让人头疼的WAS内存溢出,看银行运维人员如何优雅的解决

1 引言
WAS(IBM WebSphere Application Server)是IBM发布的一款成熟的企业级Web中间件产品,凭借其可靠性与稳定性,一直是国内大型商业银行Web服务的主流选择。可再稳定也会出问题,在日常的生产运维中,WAS应用问题的排查确实让笔者这种银行运维人员头疼。一方面厂商提供技术支持的时效性与准确性有待改善,另一方面像IBM其他产品一样,网上开放的可参考和借鉴的资料太少,发生WAS问题时着实让人无从下手。不过不要紧,鲁迅先生曾经说过,“走的人多了,自然就有路了”,笔者作为具有多年WAS运维经验的老鸟,下面就把自己在应对WAS内存溢出方面的知识总结一下,为大家介绍一下如何优雅的应对WAS内存溢出。
2 IBM JAVA内存管理
要应对WAS内存溢出,必须对IBM对JAVA内存的管理有所了解,下面,笔者就简单介绍一下IBM是如何管理JAVA内存的。不同于大家经常使用的Oracle Java,WAS使用的JAVA是内置于WAS内部的IBM JAVA,与Oracle Java在JVM、配置参数等方面有着显著不同。
IBM JAVA 同样包含JDK、JRE、JVM三层,其关系如图所示:

图1 JDK、JRE、JVM关系
JVM内存管理区域包括程序计数器、Java虚拟机栈、堆空间、方法区、运行时常量池、本地方法栈(The Java® Virtual Machine Specification Java SE 8 Edition定义的内存区域)。以上几个内存区域中,除程序计数器区域外,都可能会产生OutOfMemoryError错误(本文中内存溢出特指Java的“OutOfMemoryError”)。
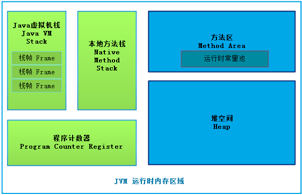
图2 JVM 运行时内存区域
程序计数器区域
Java虚拟机支持多线程运行,所以对于每个线程,都需要一个指示其运行程序位置的指针,这个指针指向当前程序运行方法的地址。
Java虚拟机栈
每一个Java线程都拥有一个私有的Java虚拟机栈。像其他传统语言一样,Java虚拟机栈保存了程序调用时的局部变量和部分结果(称之为Frame)。
方法区、运行时常量池
方法区存放运行时常量池、字段以及方法(包括构造方法、特殊方法)代码。在IBM Java 8版本中,所有加载的类都存放在称之为Metaspace的空间中,Metaspace使用操作系统本地内存空间。
本地方法区域
为了支持操作系统本地方法(如C语言)调用,虚拟机中在本地方法区域中存储本地方法调用的栈信息。
堆空间
堆是JVM运行时内存中最大的区域,也是和程序开发密切相关区域,所有的对象实例(包括基本类型)、数组都存放在这个区域。和传统的C、C++语言不同,Java语言不需要开发人员显式地进行内存的申请和释放,而是由JVM的Allocator(内存分配器)和Garbage Collection(内存垃圾回收器,简称GC)负责管理内存。我们最常见的内存溢出“java.lang.OutOfMemoryError : Java heap space”也主要和该区域有关。下面我们将着重阐述IBM J9 VM堆空间相关模型和垃圾回收策略。
堆空间内存结构和垃圾回收策略(GC)
J9 VM支持多种不同的GC策略,不同的GC策略对应不同的Heap内存模型及分配回收算法,不同的GC策略适应于不同的业务场景,对于大多数系统(特别是交易类系统)来说,可使用“Generational Concurrent Garbage Collector”策略(简称gencon,参数:-Xgcpolicy:gencon可以指定使用该策略),这也是J9 VM的默认GC策略,本文主要详细介绍该策略。
