DDD分层架构的三种模式
引言
在讨论DDD分层架构的模式之前,我们先一起回顾一下DDD和分层架构的相关知识。
DDD
DDD(Domain Driven Design,领域驱动设计)作为一种软件开发方法,它可以帮助我们设计高质量的软件模型。在正确实现的情况下,我们通过DDD完成的设计恰恰就是软件的工作方式。
UL(Ubiquitous Language,通用语言)是团队共享的语言,是DDD中最具威力的特性之一。不管你在团队中的角色如何,只要你是团队的一员,你都将使用UL。由于UL的重要性,所以需要让每个概念在各自的上下文中是清晰无歧义的,于是DDD在战略设计上提出了模式BC(Bounded Context,限界上下文)。UL和BC同时构成了DDD的两大支柱,并且它们是相辅相成的,即UL都有其确定的上下文含义,而BC中的每个概念都有唯一的含义。
一个业务领域划分成若干个BC,它们之间通过Context Map进行集成。BC是一个显式的边界,领域模型便存在于这个边界之内。领域模型是关于某个特定业务领域的软件模型。通常,领域模型通过对象模型来实现,这些对象同时包含了数据和行为,并且表达了准确的业务含义。
从广义上来讲,领域即是一个组织所做的事情以及其中所包含的一切,表示整个业务系统。由于“领域模型”包含了“领域”这个词,我们可能会认为应该为整个业务系统创建一个单一的、内聚的和全功能式的模型。然而,这并不是我们使用DDD的目标。正好相反,领域模型存在于BC内。
在微服务架构实践中,人们大量地使用了DDD中的概念和技术:
- 微服务中应该首先建立UL,然后再讨论领域模型。
- 一个微服务最大不要超过一个BC,否则微服务内会存在有歧义的领域概念。
- 一个微服务最小不要小于一个聚合,否则会引入分布式事务的复杂度。
- 微服务的划分过程类似于BC的划分过程,每个微服务都有一个领域模型。
- 微服务间的集成可以通过Context Map来完成,比如ACL(Anticorruption Layer,防腐层)。
- 微服务间最好采用Domain Event(领域事件)来进行交互,使得微服务可以保持松耦合。
- ……
分层架构
分层架构的一个重要原则是每层只能与位于其下方的层发生耦合。分层架构可以简单分为两种,即严格分层架构和松散分层架构。在严格分层架构中,某层只能与位于其直接下方的层发生耦合,而在松散分层架构中,则允许某层与它的任意下方层发生耦合。
分层架构的好处是显而易见的。首先,由于层间松散的耦合关系,使得我们可以专注于本层的设计,而不必关心其他层的设计,也不必担心自己的设计会影响其它层,对提高软件质量大有裨益。其次,分层架构使得程序结构清晰,升级和维护都变得十分容易,更改某层的具体实现代码,只要本层的接口保持稳定,其他层可以不必修改。即使本层的接口发生变化,也只影响相邻的上层,修改工作量小且错误可以控制,不会带来意外的风险。
要保持程序分层架构的优点,就必须坚持层间的松散耦合关系。设计程序时,应先划分出可能的层次,以及此层次提供的接口和需要的接口。设计某层时,应尽量保持层间的隔离,仅使用下层提供的接口。
关于分层架构的优点,Martin Fowler在《Patterns of Enterprise Application Architecture》一书中给出了答案:
- 开发人员可以只关注整个结构中的某一层。
- 可以很容易的用新的实现来替换原有层次的实现。
- 可以降低层与层之间的依赖。
- 有利于标准化。
- 利于各层逻辑的复用。
“金无足赤,人无完人”,分层架构也不可避免具有一些缺陷:
