResult = twitter.search(query);
tweets = queryResult.getTweets();
} catch (TwitterException e) {}
return tweets;
}
分析一条推文的情绪分析
下一步是分析一条推文的情绪分析。Google,Amazon或Microsoft提供解决方案。但是也有非常好的免费和开源解决方案,例如Stanford CoreNLP代码库。
Stanford CoreNLP代码库完全满足我们的需求,这是我们的比特币情绪分析器程序的一部分。
StanfordCoreNLP类是API的入口点。我们通过传递属性的实例作为实例来实例化此对象,在其中定义了将在文本分析期间使用的不同注释器。
然后,我调用StanfordCoreNLP对象的处理方法以开始文本分析。作为结果回报,我得到一个Annotation对象,将在该对象上迭代以获得关联的CoreMap对象。对于这些对象中的每一个,我都检索一个Tree对象,该对象是通过将SentimentAnnotatedTree类作为输入调用get方法而获得的。
最后,仍然需要通过传递Tree的此实例作为输入来调用RNNCoreAnnotations类的静态方法getPredictedClass。返回值对应于此分析文本的总体情绪。文本的总体情感是通过保留文本最长部分的情感来计算的。
为作为输入传递的文本计算的情感表示为一个整数,其值的范围可以从0到4(含0和4)。
为了便于以后对文本的情绪进行操作,我定义了TypeSentiment枚举,将每个值与以该枚举的形式定义的关联感觉相关联。
所有这些都给出以下代码:
enum TypeSentiment {
VERY_NEGATIVE(0), NEGATIVE(1), NEUTRAL(2), POSITIVE(3), VERY_POSITIVE(4);
int index;
private TypeSentiment(int index) {
this.index = index;
}
public static TypeSentiment fromIndex(int index) {
for (TypeSentiment typeSentiment: values()) {
if (typeSentiment.index == index) {
return typeSentiment;
}
}
return TypeSentiment.NEUTRAL;
}
}
public static TypeSentiment analyzeSentiment(String text) {
Properties props = new Properties();
props.setProperty(“annotators”, “tokenize, ssplit, parse, sentiment”);
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
int mainSentiment = 0;
if (text != null && text.length() > 0) {
int longest = 0;
Annotation annotation = pipeline.process(text);
for (CoreMap sentence: annotation.get(CoreAnnotations.SentencesAnnotation.class)) {
Tree tree = sentence.get(SentimentCoreAnnotations.SentimentAnnotatedTree.class);
int sentiment = RNNCoreAnnotations.getPredictedClass(tree);
String partText = sentence.toString();
if (partText.length() > longest) {
mainSentiment = sentiment;
longest = partText.length();
}
}
}
return TypeSentiment.fromIndex(mainSentiment);
}
汇编程序的不同部分
现在我们可以检索与给定关键字相对应的推文。然后我们能够分析其每个推文,以获得与之相关的推文情绪。剩下的就是将所有这些汇编到BitcoinSentimentAnalyzer类的主要方法中。
首先我定义一个HashMap,它将存储在分析的tweets中发现每个情感的次数。然后使用关键字“ bitcoin”作为输入来调用searchTweets方法。
下一步是迭代由searchTweets方法返回的列表中包含的Status对象。对于每条推文,我都检索关联的文本并调用analysisSentiment方法以TypeSentiment实例的形式计算关联的情感。
每次返回情感时,我们都会在HashMap中增加计数器。在分析了所有检索到的推文之后,我们可以显示关于比特币的每种观点的百分比,以在Twitter上给出当前观点的分布。
以下是完整的代码:
package com.ssaurel.bitcoinsentiment;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map.Entry;
import java.util.Properties;
import edu.stanford.nlp.ling.CoreAnnotations;
import edu.stanford.nlp.neural.rnn.RNNCoreAnnotations;
import edu.stanford.nlp.pipeline.Annotation;
import edu.stanford.nlp.pipeline.StanfordCoreNLP;
import edu.stanford.nlp.sentiment.SentimentCoreAnnotations;
import edu.stanford.nlp.trees.Tree;
import edu.stanford.nlp.util.CoreMap;
import twitter4j.Query;
import twitter4j.QueryResult;
import twitter4j.Status;
import twitter4j.Twitter;
import twitter4j.TwitterException;
import twitter4j.TwitterFactory;
import twitter4j.conf.ConfigurationBuilder;
public class BitcoinSentimentAnalyzer {
enum TypeSentiment {
VERY_NEGATIVE(0), NEGATIVE(1), NEUTRAL(2), POSITIVE(3), VERY_POSITIVE(4);
int index;
private TypeSentiment(int index) {
this.index = index;
}
public static TypeSentiment fromIndex(int index) {
for (TypeSentiment typeSentiment: values()) {
if (typeSentiment.index == index) {
