Deep Java Library (DJL) 简介:与引擎无关的 Java 深度学习框架
本文要点
- 开发人员可以使用 Java 和他们喜欢的 IDE 来构建、训练和部署机器学习(ML)和深度学习(DL)模型
- DJL 简化了深度学习(DL)框架的使用,目前支持 Apache MXNet
- DJL 的开源对于工具包及其用户来说都是互惠互利的
- DJL 是引擎无关的,这意味着开发人员只需编写一次代码就可以在任何引擎上运行
- 在尝试使用 DJL 之前,Java 开发人员应该了解 ML 生命周期和常用的 ML 术语
亚马逊(Amazon)的 DJL (Deep Java Library )是一个深度学习工具包,使用它可在 Java 中原生地进行机器学习(ML)和深度学习(DL)模型开发,从而简化深度学习框架的使用。DJL 是在 2019 年 re:Invent 大会上开源的工具包,它提供了一组高级 API 来训练、测试和运行在线推理(inference)。Java 开发人员可以开发自己的模型,也可以在他们的 Java 代码中使用数据科学家用 Python 开发的预先训练的模型。
DJL 秉承了 Java 的座右铭,“编写一次,到处运行(WORA)”,因为它是引擎和深度学习框架无关的。开发人员只需编写一次就可在任何引擎上运行。DJL 目前提供了一个 Apache MXNet 的实现,这是一个可以简化深度神经网络开发的 ML 引擎。DJL API 使用 JNA(Java Native Access)来调用相应的 Apache MXNet 操作。DJL 编排管理基础设施,基于硬件配置来提供自动的 CPU/GPU 检测,以确保良好的运行效果。
DJL API 通过抽象常用的功能来开发模型,这使 Java 开发人员能够利用现有的知识,从而可以轻松地过渡到 ML。为了了解 DJL 的实际效果,我们开发一个“鞋”的分类模型作为一个简单的示例。
机器学习生命周期
我们建立“鞋”分类模型遵循了机器学习的生命周期。ML 生命周期与传统的软件开发生命周期有所不同,它包含六个具体的步骤:
- 获取数据
- 清洗并准备数据
- 生成模型
- 评估模型
- 部署模型
- 从模型中获得预测(或推理)
生命周期的最终结果是一个可以查询并返回答案(或预测)的机器学习模型。

模型只是数据中趋势和模式的数学表示。好的数据才是所有 ML 项目的基础。
在步骤 1 中,从可靠的来源中获取数据。在步骤 2 中,数据被清洗、转换并以机器可以学习的格式存储。清洗和转换过程通常是机器学习生命周期中最耗时的部分。DJL 提供了利用翻译器(translator)来对图像进行预处理的能力,这能为开发人员简化清洗和转换过程。翻译器可以执行一些图像任务,比如,可以根据预设参数调整图像的大小或将图像从彩色图转换为灰度图。
刚刚过渡向机器学习的开发人员常常会低估清洗和转换数据所需的时间,因此翻译器是快速启动该过程的好方法。步骤 3,在训练过程中,一个机器学习算法会对数据进行多遍(或多代)处理,不断研究它们,以试图学习到不同类型的“鞋”。训练过程中发现的与“鞋”相关的趋势和模式会被存储在模型中。当需要评估模型以确定其在识别“鞋”方面的能力时,第 4 步会作为训练的一部分;如果发现了错误,则予以纠正。在步骤 5 中,将模型部署到生产环境中。模型投入生产后,步骤 6 允许其他系统使用该模型。
通常,可以在代码中动态地加载模型,或者通过基于 REST 的 HTTPS 端点访问模型。
数据
“鞋”分类模型是一个多级分类计算机视觉(CV)模型,它使用有监督学习进行训练,可以将“鞋”分为四类:靴子(boots)、凉鞋(sandals)、鞋子(shoes)或拖鞋(slippers)。有监督学习必须包含已经标记了我们想要预测的目标(或答案)的数据;这就是机器学习的方式。
“鞋”分类模型的数据源是 德克萨斯大学奥斯汀分校 (The University of Texas at Austin)提供的 UTZappos50k 数据集(dataset),它可免费用于学术和非商业用途。下面这个“鞋子”数据集包含了从 Zappos.com 收集的 50025 张带标签的目录图像。

“鞋”数据保存在本地,并使用 DJL 的 ImageFolder 数据集对其进行加载,该数据集可以从本地文件夹中检索图像。
复制代码
// 识别训练数据的位置 String trainingDatasetRoot ="src/test/resources/imagefolder/train"; // 识别验证数据的位置 String validateDatasetRoot ="src/test/resources/imagefolder/validate"; // 创建训练数据 ImageFolder 数据集 ImageFolder trainingDataset = initDataset(trainingDatasetRoot); // 创建验证数据 ImageFolder 数据集 ImageFolder validateDataset = initDataset(validateDatasetRoot);
