HashMap 中的位运算
Java 8 中 HashMap 的实现使用了很多位操作来进行优化。本文将详细介绍每种位操作优化的原理及作用。
-
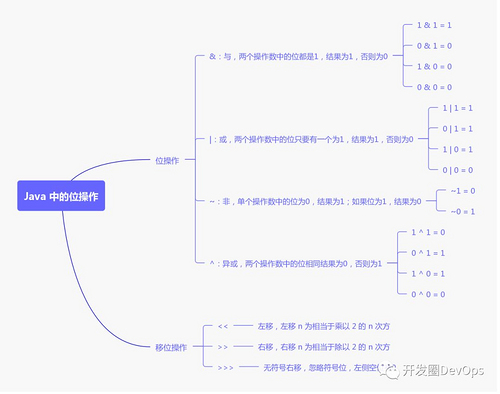
Java 中的位运算
-
位操作包含:与、或、非、异或
-
移位操作包含: 左移、右移、无符号右移
-
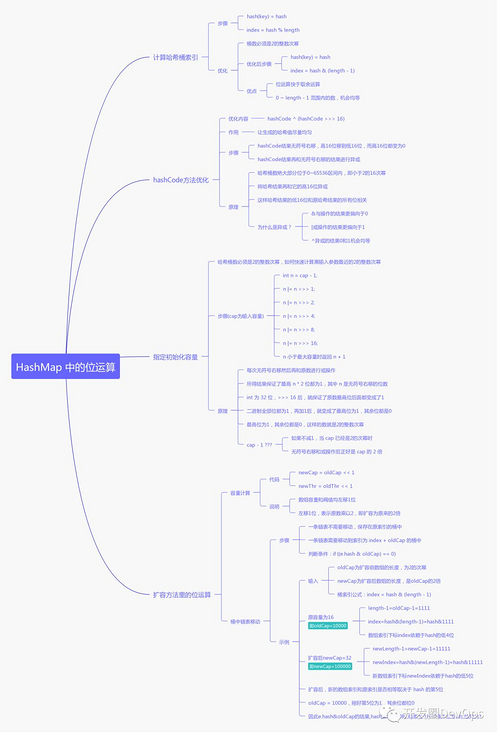
HashMap 中的位运算
-
计算哈希桶索引
-
hashCode方法优化
-
指定初始化容量
-
扩容方法里的位运算
-
总结回顾
HashMap中的位运算
Java 8 中,HashMap 类使用了很多位运算来进行优化,位运算是非常高效的。下边我们将详细介绍。
Java 中的位运算
位操作包含:与、或、非、异或
-
与
&,两个操作数中的位都是1,结果为1,否则为0。 -
1 & 1 = 1
-
0 & 1 = 0
-
1 & 0 = 0
-
0 & 0 = 0
-
或
|,两个操作数中的位只要有一个为1,结果为1,否则为0。 -
1 | 1 = 1
-
0 | 1 = 1
-
1 | 0 = 1
-
0 | 0 = 0
-
非
~,单个操作数中的位为0,结果为1;如果位为1,结果为0。 -
~1 = 0
-
~0 = 1
-
异或
^,两个操作数中的位相同结为0,否则为1。 -
1 ^ 1 = 0
-
0 ^ 1 = 1
-
1 ^ 0 = 1
-
0 ^ 0 = 0
移位操作包含:左移、右移、无符号右移
-
左移
<<,左移 n 为相当于乘以 2n,例如 num<<1,num 左移1位 = num*2;num << 2,num 左移2位 = num*4 -
右移
>>,右移 n 为相当于除以 2n,例如 num>>1,num 右移1位 = num/2;num>>2,num 右移2位 = num/4 -
无符号右移
>>>,计算机中数字以补码存储,首位为符号位;无符号右移,忽略符号位,左侧空位补0
HashMap 中的位运算
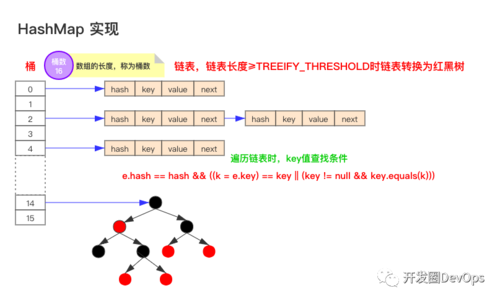
Java 8 中 HashMap 的实现结构如下图所示,对照结构图我们将分别介绍 HashMap 中的几种位运算的实现原理以及它们的作用、优点。
计算哈希桶索引
HashMap 的 put(key, value) 操作和 get(key) 操作,会根据 key 值计算出该 key 对应的值存放的桶的索引。计算过程如下:
-
计算 key 值的哈希值得到一个正整数,hash(key) = hash
-
使用 hash(key) 得到的正整数,除以桶的长度取余,结果即为 key 值对应 value 所在桶的索引,index = hash(key) % length
put/get操作,计算key值对应value所在哈希桶的索引的主要代码
// table 即为上述结构图中存放左边桶的数组
transient Node<K,V>[] table;
// 计算 key 值的哈希值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
// 当 table 为 null 或长度为0时,初始化数组 table
n = (tab = resize()).length;
// tab[i = (n - 1) & hash] 的下标表达式 i = (n - 1) & hash 即为计算哈希桶的索引
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
省略其他代码
}
省略其他代码
}
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// n = tab.length,n 即为哈希桶的长度
// tab[(n - 1) & hash],hash 为 key 值的哈希值,表达式 (n - 1) & hash 为哈希桶的索引
省略其他代码
}
return null;
}
上述代码中,使用了与操作来代替取余,我们先来看结论: 当 length 为 2 的次幂时,num & (length - 1) = num % length 等式成立 ,使用 Java 代码来验证一下:
public static void main(String[] args) {
// n次幂
int multiple = 0;
// 长度
int length;
// 不成立的次数
int fail = 0;
while (true) {
length = (int) Math.pow(2, ++multiple);
if (length >= Integer.MAX_VALUE) {
break;
}
