G1GC 概念与性能调优
点击关注“OPPO互联网技术”,阅读更多技术干货
本文不讨论 G1 底层数据结构与算法,从 G1 GC 行为上做简要介绍 G1 的过程
Garbage-First Garbage Collector 从官网的描述来看:
G1 is a generational, incremental, parallel, mostly concurrent, stop-the-world, and evacuating garbage collector which monitors pause-time goals in each of the stop-the-world pauses. Similar to other collectors, G1 splits the heap into (virtual) young and old generations. Space-reclamation efforts concentrate on the young generation where it is most efficient to do so, with occasional space-reclamation in the old generation.
从介绍可以加粗几个重点
-
分代
-
并发
-
STW
-
在每个STW阶段关注暂停时间目标
-
回收主要集中在最有效的young generation, old generation则没这么频繁
在G1中,为了提升吞吐量,有一些操作永远是(STW) stop-the-world 的。其他的一些要长期的,如全局标记这种要全堆进行的操作与应用程序并发进行。为了让空间回收的 STW 尽可能减少,G1并行的分步的递增进行空间回收。G1通过追踪此前应用行为和垃圾回收停顿的信息来构建一个与开销有关的模型(Pause Prediction Model)。它使用这些信息停顿期间可做的工作。举个例子,G1首先回收最高效的区域(也即垃圾最满的区域,因此称为垃圾—优先)。
堆
G1把堆分成了n个大小相同的region
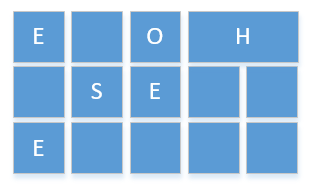
-
E 是 eden region
-
S 是 survivor region
-
O 是 old region
-
H 是 humongous (老年代可以是 humongous,可以看出,他可以跨越多个连续regions。直接分配到老年代,防止反复拷贝移动)
Java 9 以后开启的参数
自从 Java9 后,引入的统一的日志,也就是 Xlog 参数。下面是建议的 GCLog 参数:
-Xlog:gc*:file=your.log:tags,time,uptime,level:filecount=5,filesize=100
G1 的 GC 阶段
我们明白,调优的基本步骤就是
-
Measure 收集相关诊断信息 (例如收集详细的gclog,默认log level info 可以满足大部分情况)
-
Understand 理解发生了什么
-
Tune 调优
只有明白了GC内部发生了什么,才能针对性的对其进行调整。
下面通过一些正常的 GC log 来理解 GC 的三种方式 GC 做了什么。