在本地构造数据时,我并没有深入到 UTZappos50k 数据集所标识的最细粒度的分类等级,比如到脚踝的、膝盖等高的、到达小腿中部的、过膝的等靴子的最细粒度等级的分类标签。我的本地数据使用的是最高等级的分类,仅包括靴子、凉鞋、鞋子和拖鞋等四类。
在 DJL 术语中,数据集只用于保存训练数据。有些数据集的实现可用于下载数据(基于我们提供的 URL)、提取数据、以及自动地将数据分为训练集和验证集。
自动分离是一个特别有用的特性,因为不使用相同的数据来训练和验证模型这一点是至关重要的。该模型所使用的训练数据集用于查找“鞋”数据中的趋势和模式。验证数据集通过提供对“鞋”分类模型精度无偏差的估计来检验模型的效果。
如果用训练的数据验证模型,则会降低我们对模型分类鞋子能力的信心,因为模型是用它已经看到的数据进行测试的。在现实世界中,老师也不会使用和学习指南上完全相同的题目来测试学生,因为这不能衡量一个学生的真实知识或对资料的理解;当然,同样的概念也适用于机器学习模型。
训练
现在我们已经将“鞋”数据分为训练集和验证集,下面我们将使用神经网络来训练(或生成)模型。
复制代码
public finalclassTraining extends AbstractTraining {
. . .
@Override
protected void train(Arguments arguments) throws IOException {
// 识别训练数据的位置
String trainingDatasetRoot ="src/test/resources/imagefolder/train";
// 识别验证数据的位置
String validateDatasetRoot ="src/test/resources/imagefolder/validate";
// 创建训练数据 ImageFolder 数据集
ImageFolder trainingDataset = initDataset(trainingDatasetRoot);
// 创建验证数据 ImageFolder 数据集
ImageFolder validateDataset = initDataset(validateDatasetRoot);
. . .
try(Model model =Models.getModel(NUM_OF_OUTPUT, NEW_HEIGHT, NEW_WIDTH)) {
TrainingConfig config = setupTrainingConfig(loss);
try(Trainer trainer = model.newTrainer(config)) {
trainer.setMetrics(metrics);
trainer.setTrainingListener(this);
Shape inputShape =newShape(1, 3, NEW_HEIGHT, NEW_WIDTH);
// 根据相应输入的形状初始化训练器
trainer.initialize(inputShape);
// 在数据中查找模式
fit(trainer, trainingDataset, validateDataset,"build/logs/training");
// 设置模型属性
model.setProperty("Epoch", String.valueOf(EPOCHS));
model.setProperty("Accuracy", String.format("%.2f",getValidationAccuracy()));
// 训练完成后保存模型,为后面的推理做准备
// 模型保存为 shoeclassifier-0000.params
model.save(Paths.get(modelParamsPath), modelParamsName);
}
}
}
}
第一步是通过调用 Models.getModel(NUM_OF_OUTPUT, NEW_HEIGHT, NEW_WIDTH) 来获取模型实例。深度学习是机器学习的一种形式,它使用神经网络来训练模型。神经网络是以人脑中的神经元来进行建模的;神经元是可以将信息(或数据)传递给其他细胞的细胞。
ResNet-50 是一种常用于图像分类的神经网络,50 表示从初始输入数据和最终预测之间有 50 个学习层(或神经元)。getModel() 方法用于创建一个空模型,构造一个 ResNet-50 神经网络,并将神经网络设置到该模型中。
