DDD极简教程
概述
DDD(Domain-Driven Design 领域驱动设计)是由Eric Evans最先提出,目的是对软件所涉及到的领域进行建模,以应对系统规模过大时引起的软件复杂性的问题。整个过程大概是这样的,开发团队和领域专家一起通过通用语言(Ubiquitous Language)去理解和消化领域知识,从领域知识中提取和划分为一个一个的子领域(核心子域,通用子域,支撑子域),并在子领域上建立模型,再重复以上步骤,这样周而复始,构建出一套符合当前领域的模型。
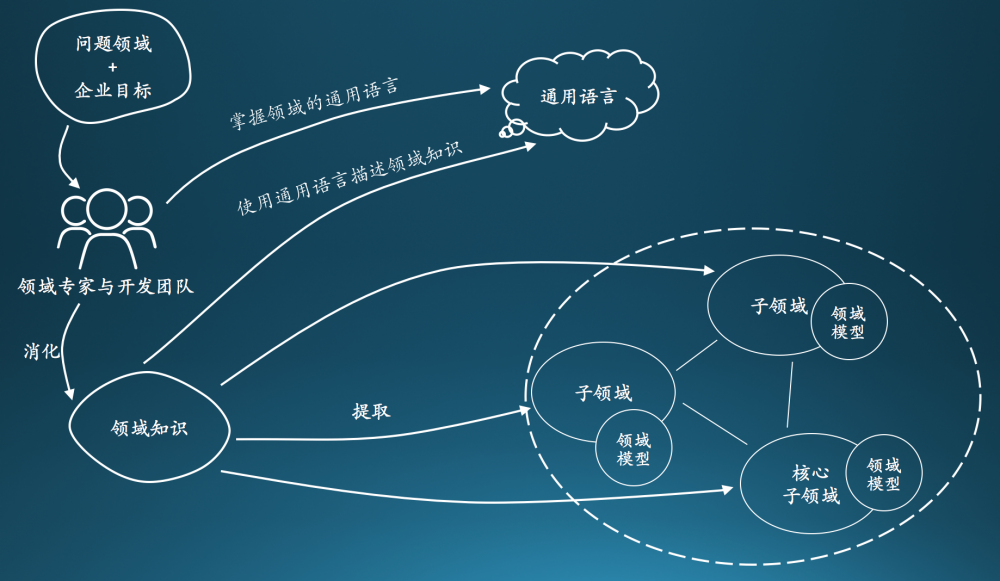
DDD概述
这里需要注意几点:
- 通用语言是一个很泛的概念,它作为一种沟通工具,在开发团队内部,开发团队与领域专家之间使用。它包含了自然语言、文档和图表(不一定是标准的UML图,只要能表达出领域知识的都可以)等内容。对通用语言中名词,动词的使用需要认真考量,因为这些名词和动词会作为后面模型的指导命名。
- 通用语言中定义的术语在一个 限界上下文(bounded context)中不能存在二义性。同一个事物在不同的限界上下文中因为所关注的侧重点不同,所以所表达出的概念是不同的,但在同一个限界上下文中应该表示的是一个概念。比如用户在微信中的聊天场景,朋友圈以及支付场景中所有表达的概念就应该是不同的,聊天场景关注的是用户间的聊天内容,而支付场景关注的是用户的账户余额。
- 一个子域可以包含多个限界上下文。
- 模型(Entity,值对象,Service,Aggregate root)是存在于限界上下文中的。
分层架构
DDD中将系统分为UI层,应用层,领域层以及基础设施层。
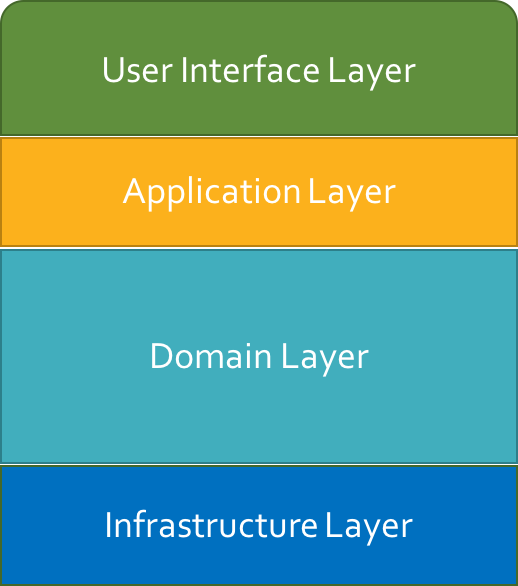
分层架构
上图中,应用层是很薄的一层,因为它只负责接收UI层传来的参数和路由到对应的领域模型,它不负责处理具体的业务逻辑。系统的业务逻辑放在了领域层中,所以,领域层在系统架构中占据了很大的面积。
在层级结构中,上层模块调用下层模块提供的服务,这里就会存在一种依赖关系,Rebort C. Martin提出的依赖倒置原则大致是如下:
- 上层模块不应该依赖于下层模块,两者都应该依赖于抽象;
- 抽象不应该依赖于实现,实现应该依赖于抽象。
这是一个面向接口编程的思想,抽象说的是抽象类或接口,实现就是具体实现了这些抽象的实现类。翻译成白话文是这样的,上下层之间应该通过接口来通讯,接口定义的位置就决定了上下层的依赖关系是否倒置。比如Application层和Domain层进行通讯,接口与接口的实现类都定义在Domain层中,这是正常的面向接口编程,不存在倒置关系。而Domain层和基础设施层进行通讯时,原本是Domain层去依赖基础设施层,如果我们将接口定义在Domain层,而实现类定义在基础设施层,那么,基础设施层就将依赖Domain层,这就是“倒置”这个词的来由。实际上,我们在做这样分层架构设计时,都是将接口定义在Domain层的。