Young Only Phase
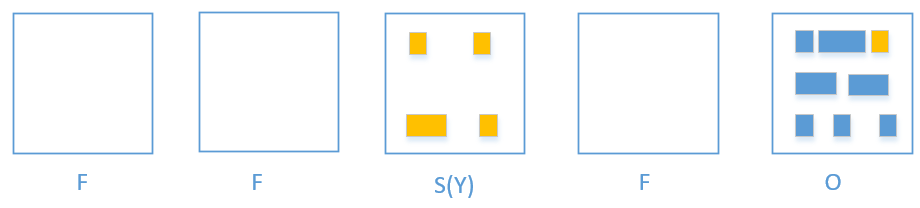
先用张图来简单理解 Young GC 过程
-
垃圾回收的过程就是 Allocated->eden; eden -> survivor; survivor -> survivor; survivor -> old;
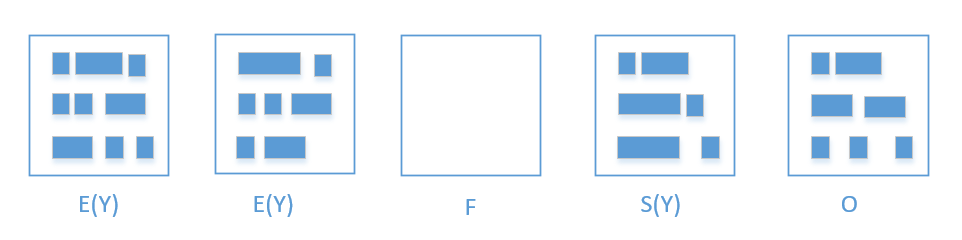
-
可以看到,这里有 eden,survivor,old 还有个 free region。
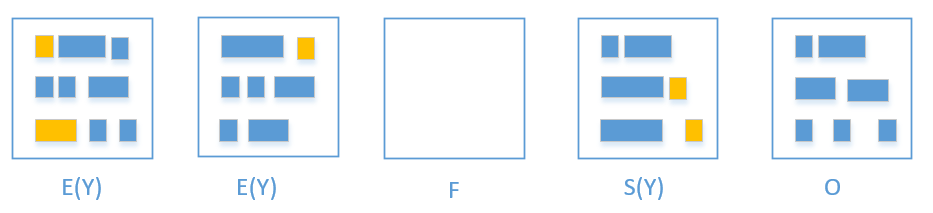
-
橙色就是活着的对象
-
G1会把橙色对象拷贝到free region
-
当拷贝完毕,free region 就会晋升为 survivor region,以前的 eden 就被释放了
-
如果 Young gc 中,花费了大量的时间
-
正常来说,大部分在 Young 的对象都不会存活很长时间
-
如果不符合这个规则 (大部分在 Young 的对象都不会存活很长时间),你可能需要调整一下 Young 区域占比。来降低 Young 对象的拷贝时间。
-
-XX:G1NewSizePercent(默认:5) Young region 最小值 -
-XX:G1MaxNewSizePercent(默认: 60) Young region 最大值
Mixed gc Phase
-
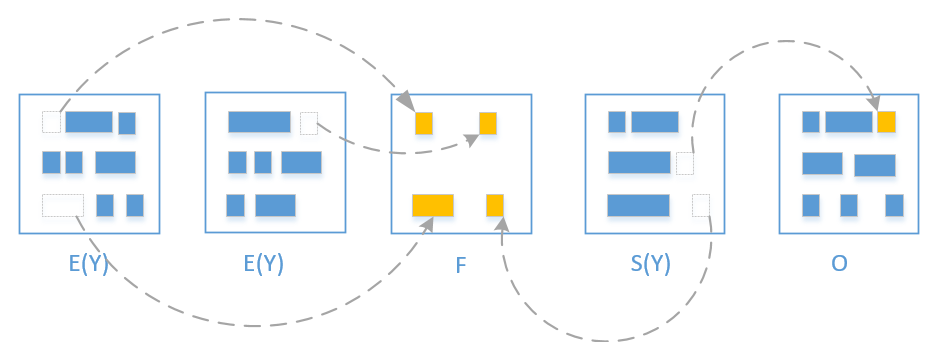
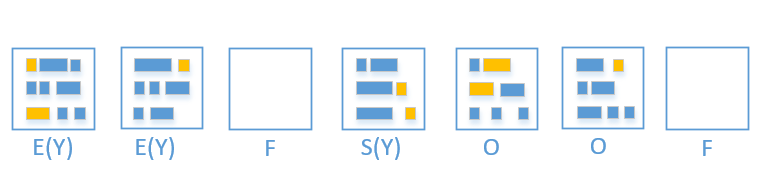
Mixed gc 会选取所有的 Young region + 收益高的若干个 Old region。
-
同样的,被回收的 region 就变回 free region 了
-
从上图可以了解到 Mixed gc 只能回收部分的老年代
-
G1 是如何选择要回收的 regions 的?
-
-XX:G1MaxNewSizePercent与 Young 关联 -
-XX:MixedGCCountTarget与 old 关联 -
-XX:MixedGCCountTarget默认是8,意味着要在8次以内回收完所有的 old region -
换句话说,如果你有 800 个 old region, 那么一次 mixed gc 最大会回收 100 个 old region
-
G1 也可以被调整成不做这么多工作,也就是回收少点,浪费堆内存,导致更堆使用
-
-XX:G1MixedGCLiveThresholdPercent(默认:85)可能会提高堆使用率 -
-XX:G1HeapWastePercent(默认:5) 如果可回收低于这个值, 那么将不会启动Mixed gc
Full gc Phase
-
Full gc 是不应该发生的
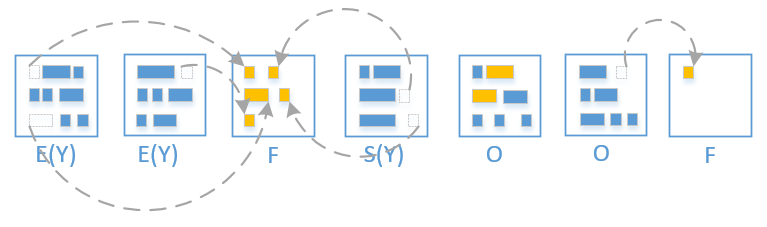
先来看看 GC 周期
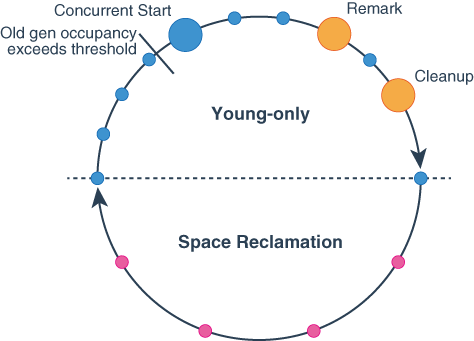
G1 有两个阶段,它会在这两个阶段往返,分别是 Young-only,Space Reclamation.
