大数据方向学习面试知识图谱
正所谓,无招胜有招。
愿读到这篇文章的技术人早日明白并且脱离技术本身,早登彼岸。
一切技术最终只 是雕虫小 技 。
大纲
本系列主题是大数据开发面试指南,旨在为大家提供一个大数据学习的基本路线,完善数据开发的技术栈,以及我们面试一个大数据开发岗位的时候,哪些东西是重点考察的,这些公司更希望面试者具备哪些技能。
本文不会对某一个知识点进行详细的展开,后续会陆续出专题文章,希望读者能当成一个学习或者复习的大纲,用以查漏补缺。
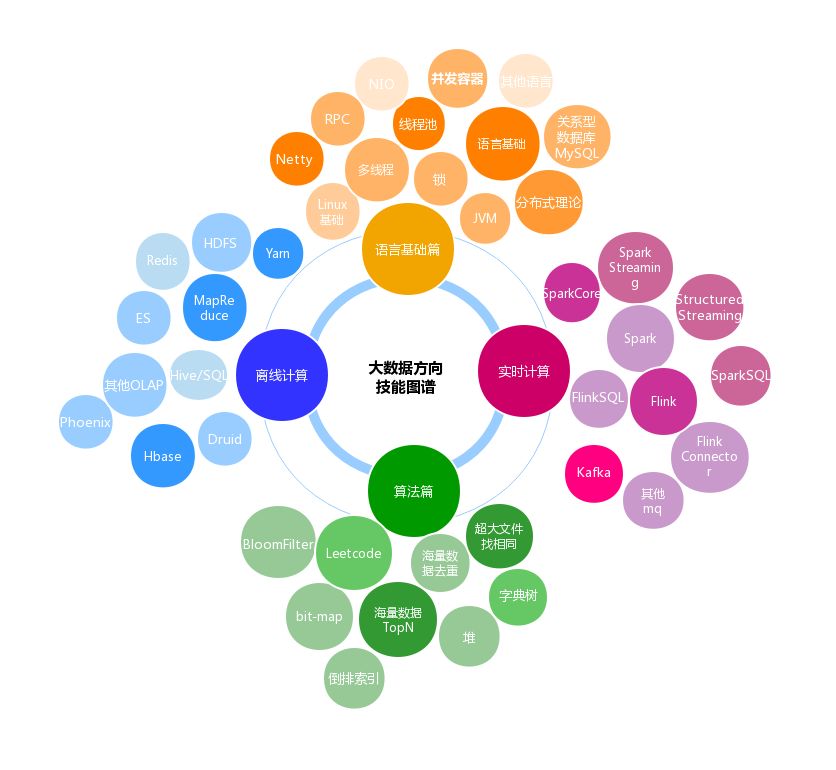
语言基础篇
Java基础篇
整个大数据开发技术栈我们从实时性的角度来看,主要包含了离线计算和实时计算两大部分,而整个大数据生态中的框架绝大部分都是用 Java 开发或者兼容了 Java 的 API 调用,那么作为基于 JVM 的第一语言 Java 就是我们绕不过去的坎,Java 语言的基础也是我们阅读源码和进行代码调优的基础。
Java 基础主要包含以下部分:
-
语言基础
-
锁
-
多线程
-
并发包中常用的并发容器(J.U.C)
语言基础
-
Java 的面向对象
-
Java 语言的三大特征:封装、继承和多态
-
Java 语言数据类型
-
Java 的自动类型转换,强制类型转换
-
String 的不可变性,虚拟机的常量池,String.intern() 的底层原理
-
Java 语言中的关键字: final 、 static 、 transient 、 instanceof 、 volatile 、 synchronized 的底层原理
-
Java 中常用的集合类的实现原理:ArrayList/LinkedList/Vector、SynchronizedList/Vector、HashMap/HashTable/ConcurrentHashMap 互相的区别以及底层实现原理
-
动态代理的实现方式
锁
-
CAS、乐观锁与悲观锁、数据库相关锁机制、分布式锁、偏向锁、轻量级锁、重量级锁、monitor
-
锁优化、锁消除、锁粗化、自旋锁、可重入锁、阻塞锁、死锁
-
死锁的原因
-
死锁的解决办法
-
CountDownLatch、CyclicBarrier 和 Semaphore 三个类的使用和原理
多线程
-
并发和并行的区别
-
线程与进程的区别
-
线程的实现、线程的状态、优先级、线程调度、创建线程的多种方式、守护线程
-
自己设计线程池、submit() 和 execute()、线程池原理
-
为什么不允许使用 Executors 创建线程池
-
死锁、死锁如何排查、线程安全和内存模型的关系
-
ThreadLocal 变量
-
Executor 创建线程池的几种方式:
-
newFixedThreadPool(int nThreads)
-
newCachedThreadPool()
-
newSingleThreadExecutor()
-
newScheduledThreadPool(int corePoolSize)
-
newSingleThreadExecutor()
-
ThreadPoolExecutor 创建线程池、拒绝策略
-
线程池关闭的方式
并发容器(J.U.C)
-
JUC 包中 List 接口的实现类:CopyOnWriteArrayList