“Generational Concurrent Garbage Collector”策略特别适合存在非常多短生命周期对象的应用,即对象申请完之后,很快就不被使用,可以被GC回收。而一般的交易类系统,都符合这种场景。
在该策略下,Heap内存被划分成新区域(Nursery)、老区域(Tenured)。所有对象创建后都被分配到Nursery区域,之后如果该对象一直标记为可用,则会被自动到Tenured区域。
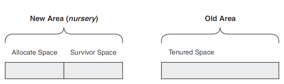
图3 J9 VM 默认堆空间内存模型
更进一步,可以将Nursery区域划分为Allocate空间、Survivor空间。新创建的对象一开始被分配到Allocate空间,当Allocate空间满之后,触发一次Local GC,由Scavenge 进程将Allocate空间中“活着的”对象拷贝到Survivor区,超过一定周期(Tenured age)的对象则直接被移动到Tenured区域。之后,Allocate空间、Survivor空间的角色互换,等待下次Local GC。
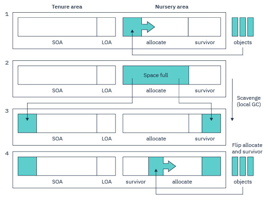
图4 Local GC过程
上文提到,在一般场景下,大部分对象创建后,很快就不被使用、存活的对象较少,所以Local GC移动的数据也很少,而且Local GC后,可以得到很大的Allocate空间,这样就减小了GC时间。在JVM中,GC意味着所有运行中线程都要停下来(Pause)等待GC结束,GC完成后,才可以继续运行,所以Local GC可以减少因GC带来的系统吞吐量下降的影响。
发生堆空间分配失败或者调用System.gc()方法后,触发Global GC过程。Global GC通过标记、清除、压缩过程来尽可能释放JVM内存空间。Global GC需要获得整个JVM的排他控制权,所以当进行Global GC时,所有应用线程也将暂停。当Global GC结束后,应用线程将恢复执行。
3 常见的WAS内存溢出原因
上面我们介绍了IBM Java内存管理的模型和策略。理解上述模型后,我们可以清楚的知道为何会发生内存溢出:
(1)JVM内部或者JVM间接使用的操作系统内存分配失败后触发内存溢出报错。JVM内存区域中,除了程序计数器区域外,Java虚拟机栈、堆空间、方法区、运行时常量池、本地方法栈都可能会发生内存溢出报错。
(2)对于堆空间,当堆空间已经尽可能扩展,并且JVM花费了95%以上的时间在GC时,也会触发内存溢出报错。
以上两点是内存溢出的基本要点,但实际生产系统由于运行环境往往较为复杂,在处理实际问题时,我们还应结合环境配置和业务场景来分析。通过总结实际运维过程中经验,可以将内存溢出原因分为如下几类:
(1)堆内存大小上限配置过低
由于Java程序所能使用的堆空间上限完全取决于JVM启动时的参数配置,当堆空间上限参数设置过低,即使操作系统物理内存空闲较多,应用程序也无法使用。所以在问题排查时,我们首先应该明确系统配置的堆空间上限(由Xmx参数指定),一般不能使用堆大小上限默认值。
(2)程序内存泄漏导致内存持续增长
如果程序存在内存泄漏,即使已经不再使用的内存仍将无法被GC回收释放,JVM内存将持续增长(而且,由于内存使用率逐渐升高,将会更加频繁的触发GC,反复GC又会引发CPU过高),最终导致堆内存空间满而引发内存溢出。
(3)数据查询交易返回记录数过多或者程序申请使用大内存对象
当程序过度地使用内存大对象或数组,导致无法申请足够的内存空间而引发内存溢出。例如,在实际生产中,可能存在应用程序读取整表数据或情况(数据条数在几万条以上),极易引发内存溢出。
(4)物理内存过低或因其他进程消耗过多内存引发内存溢出