DDD元素
在使用DDD设计系统时,主要包括Entity,Value Object,Service,Aggregate,Repository,Factory,Domain Event,Moudle等元素。
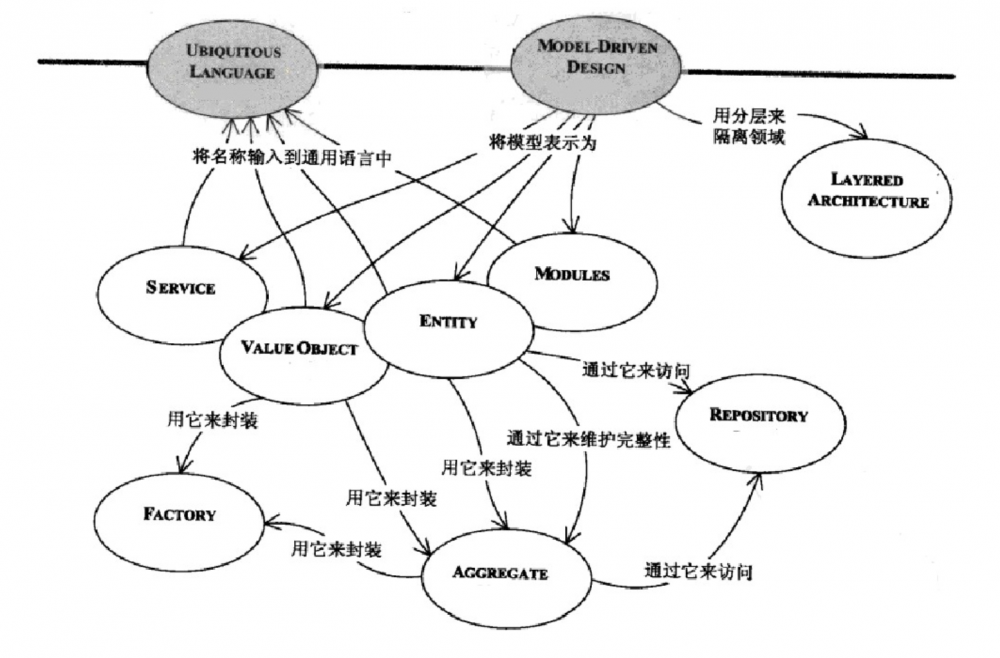
DDD元素
在建模时,Entity可以用来代表一个事物。既然Entity是用来代表一个事物的,那么它就应该有一个唯一值来标识这个事物,同时,他还能记录这个事物状态的变化。比如:Id为5的Person对象,它的名字是张三,过两天,他将自己的名字改为李四。但是,这个人(Id=5)还是这个人(Id=5),只是他名字的状态以及发生了变化,而这个变化后的状态被Person这个Entity记录了下来。
Value Object是用来描述事物的某一方面的特征,所以它是一个无状态的,且是一个没有标识符的对象,这是和Entity的本质区别。拿订单来说,一张订单在系统中应该有一个唯一的标识,且具有状态,所以订单是一个Entity对象,而这张订单共¥100元,则是描述了这个订单的总额特征,¥100元可以用值对象表示为{100,¥},及金额和币种的组合。{100,¥}在任何限界上下文中都描述的是¥100元,是因为他们比较的是里面的内容(金额和币种),而上面的张三在修了名后,还是原来的那个人,是因为它比较的是唯一标示ID的值。
Aggregate是一组相关对象的集合,它作为数据修改的基本单元,为数据修改提供了一个边界。每个聚合都有一个根和一个边界,根也是一个实体,聚合边界以外的对象只能通过根对聚合内部元素操作。聚合将一组相关的对象内聚到一起,从而将系统的复杂程度降低。
repository用来存储聚合,相当于每一个聚合都应该有一个仓库实例。Entity和Value Object都应该具有行为,而有些行为从语义上讲,不适合放到这两个对象中,所以就单独抽象了一个Service对象,用来存放这些行为。Factory是用来生成聚合的,当生成一个聚合的步骤过于复杂时,可以将其生成过程放在工厂中。
原文链接: https://www.jianshu.com/p/b0379067c978 ,作者:书上得来终觉浅
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