-
JUC 包中 Set 接口的实现类:CopyOnWriteArraySet、ConcurrentSkipListSet
-
JUC 包中 Map 接口的实现类:ConcurrentHashMap、ConcurrentSkipListMap
-
JUC包中Queue接口的实现类:ConcurrentLinkedQueue、ConcurrentLinkedDeque、ArrayBlockingQueue、LinkedBlockingQueue、LinkedBlockingDeque
Java 进阶篇
进阶篇部分是对 Java 基础篇的补充,这部分内容是我们熟读大数据框架的源码必备的技能,也是我们在面试高级职位的时候的面试重灾区。
JVM
JVM 内存结构
class 文件格式、运行时数据区:堆、栈、方法区、直接内存、运行时常量池
堆和栈区别
Java 中的对象一定在堆上分配吗?
Java 内存模型
计算机内存模型、缓存一致性、MESI 协议、可见性、原子性、顺序性、happens-before、内存屏障、synchronized、volatile、final、锁
垃圾回收
GC 算法:标记清除、引用计数、复制、标记压缩、分代回收、增量式回收、GC 参数、对象存活的判定、垃圾收集器(CMS、G1、ZGC、Epsilon)
JVM 参数及调优
-Xmx、-Xmn、-Xms、Xss、-XX:SurvivorRatio、-XX:PermSize、-XX:MaxPermSize、-XX:MaxTenuringThreshold
Java 对象模型
oop-klass、对象头
HotSpot
即时编译器、编译优化
虚拟机性能监控与故障处理工具
jps、jstack、jmap、jstat、jconsole、 jinfo、 jhat、javap、btrace、TProfiler、Arthas
类加载机制
classLoader、类加载过程、双亲委派(破坏双亲委派)、模块化(jboss modules、osgi、jigsaw)
NIO
-
用户空间以及内核空间
-
Linux 网络 I/O 模型:阻塞 I/O (Blocking I/O)、非阻塞 I/O (Non-Blocking I/O)、I/O 复用(I/O Multiplexing)、信号驱动的 I/O (Signal Driven I/O)、异步 I/O
-
灵拷贝(ZeroCopy)
-
BIO 与 NIO 对比
-
缓冲区 Buffer
-
通道 Channel
-
反应堆
-
选择器
-
AIO
RPC
-
RPC 的原理编程模型
-
常用的 RPC 框架:Thrift、Dubbo、SpringCloud
-
RPC 的应用场景和与消息队列的差别
-
RPC 核心技术点:服务暴露、远程代理对象、通信、序列化
Linux 基础
-
了解 Linux 的常用命令
-
远程登录
-
上传下载
-
系统目录
-
文件和目录操作
-
Linux 下的权限体系
-
压缩和打包
-
用户和组
-
Shell 脚本的编写
-
管道操作
分布式理论篇
-
分布式中的一些基本概念:集群(Cluster)、负载均衡(Load Balancer)等
-
分布式系统理论基础:一致性、2PC 和 3PC
-
分布式系统理论基础:CAP
-
分布式系统理论基础:时间、时钟和事件顺序