- 降低了系统的性能。这是显然的,因为增加了中间层,不过可以通过缓存机制来改善。
- 可能会导致级联的修改。这种修改尤其体现在自上而下的方向,不过可以通过依赖倒置来改善。
在每个BC中为了凸显领域模型,DDD中提出了分层架构模式。最近几年,笔者在实践DDD的过程中,也经常使用分层架构模式,本文主要分享DDD分层架构中比较经典的三种模式。
模式一:四层架构
Eric Evans在《领域驱动设计-软件核心复杂性应对之道》这本书中提出了传统的四层架构模式,如下图所示:
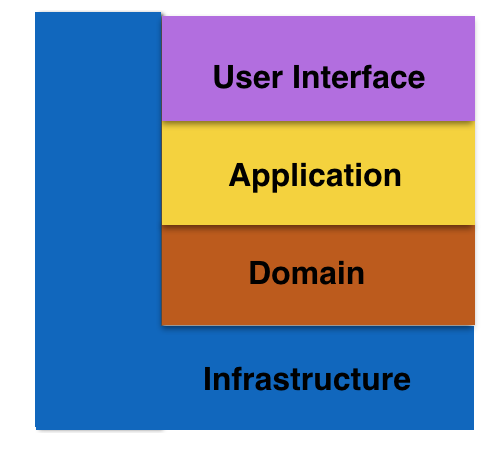
- User Interface为用户界面层(或表示层),负责向用户显示信息和解释用户命令。这里指的用户可以是另一个计算机系统,不一定是使用用户界面的人。
- Application为应用层,定义软件要完成的任务,并且指挥表达领域概念的对象来解决问题。这一层所负责的工作对业务来说意义重大,也是与其它系统的应用层进行交互的必要渠道。应用层要尽量简单,不包含业务规则或者知识,而只为下一层中的领域对象协调任务,分配工作,使它们互相协作。它没有反映业务情况的状态,但是却可以具有另外一种状态,为用户或程序显示某个任务的进度。
- Domain为领域层(或模型层),负责表达业务概念,业务状态信息以及业务规则。尽管保存业务状态的技术细节是由基础设施层实现的,但是反映业务情况的状态是由本层控制并且使用的。领域层是业务软件的核心,领域模型位于这一层。
- Infrastructure层为基础实施层,向其他层提供通用的技术能力:为应用层传递消息,为领域层提供持久化机制,为用户界面层绘制屏幕组件,等等。基础设施层还能够通过架构框架来支持四个层次间的交互模式。
传统的四层架构都是限定型松散分层架构,即Infrastructure层的任意上层都可以访问该层(“L”型),而其它层遵守严格分层架构。
笔者在四层架构模式的实践中,对于分层的本地化定义主要为:
- User Interface层主要是Restful消息处理,配置文件解析,等等。
- Application层主要是多进程管理及调度,多线程管理及调度,多协程调度和状态机管理,等等。
- Domain层主要是领域模型的实现,包括领域对象的确立,这些对象的生命周期管理及关系,领域服务的定义,领域事件的发布,等等。
- Infrastructure层主要是业务平台,编程框架,第三方库的封装,基础算法,等等。
说明:严格意义上来说,User Interface指的是用户界面,Restful消息和配置文件解析等处理应该放在Application层,User Interface层没有的话就空缺。但User Interface也可以理解为用户接口,所以将Restful消息和配置文件解析等处理放在User Interface层也行。
模式二:五层架构
James O. Coplien和Trygve Reenskaug在2009年发表了一篇论文《DCI架构:面向对象编程的新构想》,标志着DCI架构模式的诞生。有趣的是James O. Coplien也是MVC架构模式的创造者,这个大叔一辈子就干了两件事,即年轻时创造了MVC和年老时创造了DCI,其他时间都在思考,让我辈望尘莫及。
面向对象编程的本意是将程序员与用户的视角统一于计算机代码之中:对提高可用性和降低程序的理解难度来说,都是一种恩赐。可是虽然对象很好地反映了结构,但在反映系统的动作方面却失败了,DCI的构想是期望反映出最终用户的认知模型中的角色以及角色之间的交互。
