好奇 Airbnb 在 AWS 技术架构,在这里都能找到答案
本站点所有文章,仅代表个人想法,不代表任何公司立场,所有数据都来自公开资料
Airbnb 概况
公开资料显示,Airbedandbreakfast.com 在2008上线,总部位于美国旧金山,在 2009年站点缩写成 Airbnb.com,2015年8月,Airbnb正式宣布进驻中国,2016年11月成立“Airbnb中国”,中国区独立于亚太区运营。
Airbnb 用户遍布 190个国家近34000个城市,发布的房屋租赁信息达到 5万条。Airbnb 在2016年下半年开始盈利,预计2017年仍将实现盈利。
截至2019年第一季度末,自2008年成立以来,Airbnb的房源的累计预订人次超过5亿,在2019年8月10日的单夜入住人数超过400万人次。
计划于 2020年上市,最新估值310亿美金( 相较而言,美股上市的携程目前市值在 209.15亿美元 ),是美国估值第二高的超级独角兽,也曾是估值仅次于Uber(优步)的独角兽企业。
2014年仅有90名左右的员工,2015年到 200人,但随着业务的快速增长,到 2018年,仅仅4年时间,他们的工程师数量超过了1000名,增长了 10倍多;他们从第一天就开始使用 AWS,目前所有的工作负载也都在 AWS上;
更新的数据请参考官网:https://news.airbnb.com/fast-facts/
Airbnb 技术团队
从公开资料显示,Airbnb 主要的技术团队包括,Engineering,Data Science, IT 以及安全四大块,管理团队包含 一个 Engineering VP - Mike Curtis,2个 Engineering Director,一个安全 Director,一个 IT Director;
AWS 服务使用及规模
2014年 AWS reinvent,airbnb 的 VP Mike 分享了为什么选择 AWS,主要一个原因是 AWS 提供丰富的技术平台,使得 Airbnb 团队可以专心业务发展相关的技术工作,其他所有的都可以托付给 AWS 平台和团队:
-
EC2:2010年24台,到 2014年1月1000台,2015年第四季度,总计有 5000台 EC2,其中 1200+台负责 Web 应用,3500台用于数据分析平台及机器学习。