-
分布式系统理论进阶:Paxos
-
分布式系统理论进阶:Raft、Zab
-
分布式系统理论进阶:选举、多数派和租约
-
分布式锁的解决方案
-
分布式事务的解决方案
-
分布式 ID 生成器解决方案
大数据框架网络通信基石——Netty
Netty 是当前最流行的 NIO 框架,Netty 在互联网领域、大数据分布式计算领域、游戏行业、通信行业等获得了广泛的应用,业界著名的开源组件只要涉及到网络通信,Netty 是最佳的选择。
关于 Netty 我们要掌握:
-
Netty 三层网络架构:Reactor 通信调度层、职责链 PipeLine、业务逻辑处理层
-
Netty 的线程调度模型
-
序列化方式
-
链路有效性检测
-
流量整形
-
优雅停机策略
-
Netty 对 SSL/TLS 的支持
-
Netty 的源码质量极高,推荐对部分的核心代码进行阅读:
-
Netty 的 Buffer
-
Netty 的 Reactor
-
Netty 的 Pipeline
-
Netty 的 Handler 综述
-
Netty 的 ChannelHandler
-
Netty 的 LoggingHandler
-
Netty 的 TimeoutHandler
-
Netty 的 CodecHandler
-
Netty 的 MessageToByteEncoder
离线计算
Hadoop 体系是我们学习大数据框架的基石,尤其是 MapReduce、HDFS、Yarn 三驾马车基本垫定了整个数据方向的发展道路。 也是后面我们学习其他框架的基础,关于 Hadoop 本身我们应该掌握哪些呢?
MapReduce:
-
掌握 MapReduce 的工作原理
-
能用 MapReduce 手写代码实现简单的 WordCount 或者 TopN 算法
-
掌握 MapReduce Combiner 和 Partitioner的作用
-
熟悉 Hadoop 集群的搭建过程,并且能解决常见的错误
-
熟悉 Hadoop 集群的扩容过程和常见的坑
-
如何解决 MapReduce 的数据倾斜
-
Shuffle 原理和减少 Shuffle 的方法
HDFS:
-
十分熟悉 HDFS 的架构图和读写流程
-
十分熟悉 HDFS 的配置
-
熟悉 DataNode 和 NameNode 的作用
-
NameNode 的 HA 搭建和配置,Fsimage 和 EditJournal 的作用的场景
-
HDFS 操作文件的常用命令
-
HDFS 的安全模式
Yarn:
-
Yarn 的产生背景和架构
-
Yarn 中的角色划分和各自的作用
-
Yarn 的配置和常用的资源调度策略
-
Yarn 进行一次任务资源调度的过程
OLAP 引擎 Hive
Hive 是一个数据仓库基础工具,在 Hadoop 中用来处理结构化数据。 它架构在 Hadoop 之上,总归为大数据,并使得查询和分析方便。 Hive 是应用最广泛的 OLAP 框架。 Hive SQL 也是我们进行 SQL 开发用的最多的框架。
关于 Hive 你必须掌握的知识点如下:
-
HiveSQL 的原理: 我们都知道 HiveSQL 会被翻译成 MapReduce 任务执行,那么一条 SQL 是如何翻译成 MapReduce 的?
-
Hive 和普通关系型数据库有什么区别?