传统上,面向对象编程语言拿不出办法去捕捉对象之间的协作,反映不了协作中往来的算法。就像对象的实例反映出领域结构一样,对象的协作与交互同样是有结构的。协作与交互也是最终用户心智模型的组成部分,但你在代码中找不到一个内聚的表现形式去代表它们。在本质上,角色体现的是一般化的、抽象的算法。角色没有血肉,并不能做实际的事情,归根结底工作还是落在对象的头上,而对象本身还担负着体现领域模型的责任。
人们心目中对“对象”这个统一的整体却有两种不同的模型,即“系统是什么”和“系统做什么”,这就是DCI要解决的根本问题。用户认知一个个对象和它们所代表的领域,而每个对象还必须按照用户心目中的交互模型去实现一些行为,通过它在用例中所扮演的角色与其他对象联结在一起。正因为最终用户能把两种视角合为一体,类的对象除了支持所属类的成员函数,还可以执行所扮演角色的成员函数,就好像那些函数属于对象本身一样。换句话说,我们希望把角色的逻辑注入到对象,让这些逻辑成为对象的一部分,而其地位却丝毫不弱于对象初始化时从类所得到的方法。我们在编译时就为对象安排好了扮演角色时可能需要的所有逻辑。如果我们再聪明一点,在运行时才知道了被分配的角色,然后注入刚好要用到的逻辑,也是可以做到的。
算法及角色-对象映射由Context拥有。Context“知道”在当前用例中应该找哪个对象去充当实际的演员,然后负责把对象“cast”成场景中的相应角色(cast 这个词在戏剧界是选角的意思,此处的用词至少符合该词义,另一方面的用意是联想到cast 在某些编程语言类型系统中的含义)。在典型的实现里,每个用例都有其对应的一个Context 对象,而用例涉及到的每个角色在对应的Context 里也都有一个标识符。Context 要做的只是将角色标识符与正确的对象绑定到一起。然后我们只要触发Context里的“开场”角色,代码就会运行下去。
于是我们有了完整的DCI架构(Data、Context和Interactive三层架构):
- Data层描述系统有哪些领域概念及其之间的关系,该层专注于领域对象的确立和这些对象的生命周期管理及关系,让程序员站在对象的角度思考系统,从而让“系统是什么”更容易被理解。
- Context层:是尽可能薄的一层。Context往往被实现得无状态,只是找到合适的role,让role交互起来完成业务逻辑即可。但是简单并不代表不重要,显示化context层正是为人去理解软件业务流程提供切入点和主线。
- Interactive层主要体现在对role的建模,role是每个context中复杂的业务逻辑的真正执行者,体现“系统做什么”。role所做的是对行为进行建模,它联接了context和领域对象。由于系统的行为是复杂且多变的,role使得系统将稳定的领域模型层和多变的系统行为层进行了分离,由role专注于对系统行为进行建模。该层往往关注于系统的可扩展性,更加贴近于软件工程实践,在面向对象中更多的是以类的视角进行思考设计。
DCI目前广泛被看作是对DDD的一种发展和补充,用在基于面向对象的领域建模上。显式的对role进行建模,解决了面向对象建模中的充血模型和贫血模型之争。DCI通过显式的用role对行为进行建模,同时让role在context中可以和对应的领域对象进行绑定(cast),从而既解决了数据边界和行为边界不一致的问题,也解决了领域对象中数据和行为高内聚低耦合的问题。