复制代码
publicclassModels {
public static ai.djl.Model getModel(intnumOfOutput,intheight,intwidth){
// 创建一个空模型的新实例
ai.djl.Model model = ai.djl.Model.newInstance();
// 是构建神经网络所需的可组合单元;可以像像乐高积木一样将它们连结在一起,
// 形成一个复杂的网络
Block resNet50 =
// 构建网络
newResNetV1.Builder()
.setImageShape(newShape(3,height,width))
.setNumLayers(50)
.setOutSize(numOfOutput)
.build();
// 将神经网络设置到模型中
model.setBlock(resNet50);
return model;
}
}
下一步是通过调用 model.newTrainer(config) 方法来设置和配置训练器。通过调用 setupTrainingConfig(loss) 方法来初始化配置对象,该方法通过设置训练的配置(或超参)来决定如何训练网络。
接下来的步骤使我们可以通过设置以下内容来向 Trainer 中添加功能:
- 使用 trainer.setMetrics(metrics) 来设置 Metrics
- 使用 trainer.setTrainingListener(this) 来设置训练监听器
- 使用 trainer.initialize(inputShape) 来设置合适的输入形状
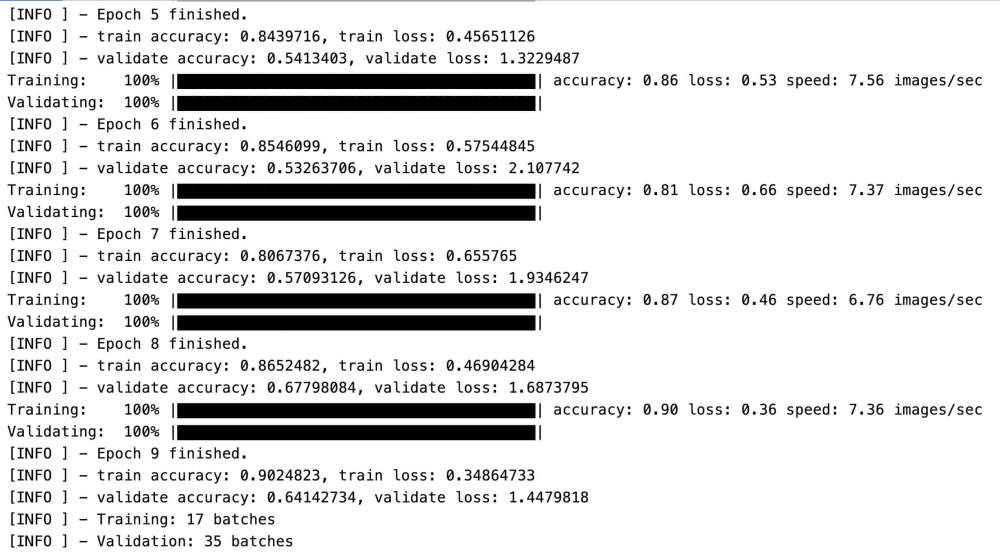
Metrics 在训练期间收集并报告关键绩效指标(KPI),该 KPI 可用于分析和监控训练的效果和稳定性。下一步是通过调用 fit(trainer, trainingDataset, validateDataset, “build/logs/training”) 方法来启动训练过程,该方法将迭代训练数据并存储在模型中找到的模式。训练结束时,使用 model.save(Paths.get(modelParamsPath) 方法将一个表现良好的、经过验证的模型工件及属性保存在本地。
训练过程中报告的度量指标如下所示。注意,随着每代(epoch)(或每遍(pass))的递增,模型的精度都会提高;第 9 代(epoch)的最终训练精度为 90%。
推理
现在我们已经生成了模型,它可以用于对我们不知道类型(或目标)的新数据执行推理(或预测)。
复制代码
privateClassifications predict()throws IOException, ModelException, TranslateException {
// 在训练期间保存到模型的位置
String modelParamsPath ="build/logs";
// 训练时设置的模型名称
String modelParamsName ="shoeclassifier";
// 需要分类的图像路径
String imageFilePath ="src/test/resources/slippers.jpg";
// 从路径加载图像文件
BufferedImage img =BufferedImageUtils.fromFile(Paths.get(imageFilePath));
// 持有每个标签的概率分数
Classifications predictResult;
try(Model model =Models.getModel(NUM_OF_OUTPUT, NEW_HEIGHT, NEW_WIDTH)) {
// 加载模型
model.load(Paths.get(modelParamsPath), modelParamsName);
// 定义用于预处理和后置处理的翻译器
Translator<BufferedImage, Classifications> translator =newMyTranslator();
// 使用预测器运行推理
try(Predictor<BufferedImage, Classifications> predictor = model.newPredictor(translator)) {
predictResult = predictor.predict(img);
}
}
return predictResult;
}