-
Hive 支持哪些数据格式
-
Hive 在底层是如何存储 NULL 的
-
HiveSQL 支持的几种排序各代表什么意思(Sort By/Order By/Cluster By/Distrbute By)
-
Hive 的动态分区
-
HQL 和 SQL 有哪些常见的区别
-
Hive 中的内部表和外部表的区别
-
Hive 表进行关联查询如何解决长尾和数据倾斜问题
-
HiveSQL 的优化(系统参数调整、SQL 语句优化)
列式数据库 Hbase
我们在提到列式数据库这个概念的时候,第一反应就是 Hbase。
HBase 本质上是一个数据模型,类似于谷歌的大表设计,可以提供快速随机访问海量结构化数据。 它利用了 Hadoop 的文件系统(HDFS)提供的容错能力。
它是 Hadoop 的生态系统,提供对数据的随机实时读/写访问,是 Hadoop 文件系统的一部分。
我们可以直接或通过 HBase 的存储 HDFS 数据。 使用 HBase 在 HDFS 读取消费/随机访问数据。 HBase 在 Hadoop 的文件系统之上,并提供了读写访问。
HBase 是一个面向列的数据库,在表中它由行排序。 表模式定义只能列族,也就是键值对。 一个表有多个列族以及每一个列族可以有任意数量的列。 后续列的值连续地存储在磁盘上。 表中的每个单元格值都具有时间戳。 总之,在一个 HBase: 表是行的集合、行是列族的集合、列族是列的集合、列是键值对的集合。
关于 Hbase 你需要掌握:
-
Hbase 的架构和原理
-
Hbase 的读写流程
-
Hbase 有没有并发问题? Hbase 如何实现自己的 MVVC 的?
-
Hbase 中几个重要的概念: HMaster、RegionServer、WAL 机制、MemStore
-
Hbase 在进行表设计过程中如何进行列族和 RowKey 的设计
-
Hbase 的数据热点问题发现和解决办法
-
提高 Hbase 的读写性能的通用做法
-
HBase 中 RowFilter 和 BloomFilter 的原理
-
Hbase API 中常见的比较器
-
Hbase 的预分区
-
Hbase 的 Compaction
-
Hbase 集群中 HRegionServer 宕机如何解决
实时计算篇
分布式消息队列 Kafka
Kafka 是最初由 Linkedin 公司开发,是一个分布式、支持分区的(partition)、多副本的(replica)的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景: 比如基于 Hadoop 的批处理系统、低延迟的实时系统、Spark 流式处理引擎,Nginx 日志、访问日志,消息服务等等,用 Scala 语言编写,Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。
Kafka 或者类似 Kafka 各个公司自己造的消息'轮子'已经是大数据领域消息中间件的事实标准。 目前 Kafka 已经更新到了 2.x 版本,支持了类似 KafkaSQL 等功能,Kafka 不满足单纯的消息中间件,也正朝着平台化的方向演进。
关于 Kafka 我们需要掌握:
-
Kafka 的特性和使用场景
-
Kafka 中的一些概念: Leader、Broker、Producer、Consumer、Topic、Group、Offset、Partition、ISR
-
Kafka 的整体架构
-
Kafka 选举策略
-
Kafka 读取和写入消息过程中都发生了什么
-
Kakfa 如何进行数据同步(ISR)
-
Kafka 实现分区消息顺序性的原理
-
消费者和消费组的关系
-
消费 Kafka 消息的 Best Practice(最佳实践)是怎样的
-
Kafka 如何保证消息投递的可靠性和幂等性
-
Kafka 消息的事务性是如何实现的
-
如何管理 Kafka 消息的 Offset
-
Kafka 的文件存储机制
-
Kafka 是如何支持 Exactly-once 语义的
-
通常 Kafka 还会要求和 RocketMQ 等消息中间件进行比较
Spark
Spark 是专门为大数据处理设计的通用计算引擎,是一个实现快速通用的集群计算平台。 它是由加州大学伯克利分校 AMP 实验室开发的通用内存并行计算框架,用来构建大型的、低延迟的数据分析应用程序。 它扩展了广泛使用的 MapReduce 计算模型。 高效的支撑更多计算模式,包括交互式查询和流处理。 Spark 的一个主要特点是能够在内存中进行计算,即使依赖磁盘进行复杂的运算,Spark 依然比 MapReduce 更加高效。