// 随机生成一个正整数
int num = new Random().nextInt(Integer.MAX_VALUE - 1);
// 判断等式是否成立
if ((num & (length - 1)) != num % length) {
fail++;
} else {
System.out.printf("2的%d次幂,length=2^%d=%d,转换成二进制:length=%s,length-1=%s/n",
multiple, multiple, length, Integer.toBinaryString(length), Integer.toBinaryString(length - 1));
}
}
if (fail == 0) {
System.out.printf("当 length 为 2 的次幂时,num & (length - 1) = num %s length 等式成立, 最大%d次幂/n",
"%", multiple - 1);
}
}
执行结果:
2的1次幂,length=2^1=2,转换成二进制:length=10,length-1=1 2的2次幂,length=2^2=4,转换成二进制:length=100,length-1=11 2的3次幂,length=2^3=8,转换成二进制:length=1000,length-1=111 2的4次幂,length=2^4=16,转换成二进制:length=10000,length-1=1111 2的5次幂,length=2^5=32,转换成二进制:length=100000,length-1=11111 2的6次幂,length=2^6=64,转换成二进制:length=1000000,length-1=111111 2的7次幂,length=2^7=128,转换成二进制:length=10000000,length-1=1111111 2的8次幂,length=2^8=256,转换成二进制:length=100000000,length-1=11111111 2的9次幂,length=2^9=512,转换成二进制:length=1000000000,length-1=111111111 2的10次幂,length=2^10=1024,转换成二进制:length=10000000000,length-1=1111111111 2的11次幂,length=2^11=2048,转换成二进制:length=100000000000,length-1=11111111111 2的12次幂,length=2^12=4096,转换成二进制:length=1000000000000,length-1=111111111111 2的13次幂,length=2^13=8192,转换成二进制:length=10000000000000,length-1=1111111111111 2的14次幂,length=2^14=16384,转换成二进制:length=100000000000000,length-1=11111111111111 2的15次幂,length=2^15=32768,转换成二进制:length=1000000000000000,length-1=111111111111111 2的16次幂,length=2^16=65536,转换成二进制:length=10000000000000000,length-1=1111111111111111 2的17次幂,length=2^17=131072,转换成二进制:length=100000000000000000,length-1=11111111111111111 2的18次幂,length=2^18=262144,转换成二进制:length=1000000000000000000,length-1=111111111111111111 2的19次幂,length=2^19=524288,转换成二进制:length=10000000000000000000,length-1=1111111111111111111 2的20次幂,length=2^20=1048576,转换成二进制:length=100000000000000000000,length-1=11111111111111111111 2的21次幂,length=2^21=2097152,转换成二进制:length=1000000000000000000000,length-1=111111111111111111111 2的22次幂,length=2^22=4194304,转换成二进制:length=10000000000000000000000,length-1=1111111111111111111111 