-
Young-only 包含一系列逐渐填满 old gen 的 gc
-
Space Reclamation G1 会递进地回收 old gen 的空间,同时也处理 Young region
图是来自 oracle 上对 gc 周期的描述,实心圆都表示一次 GC 停顿
-
蓝色 Young-only
-
黄色 标记过程的停顿
-
红色 Mixed gc 停顿
在几次gc后,old gen 的对象占有比超过了
InitiatingHeapOccupancyPercent
,gc就会进入并发标记准备(concurrent mark)。
-
G1 在每一次 Young 回收中都会查找活对象(有引用的对象)
-
G1 在 old region 并发查找活对象
-
叫 concurrent marking
-
可能花费很长时间
-
不会停止 Java 应用
-
G1 没有活对象的引用信息是不能进行垃圾回收的
-
Mixed gc 依赖 concurrent mark
回到 full gc,从上面简单分析得出,full gc 发生是没有足够的 free region,如果堆是足够大的,Mixed gc 没有回收足够的 old region,或者 concurrent mark 没法及时完成,都可能会导致 full gc。
gc 日志
[gc,start ] GC(78) Pause Young (Normal) (G1 Evacuation Pause)
[gc,task ] GC(78) Using 10 workers of 10 for evacuation
[gc,phases ] GC(78) Pre Evacuate Collection Set: 3.2ms
[gc,phases ] GC(78) Evacuate Collection Set: 28.8ms
[gc,phases ] GC(78) Post Evacuate Collection Set: 1.8ms
[gc,phases ] GC(78) Other: 1.1ms
[gc,heap ] GC(78) Eden regions: 538->0(871)
[gc,heap ] GC(78) Survivor regions: 69->33(76)
[gc,heap ] GC(78) Old regions: 1041->1077
[gc,heap ] GC(78) Humongous regions: 3->1
[gc,metaspace ] GC(78) Metaspace: 71777K->71777K(1114112K)
[gc ] GC(78) Pause Young (Normal) (G1 Evacuation Pause) 3300M->2220M(6144M) 34.907ms
[gc,cpu ] GC(78) User=0.24s Sys=0.05s Real=0.04s
[gc,start ] GC(79) Pause Young (Concurrent Start) (G1 Humongous Allocation)
[gc,task ] GC(79) Using 10 workers of 10 for evacuation
[gc,phases ] GC(79) Pre Evacuate Collection Set: 0.2ms
[gc,phases ] GC(79) Evacuate Collection Set: 22.3ms
[gc,phases ] GC(79) Post Evacuate Collection Set: 0.9ms
[gc,phases ] GC(79) Other: 1.8ms
[gc,heap ] GC(79) Eden regions: 569->0(656)
[gc,heap ] GC(79) Survivor regions: 33->55(113)
[gc,heap ] GC(79) Old regions: 1077->1077
[gc,heap ] GC(79) Humongous regions: 1->1
[gc,metaspace ] GC(79) Metaspace: 71780K->71780K(1114112K)
[gc ] GC(79) Pause Young (Concurrent Start) (G1 Humongous Allocation) 3357M->2264M(6144M) 25.305ms
[gc,cpu ] GC(79) User=0.21s Sys=0.00s Real=0.03s
[gc ] GC(80) Concurrent Cycle
[gc,marking ] GC(80) Concurrent Clear Claimed Marks
[gc,marking ] GC(80) Concurrent Clear Claimed Marks 0.147ms
[gc,marking ] GC(80) Concurrent Scan Root Regions
[gc,marking ] GC(80) Concurrent Scan Root Regions 16.125ms
[gc,marking ] GC(80) Concurrent Mark (373.358s)
[gc,marking ] GC(80) Concurrent Mark From Roots
[gc,task ] GC(80) Using 4 workers of 4 for marking
[gc,marking ] GC(80) Concurrent Mark From Roots 57.029ms
[gc,marking ] GC(80) Concurrent Preclean
[gc,marking ] GC(80) Concurrent Preclean 0.454ms