即使我们设定了合理的JVM内存空间大小上限,但也有可能因为本地操作系统本身可用内存过低、无法实现内存空间的动态扩充,进而导致内存溢出;也可能因为在同一个操作系统上运行的其他JVM或者本地进程使用过多的内存导致内存溢出;由于JVM的部分区域(如Metaspace、DirectMemory等)直接使用的是操作系统内存,所以当操作系统内存过低,但创建本地线程过多、加载类过多时也有可能发生内存溢出异常;当程序过度使用DirectMemory也会引发内存溢出。
(5)交易量突然增大
如果我们将JVM堆内存上限设为M,每支交易处理需要使用的堆内存是N,那么当同时处理的交易量X突然增多N*X>M时,就容易触发内存溢出。
4 如何优雅的应对WAS内存溢出
当发生内存溢出后,首先要做的是恢复生产,恢复因内存溢出而宕机的Server。恢复生产后,可按照下面步骤进行内存溢出原因分析。
收集环境信息
内存溢出分析首先要做的就是收集环境信息和日志信息。
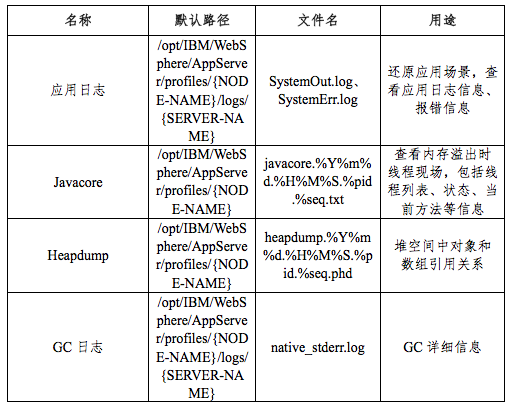
收集日志文件
表 1 收集日志文件表
分析应用日志
查看SystemOut.log日志java.lang.OutOfMemoryError的提示信息,确定内存溢出发生在JVM的哪个区域之后,查看SystemOut.log、SystemErr.log中应用交易日志,分析是否可疑的异常交易。
分析堆内存使用趋势
一般内存分析,第一步先查看JVM内存使用情况,即通过“IBM Pattern Modeling and Analysis Tool for Java Garbage Collector”工具,打开native_stderr.log文件,查看JVM堆空间内存使用曲线:
对于大对象或数组使用导致内存溢出的曲线一般如下图所示,存在曲线突然升高的情况:
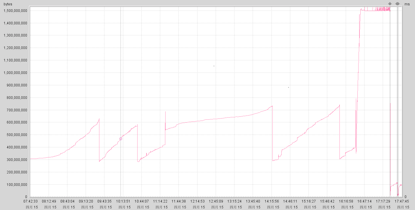
图5 大对象内存溢出堆空间趋势图
内存泄漏导致内存溢出的曲线一般如下图所示,曲线缓慢上升(红色曲线):
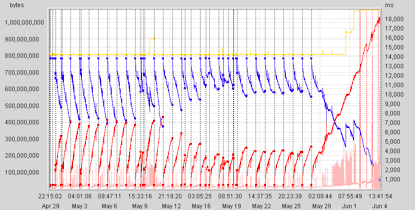
图6 内存泄漏程序堆空间趋势图
找到堆空间可疑内存溢出点
使用IBM HeapAnalyzer工具分析Heapdump文件。 HeapAnalyzer工具列出了可疑的内存溢出点,分析人员需要逐个对这些可疑点进行排查,结合程序代码进行进一步确认。
分析线程现场信息
使用“IBM Thread and Monitor Dump Analyzer for Java”工具,分析javacore文件。检查内存溢出时正在执行的交易、正在执行的方法。
非堆空间内存溢出
如果出现“java.lang.OutOfMemoryError: 本机内存耗尽”内存溢出报错,则需要考虑DirectByteBuffer内存区域引发内存溢出。
5 如何在具体场景应用
上面白话了那么多,想必各位已经头晕眼花,那么接下来就来点干货。在具体的运维场景中,银行运维人员该如何快速分析和定位WAS内存溢出的问题呢,让笔者来结合自己遇到的某个实际场景进行阐述。
某次笔者正在优雅的喝着咖啡,写着工作总结,忽然接到监控告警通知,“XX管理系统交易超时率提高,请尽快处置”。笔者一阵激灵,赶快扔下咖啡跑进操作间开始排查系统问题。
第一步,当然是尽快恢复生产喽,笔者排查时,通过监控发现某台WAS服务器内存直冲天际,隐隐有突破内存限制的隐患,而就在同时,交易超时的情况开始同时升高。基本已经能定位问题是由于内存原因导致的,那么为了尽快恢复生产,笔者当然是首先选择对故障服务器的WAS应用进行了重启。

图7:发生问题时某台WAS服务器的内存监控情况