2的23次幂,length=2^23=8388608,转换成二进制:length=100000000000000000000000,length-1=11111111111111111111111 2的24次幂,length=2^24=16777216,转换成二进制:length=1000000000000000000000000,length-1=111111111111111111111111 2的25次幂,length=2^25=33554432,转换成二进制:length=10000000000000000000000000,length-1=1111111111111111111111111 2的26次幂,length=2^26=67108864,转换成二进制:length=100000000000000000000000000,length-1=11111111111111111111111111 2的27次幂,length=2^27=134217728,转换成二进制:length=1000000000000000000000000000,length-1=111111111111111111111111111 2的28次幂,length=2^28=268435456,转换成二进制:length=10000000000000000000000000000,length-1=1111111111111111111111111111 2的29次幂,length=2^29=536870912,转换成二进制:length=100000000000000000000000000000,length-1=11111111111111111111111111111 2的30次幂,length=2^30=1073741824,转换成二进制:length=1000000000000000000000000000000,length-1=111111111111111111111111111111 当 length 为 2 的次幂时,num & (length - 1) = num % length 等式成立, 最大30次幂
根据上述结果我们看出,length为2的n次幂时,转换为二进制,最高位为1,其余位为0;length-1则所有位均为1。1和另一个数进行 与 操作时,结果为另一个数本身。
因为 length - 1 的二进制每一位均为1,所以 length - 1 与另一个数进行与操作时,另一个数的高位被截取,低位为另一个数对应位的本身。结果范围为 0 ~ length - 1 ,和取余操作结果相等。
那么桶数为什么必须是2的次幂?比如当 length = 15 时,转换为二进制为 1111 ,length - 1 = 1110 。length - 1 的二进制数最后一位为0,因此它与任何数进行 与 操作的结果,最后一位也必然是0,也即结果只能是偶数,不可能是单数,这样的话单数桶的空间就浪费掉了。同理:length = 12,二进制为1100,length - 1 的二进制则为 1011 ,那么它与任何数进行 与 操作的结果,右边第3位必然是0,这样同样会浪费一些桶空间。
综上所述, 当 length 为 2 的次幂时,num & (length - 1) = num % length 等式成立 ,并且它有如下特点:
-
位运算快于取余运算
-
length 为 2 的次幂时,
0~length - 1范围内的数都有机会成为结果,不会造成桶空间浪费
hashCode方法优化
上述代码中计算哈希值方法中有一个 无符号右移 和 异或 操作: ^ (h >>> 16) ,它的作用是什么?
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
无符号右移 和 异或 操作的主要目的是为了让生成的哈希值尽量均匀。
计算哈希桶索引表达式:hash & (length - 1),通常哈希桶数不会特别大,绝大部分都在 0 ~ 2 16 这个区间范围内,也即是小于 65536。因此哈希结果值 hash 再和 length - 1 进行 与 操作时,hash 的高 16 位部分被直接舍得掉了,未参与计算。
那么如何让 hashCode() 结果的高 16 位部分也参与运算从而让得到的桶索引更加散列、更加均匀?可以通过让 hashCode() 结果再和它的高16位进行异或操作,这样hashCode()结果的低16位和哈希结果的所有位都有了关联。当 hash & (length - 1) 表达式中 length 小于 65536 时,结果就更加散列。为什么使用 异或 操作?与 & 操作和或 | 操作的结果更偏向于 0 或者 1,而异或的结果 0 和 1 有均等的机会。
如何实现 hashCode() 结果再和它的高16位异或操作?