[gc,marking ] GC(80) Concurrent Mark (373.358s, 373.415s) 57.548ms
[gc,start ] GC(80) Pause Remark
[gc,stringtable] GC(80) Cleaned string and symbol table, strings: 36361 processed, 315 removed, symbols: 192117 processed, 500 removed
[gc ] GC(80) Pause Remark 2326M->956M(6144M) 14.454ms
[gc,cpu ] GC(80) User=0.08s Sys=0.03s Real=0.02s
[gc,marking ] GC(80) Concurrent Rebuild Remembered Sets
[gc,marking ] GC(80) Concurrent Rebuild Remembered Sets 38.843ms
[gc,start ] GC(80) Pause Cleanup
[gc ] GC(80) Pause Cleanup 974M->974M(6144M) 0.660ms
[gc,cpu ] GC(80) User=0.00s Sys=0.00s Real=0.00s
[gc,marking ] GC(80) Concurrent Cleanup for Next Mark
[gc,marking ] GC(80) Concurrent Cleanup for Next Mark 16.673ms
[gc ] GC(80) Concurrent Cycle 146.748ms
[gc,start ] GC(81) Pause Young (Prepare Mixed) (G1 Evacuation Pause)
[gc,task ] GC(81) Using 10 workers of 10 for evacuation
[gc,mmu ] GC(81) MMU target violated: 61.0ms (60.0ms/61.0ms)
[gc,phases ] GC(81) Pre Evacuate Collection Set: 0.1ms
[gc,phases ] GC(81) Evacuate Collection Set: 76.8ms
[gc,phases ] GC(81) Post Evacuate Collection Set: 0.9ms
[gc,phases ] GC(81) Other: 1.1ms
[gc,heap ] GC(81) Eden regions: 211->0(136)
[gc,heap ] GC(81) Survivor regions: 55->17(34)
[gc,heap ] GC(81) Old regions: 392->443
[gc,heap ] GC(81) Humongous regions: 3->1
[gc,metaspace ] GC(81) Metaspace: 71780K->71780K(1114112K)
[gc ] GC(81) Pause Young (Prepare Mixed) (G1 Evacuation Pause) 1320M->919M(6144M) 78.857ms
[gc,cpu ] GC(81) User=0.41s Sys=0.37s Real=0.08s
[gc,start ] GC(82) Pause Young (Mixed) (G1 Evacuation Pause)
[gc,task ] GC(82) Using 10 workers of 10 for evacuation
[gc,phases ] GC(82) Pre Evacuate Collection Set: 0.1ms
[gc,phases ] GC(82) Evacuate Collection Set: 22.1ms
[gc,phases ] GC(82) Post Evacuate Collection Set: 0.8ms
[gc,phases ] GC(82) Other: 0.9ms
[gc,heap ] GC(82) Eden regions: 136->0(142)
[gc,heap ] GC(82) Survivor regions: 17->11(20)
[gc,heap ] GC(82) Old regions: 443->367
[gc,heap ] GC(82) Humongous regions: 1->1
[gc,metaspace ] GC(82) Metaspace: 71780K->71780K(1114112K)
[gc ] GC(82) Pause Young (Mixed) (G1 Evacuation Pause) 1191M->757M(6144M) 23.970ms
[gc,cpu ] GC(82) User=0.15s Sys=0.08s Real=0.03s
[gc,start ] GC(83) Pause Young (Mixed) (G1 Evacuation Pause)
[gc,task ] GC(83) Using 10 workers of 10 for evacuation
[gc,phases ] GC(83) Pre Evacuate Collection Set: 0.1ms
[gc,phases ] GC(83) Evacuate Collection Set: 5.0ms
[gc,phases ] GC(83) Post Evacuate Collection Set: 0.8ms