-
数据库:初期使用 RDS for MySQL,最近迁移到 Amazon Aurora :2018年底有 XXX TB 数据库存储大小
-
Amazon S3: 用户生成内容,如照片等,XXX PB(2018年底数据)
-
Amazon EMR + S3:数据湖
-
SageMaker:数据标注
-
Amazon DynamoDB
-
Amazon CloudFront
-
ElastiCache for Memcached
-
ElastiCache for Redis:先在 EC2自建,后来迁移到托管服务,100+个集群,XXX TB(2018年底)
-
Route53
-
Amazon CloudWatch虚机监控,同时利用 DataDog(一个重要原因是和 HAProxy 集成比较好);告警组件是自研的 Interferon,已经开源。
运维人员
初期整个站点是一个单体应用架构,性能可以横向扩展,运维工作简单,因此,有关于部署运维的基础设施层的开发和运维响应是依赖于“志愿者”模式,我们整个站点依靠这样志愿者系统运维人员组成的小团队;
2014年透露有5个运维人员。
基础设施即代码工具使用 Terraform 和 Chef。
技术架构
Monorail 架构
2015 年左右他们是典型的单体架构基于 Ruby on Rails,部署在单一的 AWS 美东区域,全部是 Amazon EC2 部署,该单体应用在 2018 年Q2有消耗 xxxx 台 EC2 ,前端从 CDN 进入 Nginx 负债均衡进行分发,服务基于 JSON over HTTP/S 协议,业务逻辑相当复杂,比如对于一个 P3 模块(显示房间列表及详情)就有19张核心表,总共 71张数据表;对于 P4 模块(即订单和下单模块)超150张核心表。
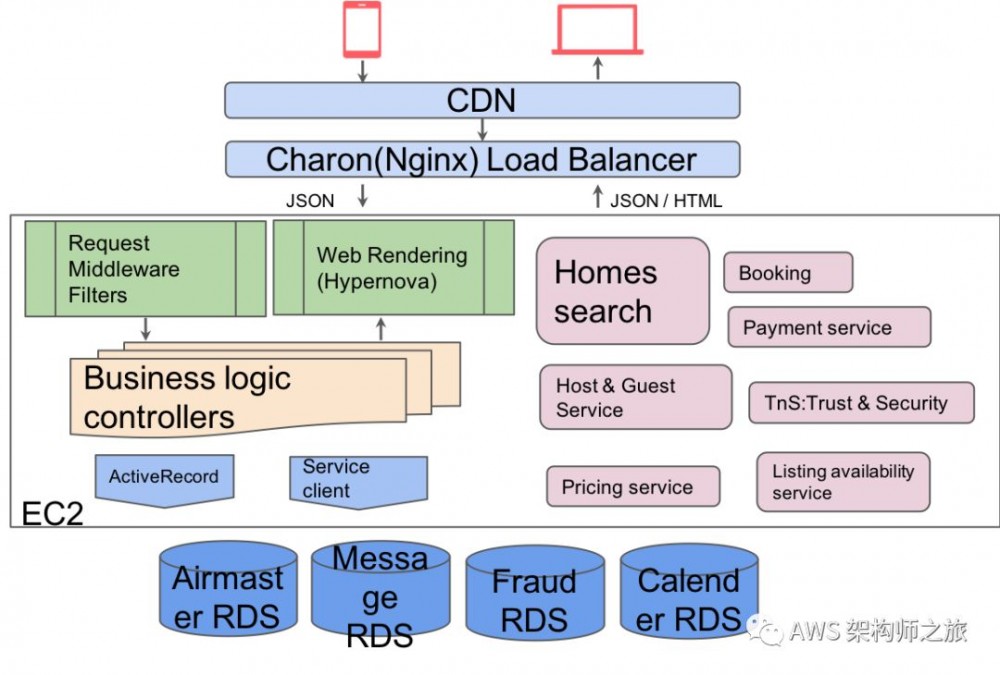
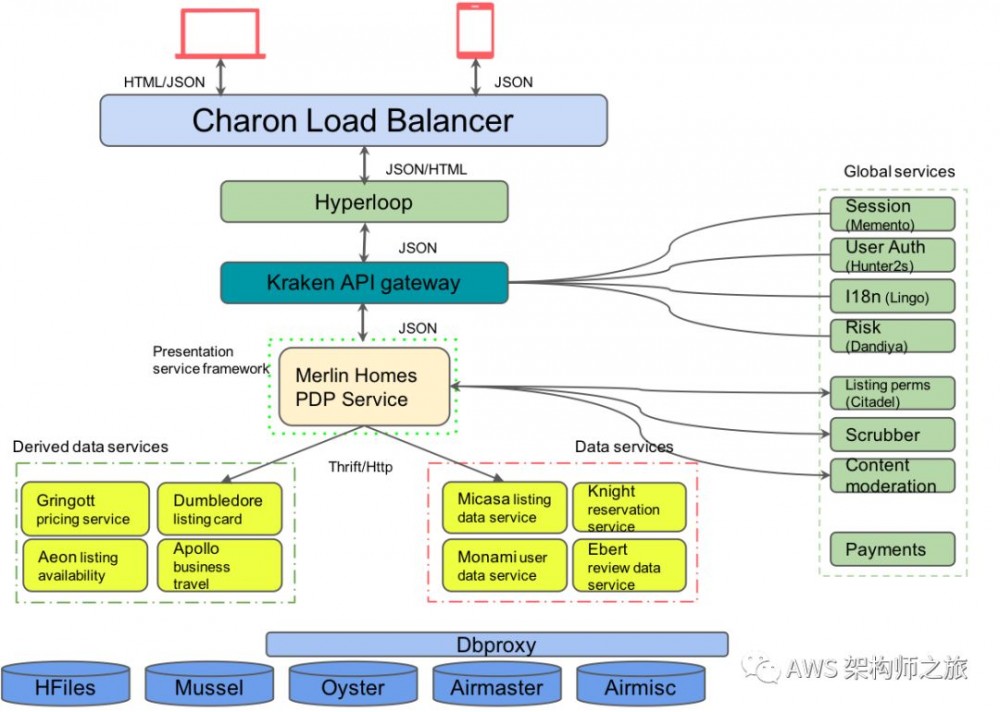
SOA 微服务架构
2016~2017年,开始 SOA 改造,改造的前后各种考量请参考前文 《客户案例分析:Airbnb单体到微服务改造之旅(1)》
数据库 Amazon Aurora
-
绝大多数 MySQL,少部分 Postgres / Oracle
-