-
h >>> 16,将 hashCode() 结果无符号右移,所得结果高16位移到低16位,而高16位都变为0 -
(h = key.hashCode()) ^ (h >>> 16),再将 hashCode() 结果和无符号右移的结果进行异或
这样所得结果的低16位就和 hashCode() 的所有位相关。当再进行 hash & (length - 1) 运算,length 小于 65536 时,结果就更加散列。
hash & (length - 1) ,当 length = 2 n 时, hash & (length - 1) 的结果和 hash 值的低 n 位相关。
指定初始化容量
我们知道,在构造 HashMap 时,可以指定 HashMap 的初始容量,即桶数。而桶数必须是2的次幂,因此当我们传了一个非2的次幂的参数2时,计算离传入参数最近的2的次幂作为桶数。( 注:2的次幂指的是2的整数次幂 )
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
HashMap 是通过 tableSizeFor 方法来计算离输入参数最近的2的次幂。tableSizeFor 方法中使用了5次 无符号右移 和 或 操作。
假如现在我们有一个二进制数 1xxxxx ,x 可能是 0 或者 1。我们来按照上述代码进行 无符号右移 和 或 操作:
1xxxxx |= 1xxxxx >>> 1
1xxxxx | 01xxxx,1xxxxx无符号右移1位的结果 = 11xxxx,或操作结果
从上述结果看出, 无符号右移1位 然后和原数进行 或 操作,所得结果将最高2位变成1。我们再将结果 11xxxx 继续进行操作。
11xxxx |= 11xxxx >>> 2
11xxxx | 0011xx,11xxxx无符号右移2位的结果 = 1111xx,或操作结果
再进行 无符号右移2位 然后和原数进行 或 操作,所得结果将最高4位变成1。我们再将结果 1111xx 继续进行操作。
1111xx |= 1111xx >>> 4
1111xx | 000011,1111xx无符号右移4位的结果 = 111111,或操作结果
再进行 无符号右移4位 然后和原数进行 或 操作,所得结果将最高6位变成1。我们再将结果 111111 继续进行操作。
111111 |= 111111 >>> 8
111111 | 000000,111111无符号右移8位的结果 = 111111,或操作结果
再进行 无符号右移8位 然后和原数进行 或 操作,所得结果不变,最高6位还是1。我们再将 111111 继续进行操作。
111111 |= 111111 >>> 16
111111 | 000000,111111无符号右移16位的结果 = 111111,或操作结果
再进行 无符号右移16位 然后和原数进行 或 操作,所得结果不变,最高6位还是1。
从上述移位和或操作过程,我们看出,每次无符号右移然后再和原数进行或操作,所得结果保证了最高 n * 2 位都为1,其中 n 是无符号右移的位数。
为什么无符号右移 1 、 2 、 4 、 8 、 16 位并进行 或 操作后就结束了?因为 int 为 32 位数。这样反复操作后,就保证了原数最高位后面都变成了1。
二进制数,全部位都为1,再加1后,就变成了最高位为1,其余位都是0,这样的数就是2的次幂。因此 tableSizeFor 方法返回:当 n 小于最大容量 MAXIMUM_CAPACITY 时返回 n + 1。
tableSizeFor 方法中,int n = cap - 1,为什么要将 cap 减 1?如果不减1的话,当 cap 已经是2的次幂时,无符号右移和或操作后,所得结果正好是 cap 的 2 倍。
扩容方法里的位运算
HashMap 的 resize() 方法进行初始化或扩容操作。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
// 旧的数组的长度(原桶数)
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
// 数组已经初始化了,进行扩容操作
if (oldCap > 0) {
// 如果已经到达最大容量,则不再扩容
if (oldCap >= MAXIMUM_CAPACITY) {
// 阀值设置为最大 Integer 值
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 未到达最大容量
// 数组容量扩大为原来的2倍:newCap = oldCap << 1
// 阀值扩大为原来的2倍:newThr = oldThr << 1
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// 数组未初始化,且阀值大于0,此处阀值为什么大于0???