面向对象建模面临的一个棘手问题是数据边界和行为边界往往不一致。遵循模块化的思想,我们通过类将行为和其紧密耦合的数据封装在一起。但是在复杂的业务场景下,行为往往跨越多个领域对象,这样的行为如果放在某一个对象中必然会导致别的对象需要向该对象暴漏其内部状态。所以面向对象发展的后来,领域建模出现两种派别之争,一种倾向于将跨越多个领域对象的行为建模在领域服务中。如果这种做法使用过度,则会导致领域对象变成只提供一堆get方法的哑对象,这种建模结果被称之为贫血模型。而另一派则坚定的认为方法应该属于领域对象,所以所有的业务行为仍然被放在领域对象中,这样导致领域对象随着支持的业务场景变多而变成上帝类,而且类内部方法的抽象层次很难一致。另外由于行为边界很难恰当,导致对象之间数据访问关系也比较复杂,这种建模结果被称之为充血模型。
关于多角色对象,举个生活中的例子:
人有多重角色,不同的角色履行的职责不同:
- 作为父母:我们要给孩子讲故事,陪他们玩游戏,哄它们睡觉。
- 作为子女:我们要孝敬父母,听取他们的人生建议。
- 作为下属:我们要服从上司的工作安排,并高质量完成任务。
- 作为上司:我们要安排下属的工作,并进行培养和激励。
- ……
这里人(大对象)聚合了多个角色(小类),人在某种场景下,只能扮演特定的角色:
- 在孩子面前,我们是父母。
- 在父母面前,我们是子女。
- 在上司面前,我们是下属。
- 在下属面前,我们是上司。
- ……
引入DCI后,DDD四层架构模式中的Domain层变薄了,以前Domain层对应DCI中的三层,而现在:
- Domain层只保留了DCI中的Data层和Interaction层,我们在实践中通常将这两层使用目录隔离,即通过两个目录object和role来分离层Data和Interaction。

- DCI中的Context层从Domain层上移变成Context层。
因此,DDD分层架构模式就变成了五层,如下图所示:
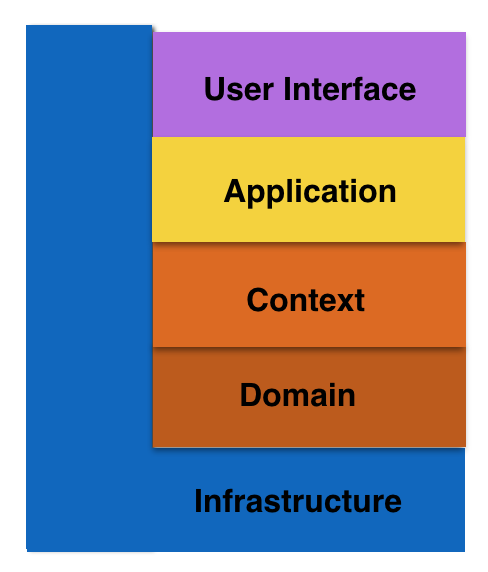
笔者在实践中,将这五层的本地化定义为:
- User Interface是用户接口层,主要用于处理用户发送的Restful请求和解析用户输入的配置文件等,并将信息传递给Application层的接口。
- Application层是应用层,负责多进程管理及调度、多线程管理及调度、多协程调度和维护业务实例的状态模型。当调度层收到用户接口层的请求后,委托Context层与本次业务相关的上下文进行处理。
- Context是环境层,以上下文为单位,将Domain层的领域对象cast成合适的role,让role交互起来完成业务逻辑。
- Domain层是领域层,定义领域模型,不仅包括领域对象及其之间关系的建模,还包括对象的角色role的显式建模。
- Infrastructure层是基础实施层,为其他层提供通用的技术能力:业务平台,编程框架,持久化机制,消息机制,第三方库的封装,通用算法,等等。
DDD五层架构模式讨论完了吗?故事还没有结束……
笔者参与的很多DDD落地实践,都是面向控制面或管理面且消息交互比较多的系统。这类系统的一次业务,包含一组同步消息或异步消息构成的序列,如果都放在Context层,会导致该层的代码比较复杂,于是我们考虑:
- Context层在面向控制面或管理面且消息交互比较多的系统中又分裂成两层,即Context层和大Context层。
- Context层处理单位为Action,对应一条同步消息或异步消息。
- 大Context层对应一个事务处理,由一个Action序列组成,一般通过Transaction DSL实现,所以我们习惯把大Context层叫做Transaction DSL层。