从 2011年开始全部是全托管的 RDS 服务
-
2017年7月启动 RDS for MySQL 到 Amazon Aurora的评估和迁移,17年底完成生产环境切换
-
数据库代理:定制化的 MariaDB MaxScale,增强的数据库连接池,限流,限制慢查等等
-
上百个数据库实例
-
通过 Terraform 来进行基础设施自动化管理
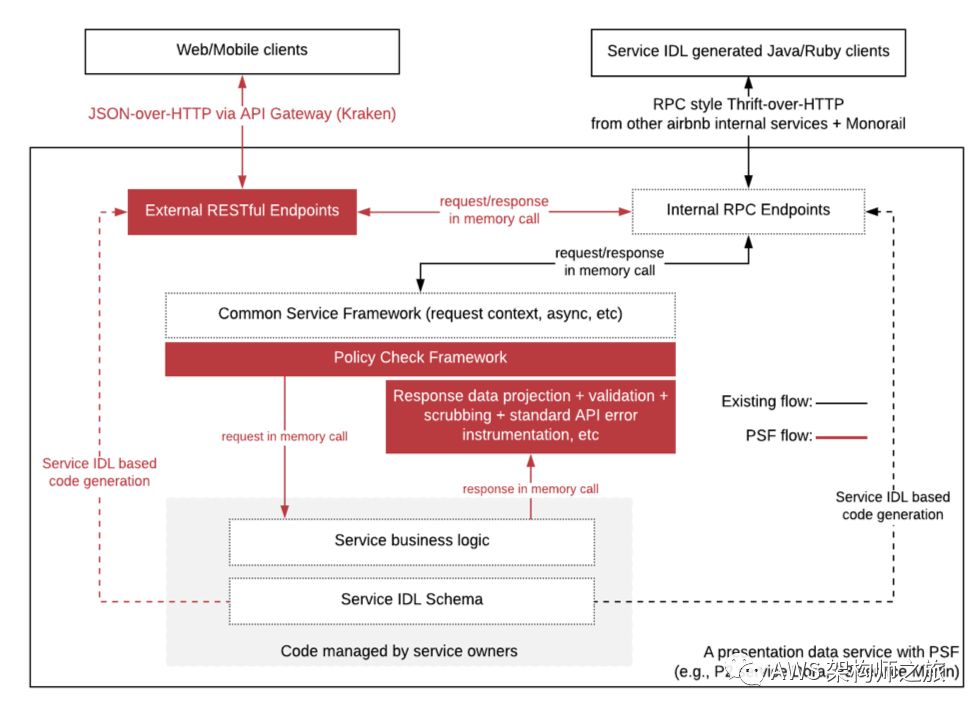
微服务 API 框架
同时支持两种协议,一个是 JSON over HTTP,另外一个是 RPC 方式的 Thrift over HTTP,开发者而言,很多基本的服务治理相关逻辑,由 IDL 定义并自动生成。
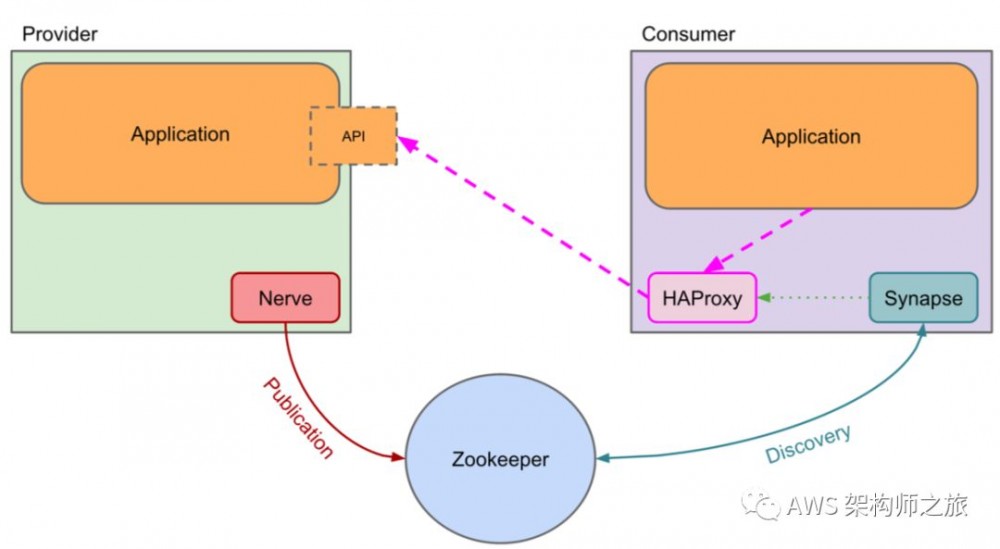
服务发现 - SmartStack
SmartStack 类似如今的 Service Mesh,服务通过本机的边车(Sidecar)代理(HAProxy)进行互相之间的调用和路由,其中两个组件 Nerve 和 Synapse 都已经开源,SmartStack 应该是最早(2013年前后)的 “Service Mesh” 的雏形;如下图所示,服务注册库基于 Zookeeper,组件 Nerve 负责主机上的服务发现,健康检查和服务下线等操作;Synapse 负责监听 ZK 的动态变化,并生成并更新 HAProxy的服务路由配置;HAProxy 在这里作为一个 Sidecar(边车)代理服务消费者到服务提供方之间的请求。该架构对应用无任何侵入性,不需要自行处理服务注册和发现。
由于 HAProxy 支持的协议所限,Airbnb 团队在向 Envoy 演进。
负载均衡 - Charon
微服务中期望将上下文传播到下游的服务中去,因此引入了 Nginx 作为外部服务入口,由于前端 CDN 分发不均衡问题,Airbnb 团队,在 CDN 和 Nginx 之间还是引入了 Amazon ELB。
内部服务以 <service name>.dyno 命名,所有发送到 *.dyno 的请求都会通过 DNS 指向 Dyno 服务实例组,Dyno 也类似 Nginx,从请求报文 Header 中截取服务名称,并通过 Synapse 和 HAProxy 来处理到目标服务的访问;Dyno 同时也负责服务的认证授权。