Spark 生态包含了: Spark Core、Spark Streaming、Spark SQL、Structured Streming 和机器学习相关的库等。
学习 Spark 我们应该掌握:
(1)Spark Core:
-
Spark的集群搭建和集群架构(Spark 集群中的角色)
-
Spark Cluster 和 Client 模式的区别
-
Spark 的弹性分布式数据集 RDD
-
Spark DAG(有向无环图)
-
掌握 Spark RDD 编程的算子 API(Transformation 和 Action 算子)
-
RDD 的依赖关系,什么是宽依赖和窄依赖
-
RDD 的血缘机制
-
Spark 核心的运算机制
-
Spark 的任务调度和资源调度
-
Spark 的 CheckPoint 和容错
-
Spark 的通信机制
-
Spark Shuffle 原理和过程
(2)Spark Streaming:
-
原理剖析(源码级别)和运行机制
-
Spark Dstream 及其 API 操作
-
Spark Streaming 消费 Kafka 的两种方式
-
Spark 消费 Kafka 消息的 Offset 处理
-
数据倾斜的处理方案
-
Spark Streaming 的算子调优
-
并行度和广播变量
-
Shuffle 调优
(3)Spark SQL:
-
Spark SQL 的原理和运行机制
-
Catalyst 的整体架构
-
Spark SQL 的 DataFrame
Spark SQL 的优化策略: 内存列式存储和内存缓存表、列存储压缩、逻辑查询优化、Join 的优化
(4)Structured Streaming
Spark 从 2.3.0 版本开始支持 Structured Streaming,它是一个建立在 Spark SQL 引擎之上可扩展且容错的流处理引擎,统一了批处理和流处理。 正是 Structured Streaming 的加入使得 Spark 在统一流、批处理方面能和 Flink 分庭抗礼。
我们需要掌握:
-
Structured Streaming 的模型
-
Structured Streaming 的结果输出模式
-
事件时间(Event-time)和延迟数据(Late Data)
-
窗口操作
-
水印
-
容错和数据恢复
Spark Mlib:
本部分是 Spark 对机器学习支持的部分,我们学有余力的同学可以了解一下 Spark 对常用的分类、回归、聚类、协同过滤、降维以及底层的优化原语等算法和工具。 可以尝试自己使用 Spark Mlib 做一些简单的算法应用。
Flink
Apache Flink(以下简称 Flink)项目是大数据处理领域最近冉冉升起的一颗新星,其不同于其他大数据项目的诸多特性吸引了越来越多人的关注。 尤其是 2019 年初 Blink 开源将 Flink 的关注度提升到了前所未有的程度。
那么关于 Flink 这个框架我们应该掌握哪些核心知识点?
-
Flink 集群的搭建
-
Flink 的架构原理
-
Flink 的编程模型
-
Flink 集群的 HA 配置
-
Flink DataSet 和 DataSteam API
-
序列化
-
Flink 累加器
-
状态 State 的管理和恢复
-
窗口和时间
-
并行度
-
Flink 和消息中间件 Kafka 的结合
-
Flink Table 和 SQL 的原理和用法
另外这里重点讲一下,阿里巴巴 Blink 对 SQL 的支持,在阿里云官网上可以看到,Blink 部分最引以为傲的就是对 SQL 的支持,那么 SQL 中最常见的两个问题: 1.双流 JOIN 问题,2.State 失效问题也是我们关注的重点。
大数据算法
本部分的算法包含两个部分。 第一部分是: 面试中针对大数据处理的常用算法题; 第二部分是: 常用的机器学习和数据挖掘算法。
我们重点讲第一部分,第二部分我们学有余力的同学可以去接触一些,在面试的过程中也可以算是一个亮点。
常见的大数据算法问题:
-
两个超大文件找共同出现的单词
-
海量数据求 TopN
-
海量数据找出不重复的数据
-
布隆过滤器
-
bit-map
-
堆
-
字典树
-
倒排索引
企业期望的你是什么样子?
