Java集合—HashMap之hash优化算法
HashMap 底层是 数组 + 链表 + 红黑树 。
数组我们很熟悉,支持随机访问,所以在最优情况下,即 HashMap 没有出现 hash 冲突,没有形成链表或红黑树结构,此时数据都存在数组中,get 方法的查询时间复杂度为 O(1) 。
链表查询时间复杂度 O(n) ,红黑树 O( )。底层的数据结构和对应的时间复杂度是我们研究的基础。
再来看看 HashMap 继承或实现了哪些类和接口。
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
复制代码
如代码所示,HashMap 实现了 Cloneable、Serializable,说明支持克隆和序列化。
**备注:**所有关于 HashMap 的分析都是基于 JDK1.8 。
2. 源码解析
先来看看常用的基本属性。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 static final float DEFAULT_LOAD_FACTOR = 0.75f; int threshold; static final int TREEIFY_THRESHOLD = 8; static final int UNTREEIFY_THRESHOLD = 6; transient Node<K,V>[] table; transient int size; 复制代码
默认 bucket 数组长度为16,默认负载因子 0.75 ,默认 threshold = 16 * 0.75 = 12 。当数组长度达到 12 时开始扩容。(这都不知道的同学建议去面壁思过)
TREEIFY_THRESHOLD 是指链表长度达到 8 以后转化为红黑树,UNTREEIFY_THRESHOLD 则相反。
size 是 HashMap 中元素的总个数,要和 table 的 length 区分开。
我们着重来看一下 Node ,因为数据都存储在 Node 中。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
复制代码
- hash: 根据存储元素的 key 的 hash 值
- next:因为是数组,肯定要存储下一个节点
2.1 构造函数
思考一个问题:HashMap 是在什么时候给 bucket 数组分配内存的?是 new HashMap() 的时候吗?带着问题我们来看看HashMap 的四种构造函数。
2.1.1 HashMap()
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
复制代码
可以看到,无参构造函数只是把 DEFAULT_LOAD_FACTOR 的值(默认 0.75)赋值给 loadFactor,loadFactor 是给 HashTable 用的,所以可以理解为啥正事都没干。
2.1.2 HashMap(int initialCapacity)
一般我们实际使用过程中都是用的这个,在新建一个 HashMap 的时候先预估存储的元素的个数,假设个数为 n ,然后用 n 除以 0.75 ,假设算出的值是 m ,initialCapacity 取不小于 m 的 2 的幂次方对应的值。
举个例子:我现假设要往 HashMap 中存入 17 个值,17 / 0.75 = 22.67 。取不小于 22.67 的最近的 2 的幂次方,最终 initialCapacity 取 32(2的5次方) 。即 new HashMap(32) 。
为什么 initialCapacity 要取 2 的幂次方呢?之后我们讲 put 方法的时候会讲到。
如果我脑残,非要 new HashMap(17) ,会发生什么呢?
来,上源码:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
复制代码
此时,传入的 initialCapacity 是 17,loadFactor 是 0.75 。
第 2~9 行代码都是判断 initialCapacity 的合法性,是否小于 0 ,是否大于最大数组长度等等。
第 11 行代码才是重点,我们来看看 tableSizeFor 方法:
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
复制代码
看注释,power of two 是二次方的意思。翻译一下就是,根据传进来的数返回一个合适的二次方的结果。 最终的结果就是传入 17,算出来的返回值是 32 ,最后 threshold 等于 32 。 此时 threshold 是临时保存初始化容量 initialCapacity 的值,在后面会有用到。
2.1.3 HashMap(int initialCapacity, float loadFactor)
这个和 2.2.2 的区别是它可以自定义负载因子,但是一般我们都不改负载因子,默认使用 0.75 就行。下面来说说为什么是负载因子是 0.75 。
我们应该很容易理解负载因子应该在 0.5~1.0 之间。
如果小于 0.5,假设取 0.3 。初始化数组长度 16,threshold = 16*0.3 = 4.8 ,也就是数组长度大于 5 的时候进行扩容,扩容到 32 ;以此类推,数组长度 10 的时候,扩容到 64 。越往后,未使用的空间会越来越大,纯属浪费。
如果大于 1,假设取 1.5 。初始化数组长度 16,threshold = 16*1.5 = 24 。大家有没有发现一个问题,一个长度为 16 的数组要存储 24 条数据。那形成链表的几率就是百分之百了。会严重影响到查询的效率。
那为什么在 0.5~1.0 之间选择了 0.75 呢?0.6 行不行,0.8 行不行?