在设置了模型和要分类的图像的必要路径之后,使用 Models.getModel(NUM_OF_OUTPUT, NEW_HEIGHT, NEW_WIDTH) 方法获取一个空模型实例,并使用 model.load(Paths.get(modelParamsPath), modelParamsName) 方法对其进行初始化。它将会加载上一步训练的模型。
接下来,使用 model.newPredictor(translator) 方法初始化一个带有指定的 Translator 的 Predictor。在 DJL 术语中,Translator 提供了模型预处理和置后处理的能力。例如,对于 CV 模型,需要将图像重塑为灰度图;Translator 是可以做到的。Predictor 使我们可以利用 predictor.predict(img) 方法来对加载的 Model 进行推理,并传入图像进行分类。
这个示例展示的是单个的预测,但是 DJL 也支持批量预测。推理存储在 predictResult 中,predictResult 包含了每个标签的概率估计。
推理(每张图片)及其对应的概率得分如下所示。




(表格对应的图片如上所示)
| 图像 | 概率得分 |
|---|---|
| 如图 1 | [信息] - [ 分类: “0”, 概率: 0.98985 分类: “1”, 概率: 0.00225 分类: “2”, 概率: 0.00224 分类: “3”, 概率: 0.00564 ] 分类 0 代表 靴子 ,概率得分为 98.98% |
| 图 2 | [信息] - [ 分类: “0”, 概率: 0.02111 分类: “1”, 概率: 0.76524 分类: “2”, 概率: 0.01159 分类: “3”, 概率: 0.20204 ] 分类 1 代表 凉鞋 ,概率得分为 o 76.52% |
| 图 3 | [信息] - [ 分类: “0”, 概率: 0.05523 分类: “1”, 概率: 0.01417 分类: “2”, 概率: 0.87900 分类: “3”, 概率: 0.05158 ] 分类 2 代表 鞋子 ,概率得分为 87.90% |
| 图 4 | [信息] - [ 分类: “0”, 概率: 0.00003 分类: “1”, 概率: 0.01133 分类: “2”, 概率: 0.00179 分类: “3”, 概率: 0.98682 ] 分类 3 代表拖鞋,概率得分为 of 98.68% . |
DJL 提供了与其他 Java 库一样的原生 Java 开发体验和功能。设计这些 API 是为了指导开发人员能够用最佳实践来完成深度学习任务。在开始使用 DJL 之前,需要对 ML 生命周期有一个很好的理解。如果您是 ML 初学者,请先阅读这篇 概述 或 InfoQ 的系列文章《 软件开发人员机器学习入门 》。在理解了生命周期和常见的 ML 术语之后,开发人员就可以快速地掌握 DJL 的 API 了。
亚马逊已经开源了 DJL,有关该工具包的更多详细信息可以在 DJL 网站 和 Java 库 API 规范 (Java Library API Specification) 页面上找到。您也可以回顾下 “鞋”分类模型 的代码,以进一步探索该示例。
作者介绍
Kesha Williams 是一位屡获殊荣的软件工程师、机器学习实践者和 A Cloud Guru 的技术讲师,拥有 24 年的经验。在大学任教期间,她曾培训并指导了数千名来自美国、欧洲和亚洲的 Java 软件工程师。她经常带领创新团队验证新兴技术,并在全球各地的会议上分享她的经验教训。作为 TED 的 Spotlight Presentation Academy 的获得者,她在 TED 舞台上做过机器学习的演讲。此外,她在人工智能领域的开创性工作为她赢得了亚马逊的 Alexa Champion 和 AWS Machine Learning Hero 的殊荣。在业余时间,她通过在线社交专业网络平台 Colors of STEM 指导女性科技从业者。
原文链接:
Getting to Know Deep Java Library (DJL)
正文到此结束
- 本文标签: https UI 时间 list build 免费 IO 目录 ip 配置 代码 value Amazon 下载 图片 tab 网站 亚马逊 实例 开源 文章 深度学习 2019 cat FIT 初学者 final python ORM 部署 测试 学生 API App 开发 生命 Property 回答 翻译 美国 管理 智能 参数 http 数据科学 工程师 root 科技 IDE CTO REST src 神经网络 模型 apache 数据 软件工程师 软件 lib 监听器 id java
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