API Gateway - Kraken (JSON Over HTTP)
移动端和 Web 端调用,从负载均衡 Charon 进来,到 Kraken 进行路由和全局处理,再路由到下层领域服务;
数据分析
数据分析基础平台架构
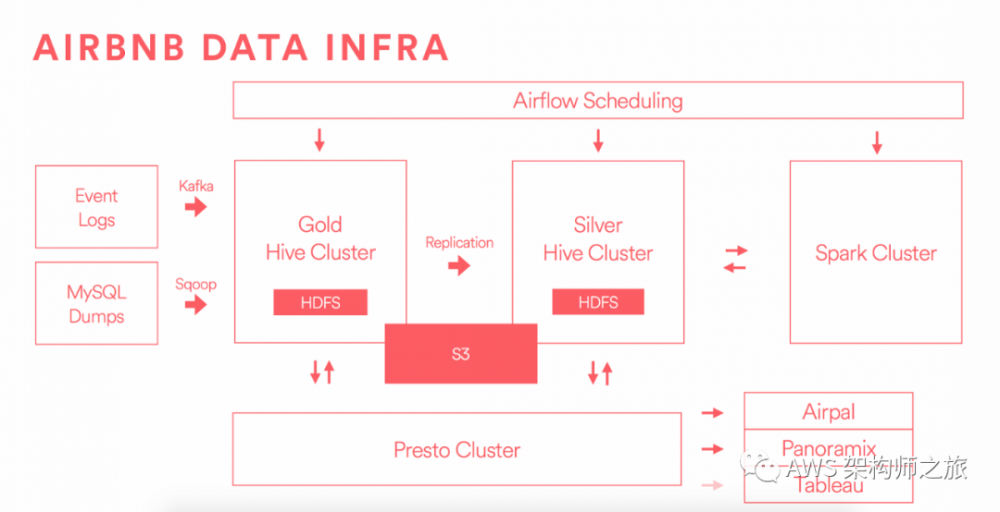
-
应用将消息和事件写入 Kafka
-
利用 Sqoop 将 RDS 数据导入到 Hadoop
-
原始数据包含用户行为事件,维度表数据,保存在 Gold 集群中,执行 ETL 任务,生成统计表,检查数据质量
-
架构中的 Gold 集群和 Silver 集群主要是保障高可用,以及隔离不同的 SLA 查询任务,黄金版集群满足严格的SLA要求的重要任务,不允许执行对资源消耗大的 Adhoc 查询;而白银版集群,则比较轻松,不要求 SLA,可以跑消耗大的查询。
-
大部分使用针对 Hive 表的 Presto 查询接口
-
采用开源的 Airpal 组件,一个支持 Presto 的交互式 UI,30% 的员工使用该工具进行交互式查询
-
定时任务采用 Airflow 进行编排和调度
-
S3 作为数据湖,适合数据长期存储和结合 EMRFS 使用
机器学习 & Data Science
公开资料显示,Airbnb 拥有 30人规模的 Data Science 团队。
房东可以理解的机器学习库 - Aerosolve
主要解决 Airbnb 共享经济中,房屋定价和需求匹配问题,重点强调算法可解释性,集合机器学习和人工经验;比如房屋的动态定价问题,影响因素特别多,有房屋位置,季节和时间,有百万间独立房屋带有不同的服务比如面积大小,家具,等等,用户有不同的喜好,比如服务,食物等;非正常因素,比如当地的活动或节假日。
Aerosolve 从常识出发,结合数据训练,比如价格提升,成交概率降低,再结合数据来修正经验常识,比如简单利用线性模型,按绝对值倒排权重,就可以知道哪些特征比较重要:比如房屋照片偏好问题,专业摄影的房间照片对比客户自行上传的照片,直接排序结果可以知道,房客拍摄的照片排序来看更喜欢温馨,暖色调,卧室居多;而专业摄影师,则强调华丽,通透及客厅;
与其他的机器学习库相比,Aerosolve 具有以下特点:
-