看看源码注释里面的一段话:
* <p>As a general rule, the default load factor (.75) offers a good * tradeoff between time and space costs. Higher values decrease the * space overhead but increase the lookup cost (reflected in most of * the operations of the <tt>HashMap</tt> class, including * <tt>get</tt> and <tt>put</tt>). The expected number of entries in * the map and its load factor should be taken into account when * setting its initial capacity, so as to minimize the number of * rehash operations. If the initial capacity is greater than the * maximum number of entries divided by the load factor, no rehash * operations will ever occur. 复制代码
翻译一下,默认的负载因子 0.75 在时间和空间消耗上提供了一个平衡。较高的值会降低空间使用但是会增加查找消耗(会影响 put 和 get 方法)。map 期望的 entries 数量和负载因子在初始化的时候就要考虑到,这样可以降低 rehash 的次数。如果初始化的数组长度大于 map 存储数据的最大值除以负载因子,将不会有 rehash 发生。
其实官方的说法跟我上面实际使用中的取值方法一样,0.75 是官方认为最优的平衡时间和空间的值。至于 0.75 是怎么推算出来的,这是个数学问题。有兴趣的同学可以自行研究。
**小结:**负载因子默认使用 0.75 就行了,不要自以为是的瞎改。
2.1.4 HashMap(Map<? extends K, ? extends V> m)
比较少用,有兴趣的同学自行研究,不是很重要。
2.1.5 总结
回到我们最初的问题,在构造函数中并没有发现初始化 bucket 数组的操作。所以并不是在这个阶段给数组分配内存的。除此之外,我也讲了推荐的构造函数使用方法。
2.2 hash优化算法
看完了构造方法,我们来看看 put 方法,这也是 HashMap 最重要最复杂的方法。
在详细讲解 put 方法之前,我们先约定好几个变量的定义,以免后面发生混乱。
- h : 这个表示直接通过 Object 类的 hashCode 方法算出来的值
- hash : 这个表示优化之后的 hash 值
- index :这个是数组的角标
来,上源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
复制代码
我们先看一下 hash(key) 这个方法,然后再看 putVal 方法。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
复制代码
h = key.hashCode()) ^ (h >>> 16) 这个就是最核心的 hash 优化算法了。
key.hashCode() 就是调用的 Object 类的 hashCode 方法,算出一个 h 值,int 类型(4 个字节,32 位)。
h ^ (h >>> 16) 这个是干嘛用的呢?我们来举个例子。以我的名字为 key(原谅我臭不要脸),我们得出 “赵小发” 的 hashCode 是 35552727 。转化为二进制是 0000 0010 0001 1110 0111 1101 1101 0111 。
那 h >>> 16 就是把二进制右移 16 位,然后高位空出来的 16 位用 0 补充。
得到的结果是: 0000 0000 0000 0000 0000 0010 0001 1110 。
然后进行 异或算法 (异或算法的结果是相同为 0,不同为 1 )。h ^ (h >>> 16) 算出来的结果如下:
我们通过 hash 方法算出来的就是 0000 0000 0001 1110 0111 1111 1100 1001 。
然后我们进入 putVal 方法 :
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// 省略
}
}
// 省略
}
复制代码
我们这一讲主要是讲 hash 优化算法,所以就不将完整代码截出来了。
onlyIfAbsent、evict 并不是核心的属性,可以忽略。
很明显,第一次 put 的时候是满足第 4 行代码的判断的,此时会执行第 5 行代码。
此时,resize 方法做的事情主要就是第一次给数组分配内存,可以看一下我 debug 的截图。
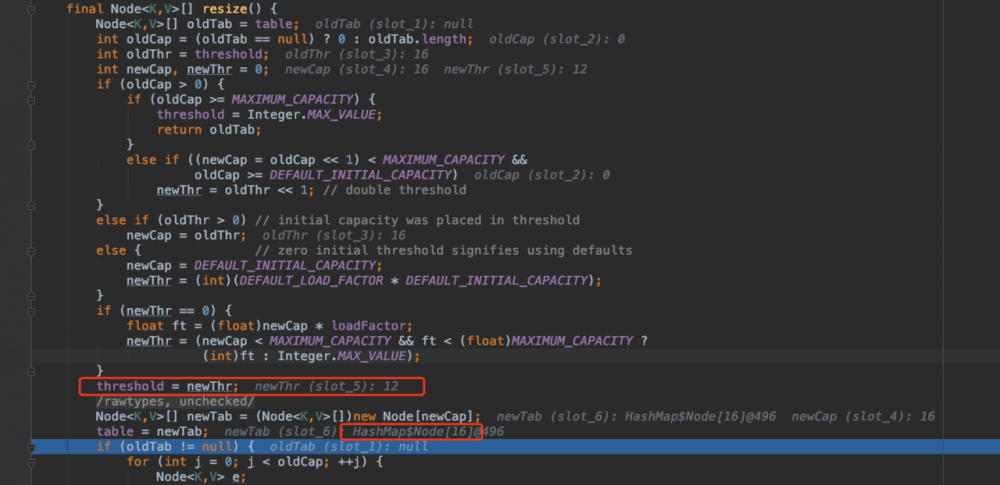
在 resize 方法中, Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; 这行代码才是初始化数组,分配内存的操作。所以,这也回答了上面构造函数中的那个问题,HashMap 是在执行 put 方法时给 bucket 数组分配内存的。
resize 方法执行完毕后,table 的 length 是 16 ,即第 5 行代码 n = (tab = resize()).length 的值为 16 。
然后执行第 6 行代码,这个非常非常非常重要。
(n - 1) & hash 这行代码是将数组长度和之前算出来的 hash 值进行与运算,如下所示:
算出来的值 1001 ,二进制是 9 。然后将 9 赋值给 i ,而 i 就是数组的 index 角标。也就是说,key 为“赵小发”的这条数据会被存储在数组的 index 为 9 的那个 Node 里。来,截个图看一下:
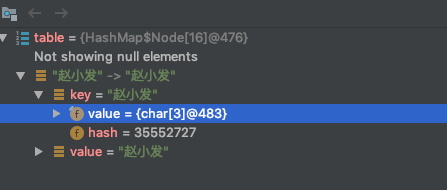
思考:(n - 1) & hash 本质是啥?