return typeSentiment;
}
}
return TypeSentiment.NEUTRAL;
}
}
public static List < Status > searchTweets(String keyword) {
List < Status > tweets = Collections.emptyList();
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true).setOAuthConsumerKey(“UiLHCETjD1SLKb4EL6ixm90Mv”)
.setOAuthConsumerSecret(“fDAqCfMQ6Azj1BbvXqS3f9HoPNM6BIGSV7jw3SUBu8TAaPPnBx”)
.setOAuthAccessToken(“58410144-m5F3nXtyZGNXFZzofNhYp3SQdNMrbfDLgZSvFMdOq”)
.setOAuthAccessTokenSecret(“PxlJJ3dRMlMiUf7rFAqEo4n0yLbiC6FC4hyvKF7ISBgdW”);
TwitterFactory tf = new TwitterFactory(cb.build());
Twitter twitter = tf.getInstance();
Query query = new Query(keyword + ” -filter:retweets -filter:links -filter:replies -filter:images”);
query.setCount(100);
query.setLocale(“en”);
query.setLang(“en”);;
try {
QueryResult queryResult = twitter.search(query);
tweets = queryResult.getTweets();
} catch (TwitterException e) {}
return tweets;
}
public static TypeSentiment analyzeSentiment(String text) {
Properties props = new Properties();
props.setProperty(“annotators”, “tokenize, ssplit, parse, sentiment”);
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
int mainSentiment = 0;
if (text != null && text.length() > 0) {
int longest = 0;
Annotation annotation = pipeline.process(text);
for (CoreMap sentence: annotation.get(CoreAnnotations.SentencesAnnotation.class)) {
Tree tree = sentence.get(SentimentCoreAnnotations.SentimentAnnotatedTree.class);
int sentiment = RNNCoreAnnotations.getPredictedClass(tree);
String partText = sentence.toString();
if (partText.length() > longest) {
mainSentiment = sentiment;
longest = partText.length();
}
}
}
return TypeSentiment.fromIndex(mainSentiment);
}
public static void main(String[] args) {
HashMap < TypeSentiment, Integer > sentiments = new HashMap < BitcoinSentimentAnalyzer.TypeSentiment, Integer > ();
List < Status > list = searchTweets(“bitcoin”);
for (Status status: list) {
String text = status.getText();
TypeSentiment sentiment = analyzeSentiment(text);
Integer value = sentiments.get(sentiment);
if (value == null) {
value = 0;
}
value++;
sentiments.put(sentiment, value);
}
int size = list.size();
System.out.println(“Sentiments about Bitcoin on ” + size + ” tweets”);
for (Entry < TypeSentiment, Integer > entry: sentiments.entrySet()) {
System.out.println(entry.getKey() + ” => ” + (entry.getValue() * 100) / size + ” %”);
}
}
}
运行比特币情绪分析器
本文的最佳之处在于,我们将把刚刚构建的比特币情绪分析器程序付诸实践。执行该程序后,经过几秒钟的分析,我得到以下结果:
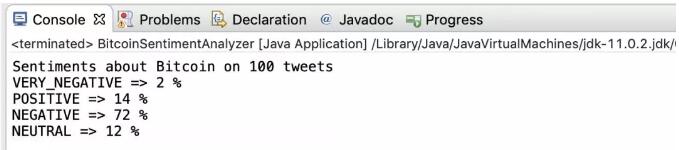
在Twitter API返回的推文示例中,人们对比特币的普遍看法如下:
1. 2%非常负面的推文
2. 72%的负面推文
3. 12%的中立推文
4. 14%的正面推文
我们的比特币情绪分析清楚地表明,目前Twitter上的总体情绪对比特币相当负面。
更进一步
我们的比特币情绪分析仪功能完善,为进一步分析比特币情绪提供了良好的基础。因此,您可以连续执行此分析,以使其与可通过Coindesk的比特币价格指数API检索的比特币价格相关。
因此,如果Twitter上有关比特币的普遍情绪与价格的变化直接相关,则可以由此推断。该程序可以帮助您改善对比特币未来价格的预测。对于此类程序,您将需要切换到Twitter的付费开发人员API,以实时获取有关比特币的推文。
根据国家《 关于防范代币发行融资风险的公告 》,大家应警惕代币发行融资与交易的风险隐患。
本文来自 LIANYI 转载,不代表链一财经立场,转载请联系原作者。
正文到此结束
- 本文标签: http IO junit Google Collections consumer core 图片 静态方法 https API 实例 开源 src Property HashMap ip 管理 parse 开发 build Twitter token pom 开发者 App dependencies schema 社交网络 bug maven UI CTO list 回报 FAQ id apache map 注释 value Developer 免费 MQ java 密钥 需求 key Word Collection tk cat 代码 XML Amazon
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

