Spring循环依赖的解决
Spring循环依赖的解决
什么是循环依赖
循环依赖,是依赖关系形成了一个圆环。比如:A对象有一个属性B,那么这时候我们称之为A依赖B,如果这时候B对象里面有一个属性A。那么这时候A和B的依赖关系就形成了一个循环,这就是所谓的循环依赖。如果这时候IOC容器创建A对象的时候,发现B属性,然后创建B对象,发现里面有A属性,然后创建B.....这么无限循环下去。我们先用代码演示一下:
public class A {
private B b=new B();
}
public class B {
private A a=new A();
}
public class Test {
public static void main(String[] args) {
A a = new A();
}
}
运行一下结果
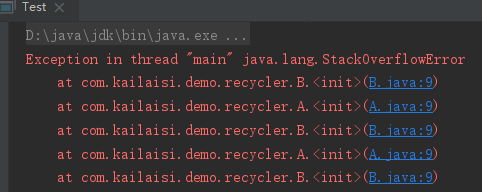
那么我们可以看到循环依赖存在的问题了
- 栈内存溢出
- 程序的维护性和扩展性太差
显然这种思路是不正确的。
产生循环依赖产生的条件:
- 在容器中创建的对象是单例的
- 对象是循环依赖
精简版解决方案
如果我们自己写的话,该如何解决的呢?
public class A {
private B b;
public void setB(B b) {
this.b = b;
}
}
public class B {
private A a;
public void setA(A a) {
this.a = a;
}
}
public class Test {
public static void main(String[] args) {
A a = new A();//创建a对象
B b = new B();//因为a对象依赖B,那么创建B
b.setA(a);//创建B对象的时候,发现依赖A,那么把通过构造方法生成的对象a赋值给B
a.setB(b);//然后把生成的b对象注入到a里面
}
}
Spring解决方案
当使用Spring的 @Autowired 注解的时候,其实Spring的实现原理和上面很相似,先通过生成相关的对象,然后再把里面需要依赖的对象设置进去。
我们现在从Spring源码来走一遍。。
我们现贴出最基本的测试代码
@Component
public class A {
@Autowired
B b;
}
@Component
public class B {
@Autowired
A a;
}
public class RecyclerTest {
@Test
public void test() {
ApplicationContext context = new AnnotationConfigApplicationContext("com.kailaisi.demo.recycler");
//getbean得时候才进行IOC容器中的对象的实例化工作
A a = (A) context.getBean("a");
}
}
在我们之前发布的 SpringBoot启动流程源码分析 里面,我们提到过bean单例的生成是在Spring容器创建过程中来完成的。经过多层的调用,最终会调用到 doGetBean 这个方法里面。
protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType,
@Nullable final Object[] args, boolean typeCheckOnly) throws BeansException {
...
Object bean;
//先从缓存中获取是否定义了对应的类,这里的缓存包括了半成品类缓存(只生成了类,但是还没有进行属性注入的类)和成品类缓存(已经完成了属性注入的类)
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
......
//如果符合条件,直接从对饮给的bean单例中获取到对象,然后返回
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
else {
...
try {
.....
//创建单例bean,解决循环依赖的根本方案
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
//调用创建单例的方法
return createBean(beanName, mbd, args);
}
...
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
...
return (T) bean;
}
@Override
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
...
//进行bean的创建
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
...
}
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
//bean的包装类
BeanWrapper instanceWrapper = null;
...
if (instanceWrapper == null) {
//创建beanDefinition所对应的的参数的bean实例,这里通过构造方法或者工厂方法或者cglib创建了对象
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
if (earlySingletonExposure) {
//将对象放到registeredSingletons队列中,并从earlySingletonObjects中移除
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
...
//注入A的依赖,这里面会发现属性,然后从doGetBean()方法开始,生成B对象,然后循环走到这里的时候,在队列里面会同时存在A对象和B对象。然后B对象注入A成功,返回后将生成的B注入到A,此时完成了A和B的对象生成,并解决了循环依赖问题
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
...
}
加载过程比较长,其实主要是在加载的过程中将对象的创建过程进行了分类处理,在创建的不同时期,放入到队列来进行区分。
- singletonObjects:单例对象列表
- singletonFactories:单例工厂队列,对象刚开始创建的时候,会放入到这个队列。
- earlySingletonObjects:产生了循环依赖的对象队列,对象在创建之后,进行注入过程中,发现产生了循环依赖,那么会将对象放入到这个队列,并且从singletonFactories中移除掉。
- singletonsCurrentlyInCreation:正在创建的对象队列,整个创建过程都存放在这个队列里面,当完成了所有的依赖注入以后,从这个队列里面移除
- registeredSingletons:已经创建成功的单例列表。
知道了这几个队列以后,我们可以来整理测试例子中,A和B对象是如何一步步创建,并解决其循环依赖的问题了。
- 首先,依次从singletonObjects,earlySingletonObjects,singletonFactories队列中去寻找a对象,发现都没有,返回了null。那么这时候就需要创建B对象
- a的创建的准备:在创建之前,将a放入到singletonsCurrentlyInCreation队列,表明a正在进行创建。
- 开始创建a:通过反射创建对象a。
- 进行创建后的处理:创建a对象以后,将a放入到singletonFactories和registeredSingletons队列,并从earlySingletonObjects中移除。然后进行依赖注入工作,发现有依赖B对象。
- 这时候进入了B对象的注入过程
- 首先,依次从singletonObjects,earlySingletonObjects,singletonFactories队列中去寻找b对象,发现都没有,返回了null。那么这时候就需要创建B对象
- b的创建的准备工作:在创建之前,将b放入到singletonsCurrentlyInCreation队列,表明b正在进行创建
- 开始创建b:通过反射创建对象b。
- 进行创建后的处理:将b放入到singletonFactories和registeredSingletons队列,并从earlySingletonObjects中移除。然后进行依赖注入工作,发现有依赖 A对象。
- 这时候进入A的注入过程。。。
- 从singletonObjects中查找a,发现a不存在但是singletonsCurrentlyInCreation队列中有a,那么这时候说明a是在创建过程中的,此处又需要创建,属于循环依赖了。然后去earlySingletonObjects查找,也没发现。那么这时候去singletonFactories队列中去寻找a对象,找到了。这时候将a对象放入到earlySingletonObjects队列,并从singletonFactories中移除。因为发现了a对象,这里直接返回a,此时完成了b对象对A的依赖注入了
- b实例化完成,而且依赖也注入完成了,那么进行最后的处理。将b实例从singletonsCurrentlyInCreation队列移除,表明b对象实例化结束。然后将b放入到singletonObjects和registeredSingletons队列,并从singletonFactories和earlySingletonObjects队列移除。最后将b对象注入到a对象中。然后a完成了创建过程。
- a实例化完成,而且依赖也注入完成了,那么进行最后的处理。将a实例从singletonsCurrentlyInCreation队列移除,表明a对象实例化结束。然后将a放入到singletonObjects和registeredSingletons队列,并从singletonFactories和earlySingletonObjects队列移除。此时完成了a对象的创建。
总结
上述就是spring解决循环依赖的整体过程,跟我们之前的那个方法很相似,只是对于各种情况的处理更仔细。而且从这个过程也能理解spring对于对象的创建过程。
本文由 开了肯 发布!
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