我们之前通过 h ^ (h >>> 16) 算出来了一个 hash 值,但是这个 hash 值太大了,我们最终是要算出一个 index,而这个 index 必须在 0~(n - 1) 之间。那最先想到的应该就是取模算法了,对 n 取模,即 hash / n ,余数就是对应的 index 位置。那为什么不用取模算法呢?原因是性能没有位运算高。
那 (n - 1) & hash 为什么能保证算出来的值在 0~(n - 1) 之间呢?
因为此时 n -1 = 15 ,15 的二进制是 0000 0000 0000 0000 0000 0000 0000 1111 ,前面的 28 位全部是0 。在进行与运算时,无论 hash 的值是多少,进行与运算之后前面的 28 位肯定也是 0 。而结果的后 4 位完全由 hash 的后 4 位决定,并且结果一定小于等于 15 。此时就可以把结果赋值给数组的 index 了。
同样的,如果 n 是 32 ,那么 n - 1 = 31 ,31 的二进制是 0000 0000 0000 0000 0000 0000 0001 1111 。hash 的值无论是多少,(n - 1) & hash 运算后前 27 位都是 0 ,后 5 位完全由 hash 的后 5 位决定,并且结果一定小于等于 31 。
这里对二进制稍微敏感的同学很容易反应过来。
这也充分说明了 HashMap 的数组长度为什么必须是 2 的幂次方。因为只有 2 的幂次方在减 1 之后,它的二进制低位全部为1。
再思考:为什么要用 h ^ (h >>> 16) ?
直接通过 Object 类的 hashCode 算法算出一个 h 值,直接拿来和 (n - 1) 做与运算,不是更简单吗?为什么要多此一举 h ^ (h >>> 16) 。
还是以“赵小发”为 key 来举例,h 值是 0000 0010 0001 1110 0111 1101 1101 0111 。如果这个时候直接拿来和 (n - 1) 做与运算,就是下面这样子。
最终的计算结果由 h 值的后 4 位(0111)决定。那 h 值的前面的 28 位岂不是完全没有参与运算?下面我举几个例子:
0000 0010 0001 1110 0111 1101 1101 0111 ("赵小发")
1000 0010 0001 1110 0111 1101 1101 0111 ("赵大发")
000 1 0010 0001 1110 0111 1101 1101 0111 ("赵二狗")
如上面我加粗的例子来看,高位不同,但是完全不影响和 (n - 1) 做与运算的结果,凭啥?凭啥我赵小发算出来和赵二狗在同一个 index 上面。高 28 位完全不起作用。所以我们要想着,让高位也要参与运算,这样可以减少 hash 冲突。所以要拿 h 和 (h >>> 16) 做运算,让 h 的高 16 位和 h 进行计算,计算的结果再和 (n - 1) 做与运算,最终算出数组的 index 。
再再思考:为什么 h 和 (h >>> 16) 做的是异或运算?
原因是异或运算能更好的保留各部分的特征,与运算结果会向 1 靠拢,或运算结果会向 0 靠拢 。
**总结:**hash 优化算法包含两部分。一是通过 hashCode 值的高16 位参与运算来减少冲突,二是通过与运算而不是取模运算提高性能。
下一篇文章,我们详细梳理下 put 方法的流程, Java集合—HashMap之梳理put方法逻辑 。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