第二步,重启大法果然不出意外的解决了问题,重启WAS应用后系统交易超时指标恢复了正常。接下来,笔者就要认真排查问题,到底是什么导致了这次内存意外的冲高呢。笔者开始着手采集分析文件,主要包括SystemOut.log(输出日志)、SystemErr.log(错误日志)、native_stderr.log(GC日志),在采集时,笔者还在日志目录中发现了Javacore文件与Heapdump文件,这已经能确认是发生了内存溢出,下面的问题就是分析原因了。
第三步,首先我们来查看日志文件,下面分别是SystemOut.log和SystemErr.log的部分内容。果然,在问题时点附近的错误日志中看到了OutOfMemoryError,同时在应用日志中看到了一些正在执行的sql,那么到底是哪个程序在作怪,又是为什么产生了内存溢出呢。

图8:问题时点的应用日志

图9:问题时点的错误日志
第四步,看来仅从日志是无法定位具体问题的,笔者接下来要运用工具来解决问题了。笔者先后用IBM HeapAnalyzer和IBM Thread and Monitor Dump Analyzer for Java工具,分别对Heapdump文件及Javacore文件进行了具体的分析。对Heapdump文件的解析结果显示,某个List居然存在68万多个对象,占用了近50%的内存空间。对Javacore文件的分析结果显示,发生溢出时某支交易线程一直处于等待状态。
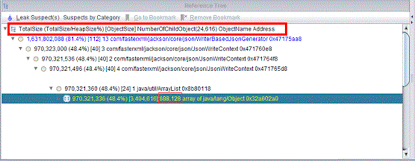
图10:Heapdump文件的分析结果
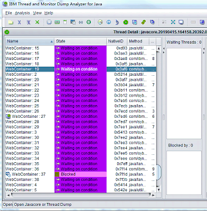
图11:Heapdump文件的分析结果
第五步,有了这么丰富的信息,笔者已经做出了基本的判断,本次WAS内存溢出应该是由于某线程在一次查询时获取了太多数据,导致JVM为装载这些数据的List对象分配了过多内存,从而导致的内存溢出。笔者将信息反馈给开发人员后,果然没多久就得到确认,确实是某条查询语句未对查询结果进行分页处理,一次性命中过多查询结果后将其全部装入内存导致。
至此,笔者的这次应急处置与事件分析工作告了一段落,笔者心满意足的回到工位,继续开始喝咖啡,写总结,优雅的等待下班的到来,相信开发人员修复这个隐藏缺陷后,笔者又可以清净一段时间了。
6 如何预防或解决内存溢出问题
经过上面一番讲解,相信对于WAS内存溢出的分析,无论是理论还是实践大家都有了一定的认识,那么,我们如何能预防或避免这种问题呢。笔者进行了一些简答的总结。
对于物理内存不足或者堆空间上限配置不足的情况,需要评估合适的物理内存或者堆空间上限大小,进行扩充。需要注意的是32位WAS最大堆内存上限为1536MB,如果需要升级到更大内存,则需要迁移到64位WAS平台。另外,堆内存空间并不是越大越好,越大的内存意味着GC管理也越复杂,GC的耗时及应用程序停顿的时间也越长。
对于存在内存泄漏或者是大对象申请情况引发的内存溢出,一般需要在定位问题原因后,在测试环境复现问题,进行程序优化解决问题。程序优化的方法不一而足,例如存在大数据量数据查询的情况可以加入筛选条件或者增加分页处理;也可以暂时规避解决的方式,通过关闭发生问题的交易或者修改交易流程不触发内存溢出的场景来临时性解决问题。
7 最后
以上就是笔者总结的如何优雅的应对WAS内存溢出的全部内容了,WAS作为一款企业级Web中间件,至少目前在国内银行、证券等大型国企中还占据着主导地位,了解WAS知识有助于我们在生产运维过程中高效解决问题,提高应急处置效率,后续笔者会继续总结在日常运维过程中碰到的问题,跟大家共同分享和交流。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