我们先来看几个典型的 BAT 招聘大数据开发工程师的要求:



以上三则招聘分别来自百度阿里和腾讯,那么我们把他们的要求分类归纳:
-
1~2 门语言基础
-
扎实的后台开发基础
-
离线计算方向(Hadoop/Hbase/Hive 等)
-
实时计算方向(Spark/Flink/Kafka 等)
-
知识面更宽优先(对口经验 + 其他)
如果你是 Apache 顶级项目的 Committer 那么恭喜你,你将会是各大公司竞相挖角对象。
我们在写简历时应该注意什么?
我曾经作为面试官面试过很多人,我认为一个比较优秀的简历应该包含:
-
漂亮的排版,杜绝使用 word,格式化的模板,推荐使用 MarkDown 生成 PDF
-
不要堆砌技术名词,不会的不了解的不要写,否则你会被虐的体无完肤
-
1~2 个突出的项目经历,不要让你的简历看起来像Demo一样浅显
-
写在简历上的项目我建议你要熟悉每一个细节,即使不是你开发的也要知道是如何实现的
-
如果有一段知名企业的实习或者工作经历那么是很大的加分
技术深度和广度?
在技术方向,大家更喜欢一专多能,深度广度兼具的同学,当然这个要求已经很高了。 但是最起码应该做到的是,你用到的技术不仅要熟悉如何使用,也应该要知晓原理。
如果你曾经作为组内的核心开发或者技术 leader 那么要突出自己的技术优势和前瞻性,不仅要熟悉使用现在已经有的 轮子 的优劣,也要对未来的技术发展有一定的前瞻性和预见性。
如何投递简历?
最建议的方式是直接找到招聘组的负责人或者让同学或者同事内推。
猜你喜欢
1、 过往记忆大数据,2019年原创精选69篇
2、 爱奇艺大数据实时分析平台的建设与实践
3、 Apache Kylin 在一点资讯的实践
4、 Apache Spark 将支持 Stage 级别的资源控制和调度

过往记忆大数据微信群,请添加微信: fangzhen0219,备注【进群】
点下 「 在看 」, 月入百万!
正文到此结束
- 本文标签: Region 缓存 Netty CyclicBarrier CTO 参数 java基础 lib 数据模型 目录 message 翻译 NIO ip id 进程 本质 apr LinkedList CountDownLatch API 并发 CEO 阿里云 开源 dist ACE 云 线程池 协议 executor shell Master 线程 工程师 阿里巴巴 索引 配置 拒绝策略 管理 stream 空间 谷歌 百度 client Word linux Logging 编译 cache 质量 希望 数据库 一致性 Datanode ConcurrentHashMap map AIO 大数据 Markdown 时间 list final 企业 jstack 任务调度 ssl ORM db 文件系统 模型 Namenode HashTable sql BIO 开源项目 幂等 需求 key 锁 ThreadPoolExecutor SSL/TLS 下载 Nginx Action node MQ 负载均衡 分布式系统 HDFS HashMap HMaster synchronized 数据 zab 代码 2019 分布式事务 volatile 同步 http 招聘 apache scala tab 工作原理 js RocketMQ 集群 集合类 HRegionServer JVM UI 分布式消息系统 内存模型 tag 消息队列 开发 consumer core 文章 java queue Hadoop 垃圾回收 https 分布式 cat springcloud HBase ArrayList 基金 Reactor 多线程 Semaphore App 关联查询 dubbo src 数据挖掘 spring producer 源码 IO struct 幂等性 互联网 分布式锁 安全
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