- Application层在面向控制面或管理面且消息交互比较多的系统中经常会做一些调度相关的工作,所以我们习惯把Application层叫做Scheduler层。
因此,在面向控制面或管理面且消息交互比较多的系统中,DDD分层架构模式就变成了六层,如下图所示:
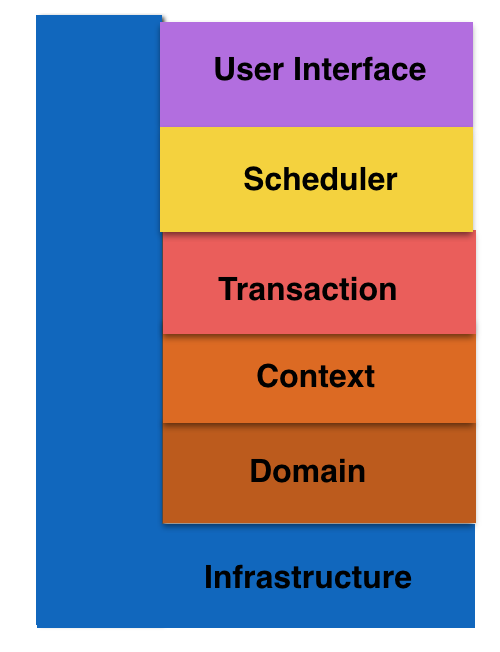
笔者在实践中,将这六层的本地化定义为:
- User Interface是用户接口层,主要用于处理用户发送的Restful请求和解析用户输入的配置文件等,并将信息传递给Scheduler层的接口。
- Scheduler是调度层,负责多进程管理及调度、多线程管理及调度、多协程调度和维护业务实例的状态模型。当调度层收到用户接口层的请求后,委托Transaction层与本次操作相关的事务进行处理。
- Transaction是事务层,对应一个业务流程,比如UE Attach,将多个同步消息或异步消息的处理序列组合成一个事务,而且在大多场景下,都有选择结构。万一事务执行失败,则立即进行回滚。当事务层收到调度层的请求后,委托Context层的Action进行处理,常常还伴随使用Context层的Specification(谓词)进行Action的选择。
- Context是环境层,以Action为单位,处理一条同步消息或异步消息,将Domain层的领域对象cast成合适的role,让role交互起来完成业务逻辑。环境层通常也包括Specification的实现,即通过Domain层的知识去完成一个条件判断。
- Domain层是领域层,定义领域模型,不仅包括领域对象及其之间关系的建模,还包括对象的角色role的显式建模。
- Infrastructure层是基础实施层,为其他层提供通用的技术能力:业务平台,编程框架,持久化机制,消息机制,第三方库的封装,通用算法,等等。
事务层的核心是事务模型,事务模型的框架代码一般放在基础设施层。关于事务模型,笔者以前分享过一篇文章——《 Golang事务模型 》,感兴趣的同学可以看看。
综上所述,DDD六层架构可以看做是DDD五层架构在特定领域的变体,我们统称为DDD五层架构,而DDD五层架构与传统的四层架构类似,都是限定型松散分层架构。
模式三:六边形架构
有一种方法可以改进分层架构,即依赖倒置原则(Dependency Inversion Principle,DIP),它通过改变不同层之间的依赖关系达到改进目的。
依赖倒置原则由Robert C. Martin提出,正式定义为:
- 高层模块不应该依赖于底层模块,两者都应该依赖于抽象。
- 抽象不应该依赖于细节,细节应该依赖于抽象。
根据该定义,DDD分层架构中的低层组件应该依赖于高层组件提供的接口,即无论高层还是低层都依赖于抽象,整个分层架构好像被推平了。如果我们把分层架构推平,再向其中加入一些对称性,就会出现一种具有对称性特征的架构风格,即六边形架构。六边形架构是Alistair Cockburn在2005年提出的,在这种架构中,不同的客户通过“平等”的方式与系统交互。需要新的客户吗?不是问题。只需要添加一个新的适配器将客户输入转化成能被系统API所理解的参数就行。同时,对于每种特定的输出,都有一个新建的适配器负责完成相应的转化功能。
六边形架构也称为端口与适配器,如下图所示:
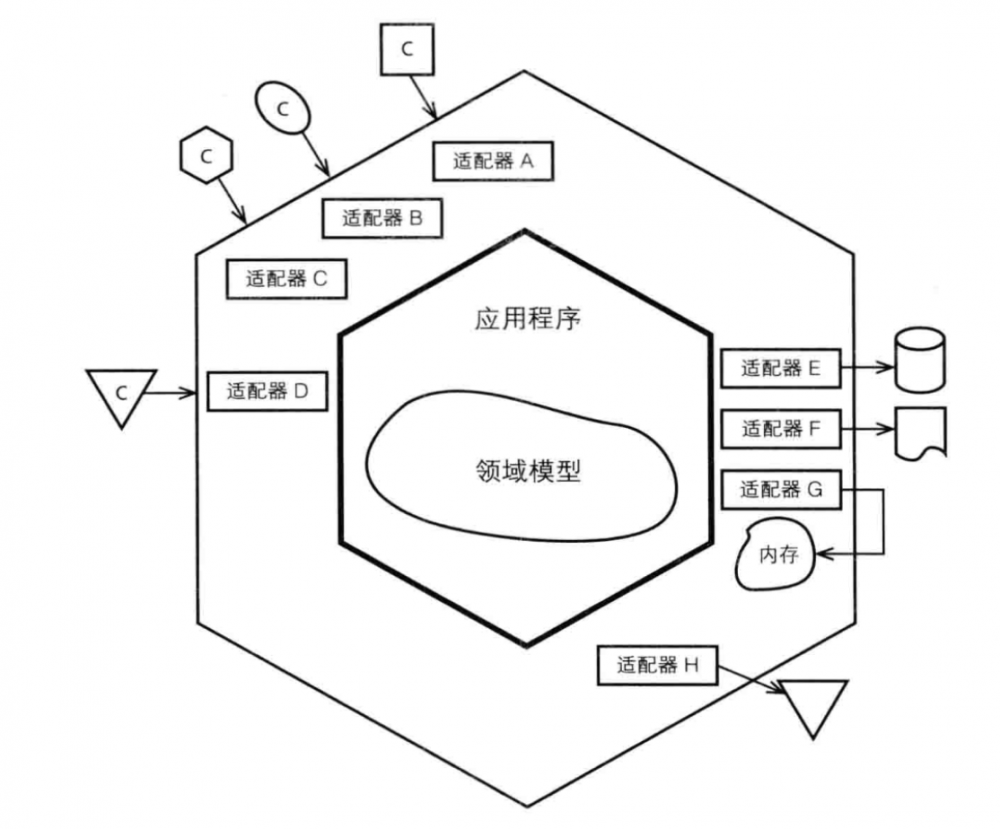