特征呈现基于 Thrift:支持Pairwise Ranking Loss 和单上下文的多条目呈现,每一个特征向量(FeatureVector)有三种类型:stringFeatures、floatFeatures 和denseFeatures。
-
支持特征转换语言:Aerosolve 将特征转换包含在一个独立的转换模块中,与模型解耦,用户既能够将转换操作拆散使用,又可以提前转换相关数据,常用的转换操作包括:列表转换、交叉转换和多尺度网格转换。
-
比较容易理解的调试模型
-
独立轻量的 Java 推理代码
-
使用 Scala 代码进行训练
-
简单的图片内容分析代码,适合图片的排序
-
底层跑在 Apache Spark 上
机器学习基础设施平台 - Zipline(数据管理) & BigHead(UI)
目标是赋能 Airbnb 算法团队一个高效的 ML 共享基础设施平台,降低构建生产级 ML 应用的复杂度;构建 ML 应用的复杂度在于,和数仓集成,扩展模型训练和推理服务,在原型和生产之间,在训练和推理之间,如何保障一致性?跟踪多个模型版本,ML 模型的迭代;
ML 模型通常只需要8~12周来构建完成,但 ML 工作流常常比预计的要慢很多,零碎且脆弱。
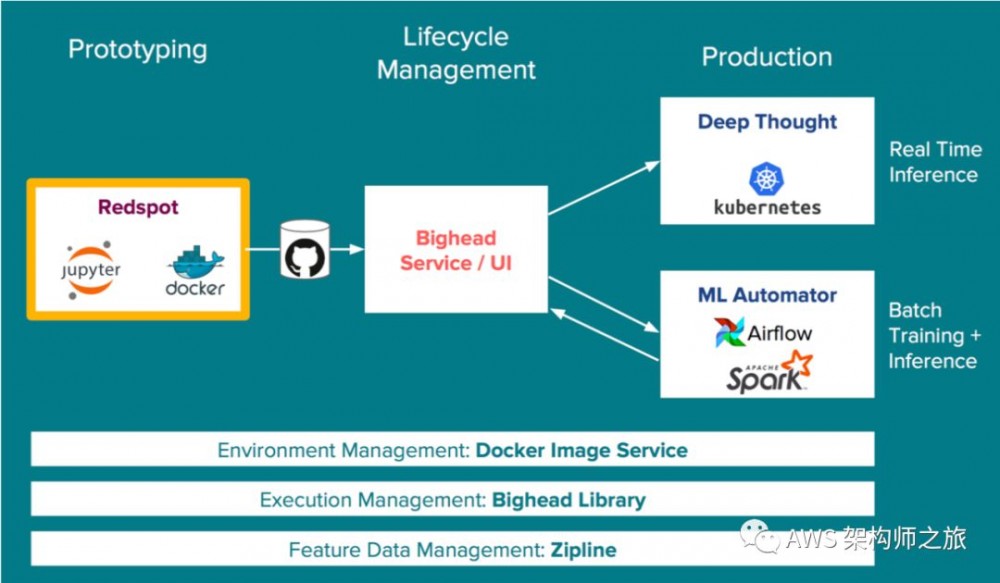
整个基础设施串接 ML 的原型环境,Jupyter Notebook加强版 Redspot,容器环境和生产环境,包括实时推理和批处理(训练+推理)
实验环境:Redspot
增强的 JupyterHub,
-
集成 Airbinb 的数仓
-
访问优化的硬件资源比如 GPU, Amazon P3/X1 etc
-
文件共享,基于 AWS EFS 实现
-
集成 Bighead 服务
-
保障实验和生产环境,模型的一致性
Docker Image Service 服务:
-
面向 ML 定制化的依赖管理,保障环境的一致性
Bighead 服务
ML 生命周期管理,
-
统一的模型管理:跟进模型变化比跟进代码变化更重要
-
唯一可信的模型状态管理:ML 模型需要可以快速重建,保障持续性
-
不同模型效果的对比
-
提供 Bighead library,构建一致的 ML Pipeline(提供可视化),屏蔽底层框架差异,模型训练的元数据管理,等等
数据管理 Zipline