// 当构造 HashMap 时,如果传了容量参数,将根据容量参数计算的离它最近的2的次幂
// 即数组的容量暂存在阀值变量 threshold 中,详见构造器方法中的语句:
// this.threshold = tableSizeFor(initialCapacity);
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
// 数组未初始化且阀值为0,说明使用了默认构造方法进行创建对象,即 new HashMap()
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// newCap = oldThr; 语句之后未计算阀值,所以 newThr = 0
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 根据新的容量创建一个数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// 旧数组不为 null 时表示 resize 为扩容操作,否则为第一次初始化数组操作
if (oldTab != null) {
// 循环将数组中的每个结点并转移到新的数组中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
// 获取头结点,如果不为空,说明该数组中存放有元素
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 头结点 e.next == null 时,表明链表或红黑树只有一个头结点
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 如果结点为红黑树结点,则红黑树分裂,转移到新表中
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// 否则为链表,将链表中各结点原序的转移至新表中
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// (e.hash & oldCap) == 0 时,链表所在桶的索引不变
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 否则将链表转移到索引为 index + oldCap 的桶中
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
// 返回新的数组
return newTab;
}
上述代码中,扩容操作使用了左移运算
-
newCap = oldCap << 1
-
newThr = oldThr << 1
数组容量和阀值均左移1位,表示原数乘以2 1 ,即扩容为原来的2倍。
当桶中存放的为链表,在进行链表的转移时,if判断使用了如下位操作
-
if ((e.hash & oldCap) == 0)
其中 oldCap 为扩容前数组的长度,为2的次幂,也即它的二进制中最高位为1,其余位都位0。而每次扩容为原来的2倍。
例如原容量为 16,即 oldCap = 10000 ,扩容后 newCap = 32,即 newCap = 100000 。计算链表所在数组的索引表达式 hash & (length - 1) :
-
扩容前,oldCap =
10000 -
length - 1=oldCap - 1=1111 -
index=hash & (length - 1)=hash & 1111 -
数组索引下标 index 依赖于 hash 的低 4 位
-
扩容后,newCap =
100000 -
newLength - 1=newCap - 1=11111 -
newIndex=hash & (newLength - 1)=hash & 11111 -
新数组索引下标 newIndex 依赖于 hash 的低 5 位
在上述例子中,扩容后,新的数组索引和原索引是否相等取决于 hash 的第5位,如果第5位为0,则新的数组索引和原索引相同;如果第5位为1,则新的数组索引和原索引不同。
如何测试 hash 第5位为0还是为1?因为 oldCap = 10000 ,刚好第5位为1,其余位都为0,因此 e.hash & oldCap 与操作的结果,hash 第5位为0时,结果为0,hash 第5位为1时,结果为1。
综上所述,扩容后,链表的拆分分两步:
-
一条链表不需要移动,保存在原索引的桶中,包含原链表中满足
e.hash & oldCap == 0条件的结点 -
一条链表需要移动到索引为 index + oldCap 的桶中,包含原链表中不满足
e.hash & oldCap == 0条件的结点
总结回顾
最后,我们来总结回顾一下 HashMap 中位操作的重点内容。
 如果你对 JDK 源码、Spring/MyBatis框架源码分析感兴趣。可以关注我的公众号【开发圈DevOps】,搜索
如果你对 JDK 源码、Spring/MyBatis框架源码分析感兴趣。可以关注我的公众号【开发圈DevOps】,搜索 DevCircle 或扫描下边二维码进行关注。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