六边形每条不同的边代表了不同类型的端口,端口要么处理输入,要么处理输出。对于每种外界类型,都有一个适配器与之对应,外界通过应用层API与内部进行交互。上图中有3个客户请求均抵达相同的输入端口(适配器A、B和C),另一个客户请求使用了适配器D。假设前3个请求使用了HTTP协议(浏览器、REST和SOAP等),而后一个请求使用了AMQP协议(比如RabbitMQ)。端口并没有明确的定义,它是一个非常灵活的概念。无论采用哪种方式对端口进行划分,当客户请求到达时,都应该有相应的适配器对输入进行转化,然后端口将调用应用程序的某个操作或者向应用程序发送一个事件,控制权由此交给内部区域。
应用程序通过公共API接收客户请求,使用领域模型来处理请求。我们可以将DDD战术设计的建模元素Repository的实现看作是持久化适配器,该适配器用于访问先前存储的聚合实例或者保存新的聚合实例。正如图中的适配器E、F和G所展示的,我们可以通过不同的方式实现资源库,比如关系型数据库、基于文档的存储、分布式缓存或内存存储等。如果应用程序向外界发送领域事件消息,我们将使用适配器H进行处理。该适配器处理消息输出,而上面提到的处理AMQP消息的适配器则是处理消息输入的,因此应该使用不同的端口。
我们在实际的项目开发中,不同层的组件可以同时开发。当一个组件的功能明确后,就可以立即启动开发。由于该组件的用户有多个,并且这些用户的侧重点不同,所以需要提供多个不同的接口。同时,这些用户的认识也是不断深入的,可能会多次重构相关的接口。于是,组件的多个用户经常会找组件的开发者讨论这些问题,无形中降低了组件的开发效率。
我们换一种方式,组件的开发者在明确了组件的功能后就专注于功能的开发,确保功能稳定和高效。组件的用户自己定义组件的接口(端口),然后基于接口写测试,并不断演进接口。在跨层集成测试时,由组件开发者或用户再开发一个适配器就可以了。
六边形架构模式的演变
尽管六边形架构模式已经很好,但是没有最好只有更好,演变没有尽头。在六边形架构模式提出后的这些年,又依次衍生出三种六边形架构模式的变体,感兴趣的读者可以自行学习:
- Jeffrey Palermo在2008年提出了洋葱架构,六边形架构是洋葱架构的一个超集。
- Robert C. Martin在2012年提出了干净架构(Clean Architecture),这是六边形架构的一个变体。
- Russ Miles在2013年提出了Life Preserver设计,这是一种基于六边形架构的设计。
小结
本文先和读者一起回顾了DDD和分层架构的相关知识,然后将DDD分层架构中常用的三种模式(四层架构、五层架构和六边形架构)结合实践经验分别进行详细阐述,使得读者深刻理解DDD分层架构模式,以便在微服务的开发实践中根据具体情况选择最合适的DDD分层架构模式,从而交付结构清晰且易维护的软件产品。
原文链接: https://www.jianshu.com/p/a775836c7e25 ,作者:张晓龙
正文到此结束
- 本文标签: 软件 http IO 专注 质量 上帝 NSA App 组织 src action层 模型 端口 进程 数据 时间 list 同步 Action rabbitmq 测试 线程 开发者 代码 分布式事务 对象初始化 文章 高可用 微服务 协议 数据库 UI 多线程 Architect 分布式 适配器 编译 配置 API 实例 开发 Enterprise 希望 缓存 目录 https map SOA DOM 参数 ACE MQ amqp struct cat RESTful 解析 REST 生命 HTTP协议 本质 ip 产品 管理 程序员
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