Zipline 的初衷是算法科学家花在准备数据上的时间太多,超 60% 以上,但前面我们已经提到 Hadoop 数据平台,为什么还需要构建一个新的 Zipline?Hadoop 数据仓库面向是分析师而不是 ML 模型,ML 特征数据的表达和数据仓库不一样,比如过去7天的订单量,模型需要的值是 0 还是 1,但数仓中一般是累加数值,比如3, 4等等,另外缺少更多的特征,比如进一步要求过去12个小时的订单数;同时已有的应用数据库数据,也不适合直接给到模型做训练。
参考资料
-
Airbnb AWS 案例
-
商业模式分析 共享经济代表——Airbnb
-
Airbnb Architecture
-
Airbnb确定今年晚些时候IPO估值超310亿美元
-
https://airbnb.io/
-
https://medium.com/@airbnbeng

诞生于 2019,遇见 2020。
感谢关注,欢迎动动手指标星和置顶;
这样就不会错过少但精彩的技术探讨、团队建设、案例分享!
每周至少一更,转发是对我的最大鼓励!
学习之路漫漫,走走停停,
偶有所感,随心所记,
言由心声,问心无愧!
从客户中来,到客户中去!
正文到此结束
- 本文标签: CDN 房间 开发者 Amazon Auror json 企业 Architect cache 模型 限流 apache db 负载均衡 集群 UI API 实例 Uber 生命 自动生成 高可用 Proxy zip Hadoop DNS 食物 配置 SOA CTO Amazon http ORM id 连接池 java 认证 js 美国 sqoop 管理 色调 主机 Service 应用架构 服务注册 mysql 定制 https 数据库 sql IDE 心声 开源 运营 scala MQ 工程师 协议 Oracle zookeeper redis 时间 开发 统计 Features Haproxy Presto 2019 站点 ip Ipo 安全 数据 需求 REST src 2015 IO 专心 部署 Nginx 质量 apr 调试 代码 Docker lib 文章 图片 一致性 微服务 web 自动化
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