[gc,phases ] GC(83) Other: 1.1ms
[gc,heap ] GC(83) Eden regions: 142->0(783)
[gc,heap ] GC(83) Survivor regions: 11->10(20)
[gc,heap ] GC(83) Old regions: 367->294
[gc,heap ] GC(83) Humongous regions: 1->1
[gc,metaspace ] GC(83) Metaspace: 71780K->71780K(1114112K)
上面是连续几次GC的日志,可以对照着 gc 周期来看。为了方便排版,把时间相关的tag给精简掉了。
-
GC(78) 是一次普通的young gc,里面信息有各种 region 的变化
-
这里简单说一下 humongous 对象的处理
-
humongous 对象在G1中是被特殊对待的,G1 只决定它们是否生存,回收他们占用的空间,从不会移动它们
-
Young-Only 阶段,humongous regions 可能会被回收
-
Space-Reclamation,humongous regions 可能会被回收
-
GC(79) 开始进入并发阶段
-
GC(80) 完成了 Cleanup,紧接着一个 Prepare Mixed GC(81) 的垃圾收集,对应周期虚线右边的蓝实心圆
-
GC(82) 之后就是 Space Reclamation 阶段了,多个 Mixed GC 会进行
根据日志,可以简单看到每个步骤花费的时间,以及对应区域垃圾的回收情况,结合GC参数,可以定位出什么问题,针对性的调整参数。
吞吐量跟低延时是无法兼得的,低延时意味着GC工作会更加频繁,相对的,会占用应用的资源,吞吐量降低。需要大吞吐量,那么GC工作就会减少,相对的,每次回收的垃圾就会多,暂停时间就会增加,延时就会增加。
-XX:MaxGCPauseMillis
G1 会尽量满足这个参数设定的目标时间,通过此参数可以平衡应用需要的吞吐量以及延时。
最后
本文主要参考资料是官方的文章和文档,没涉及到复杂的内部实现,新版的JDK除了对G1进行了改良之外,还推出了几种新的。
-
Epsilon GC (no-op),无操作垃圾回收器,简单点就是不回收垃圾,等堆空间分配完了,jvm也就停止了
-
zgc 超大堆垃圾回收器,暂停不超过10ms,支持T级别的堆
-
Shenandoah 同样也是低延迟垃圾回收器
由于知识简陋,难免会有勘误,欢迎讨论。
参考资料
1.https://docs.oracle.com/en/java/javase/11/gctuning/garbage-first-garbage-collector.html
2. https://chriswhocodes.com/hotspot_options_jdk11.html
3.https://www.oracle.com/technetwork/tutorials/tutorials-1876574.html
☆ END ☆
招聘信息
OPPO互联网技术领域招聘多个岗位:
商业中心前端团队专注于广告投放管理,快应用,快游戏,H5页面以及node.js的开发工作。诚邀具备以上技能的前端开发者加入我们,共同建设智能广告平台。
简历投递:liuke#oppo.com
互联网广告机制策略团队专注于商业化核心机制与策略算法的建设与优化,围绕商业变现效率提升、广告生态建设及用户体验提升等维度进行深度挖掘与优化。诚邀熟悉机器学习、数据挖掘、博弈论、控制论等中一项或多项、对广告算法有热情的小伙伴加入我们,共同定义和打造新一代广告算法。
简历投递:liuxiang10#oppo.com
广告后台团队专注于广告投放管理、播放检索、计费统计等广告系统核心服务研发工作, 诚邀具备分布式系统架构设计与调优能力,对高可用/高并发系统有实践经验,对计算广告有浓厚兴趣的同学加入。
简历投递:chenquan#oppo.com
客户端团队 致力于研究Android手机上应用、游戏的商业化变现解决方案、协助应用、游戏通过商业化SDK快速实现变现盈利,诚邀对于Android应用、游戏商业化变现解决方案感兴趣、满三年开发经验的Android应用开发者加入,与团队和业务一起成长。
简历投递:liushun#oppo.com
数据标签团队致力于穿透大数据来理解每个OPPO用户的商业兴趣。数据快速拓展和深挖中,诚邀对数据分析、大数据处理、机器学习/深度学习、NLP等有两年以上经验的您加入我们,与团队和业务一同成长!
简历投递:ping.wang#oppo.com
你可能还喜欢
本文来自OPPO商业中心团队,你可能还喜欢他们的其他文章(点击阅读原文查看更多):
数据不平衡与SMOTE算法
浅谈广告系统预算控制(Budget Pacing)
广告场景中的机器学习应用
广告中异常检测问题以及样本不均衡代价敏感等解决途径
Spark ML的特征处理实战
主流Gradient Boosting算法对比
更多技术干货
扫码关注
OPPO互联网技术

我就知道你“在看”
正文到此结束
- 本文标签: tab 互联网 管理 Java 9 http IO 模型 root 广告 大数据 Android ask 深度学习 分布式系统 tag java Oracle 数据 HTML 统计 ORM 高可用 并发 tar 开发者 智能 src 前端团队 高并发 Full GC UI CTO build 招聘 分布式 JVM js 系统架构 空间 开发 文章 id 架构设计 https Region 时间 参数 数据挖掘 垃圾回收 mongo node cat Node.js list ACE Collection 专注
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

