记一次内存溢出排查过程
有一个服务经常会停止服务,一开始没特别注意,出问题就 重新部署 。
后来有一次重启前看了眼 GC,发现一直在 Full GC:
[149644.445s][info][gc,start ] GC(2210) Pause Full (Allocation Failure) [149644.447s][info][gc,phases,start] GC(2210) Phase 1: Mark live objects [149644.708s][info][gc,phases ] GC(2210) Phase 1: Mark live objects 261.113ms [149644.708s][info][gc,phases,start] GC(2210) Phase 2: Compute new object addresses [149644.771s][info][gc,phases ] GC(2210) Phase 2: Compute new object addresses 62.603ms [149644.771s][info][gc,phases,start] GC(2210) Phase 3: Adjust pointers [149644.903s][info][gc,phases ] GC(2210) Phase 3: Adjust pointers 131.929ms [149644.903s][info][gc,phases,start] GC(2210) Phase 4: Move objects [149644.903s][info][gc,phases ] GC(2210) Phase 4: Move objects 0.011ms [149644.905s][info][gc,heap ] GC(2210) DefNew: 314553K->314553K(314560K) [149644.905s][info][gc,heap ] GC(2210) Tenured: 699071K->699071K(699072K) [149644.905s][info][gc,metaspace ] GC(2210) Metaspace: 83387K->83387K(1126400K) [149644.905s][info][gc ] GC(2210) Pause Full (Allocation Failure) 989M->989M(989M) 459.957ms [149644.905s][info][gc,cpu ] GC(2210) User=0.46s Sys=0.00s Real=0.46s [149644.907s][info][gc,start ] GC(2211) Pause Full (Allocation Failure) [149644.910s][info][gc,phases,start] GC(2211) Phase 1: Mark live objects [149645.168s][info][gc,phases ] GC(2211) Phase 1: Mark live objects 258.422ms [149645.168s][info][gc,phases,start] GC(2211) Phase 2: Compute new object addresses [149645.231s][info][gc,phases ] GC(2211) Phase 2: Compute new object addresses 63.401ms [149645.231s][info][gc,phases,start] GC(2211) Phase 3: Adjust pointers [149645.365s][info][gc,phases ] GC(2211) Phase 3: Adjust pointers 133.363ms [149645.365s][info][gc,phases,start] GC(2211) Phase 4: Move objects [149645.367s][info][gc,phases ] GC(2211) Phase 4: Move objects 1.892ms [149645.368s][info][gc,heap ] GC(2211) DefNew: 314559K->312083K(314560K) [149645.368s][info][gc,heap ] GC(2211) Tenured: 699071K->699071K(699072K) [149645.368s][info][gc,metaspace ] GC(2211) Metaspace: 83387K->83387K(1126400K) [149645.368s][info][gc ] GC(2211) Pause Full (Allocation Failure) 989M->987M(989M) 460.962ms [149645.368s][info][gc,cpu ] GC(2211) User=0.46s Sys=0.00s Real=0.46s
服务限制了 4G 内存,在没有指定 -Xmx 的情况下只能使用 1G 内存,
了解更多 GC 内容看这里: HotSpot Virtual Machine Garbage Collection Tuning Guide 和 GC Tuning: In Practice
当时着急用服务就又直接重启了,直到今天,才在重启前尽可能保留了更多的信息。
下面是监控和 GC 的实时截图:
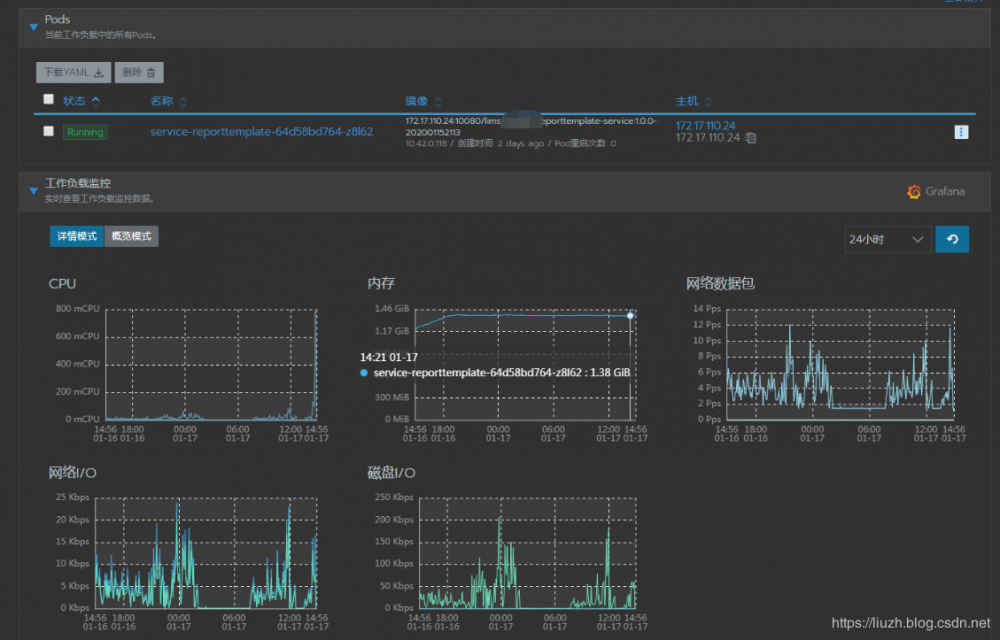
服务启动两天后,实际上在1天前就已经占满内存开始频繁 GC。
GC 实时信息:
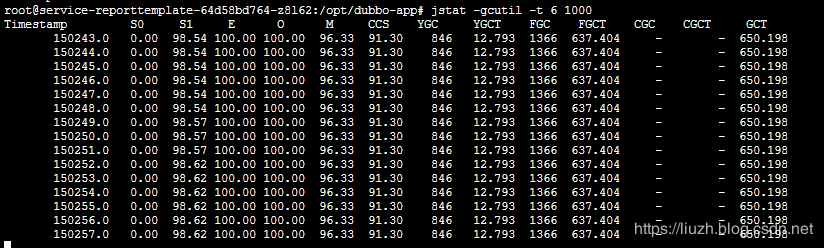
FGC 比 YGC 还多,E年轻代满了,O老年代也满的。每次可用的只有 S1, S2 中的不到 10% 的空间。
这次本来要导出 dump 信息,可惜手快重启没拷出来。等新服务启动一段时间后,在线上通过 jps 查看 id,然后使用 jmap -dump:live,format=b,file=heap.bin <pid> 导出 dump 信息。
jmap 详细资料: https://docs.oracle.com/en/java/javase/11/tools/jmap.html#GUID-D2340719-82BA-4077-B0F3-2803269B7F41
导出 heap.bin 后,先通过 VisualVM 打开了,能看到有限的信息,关键还不熟悉 OQL 语法 ,很不方便,因此使用 内存分析器(MAT) 进行分析。
Memory Analyzer (MAT) 内存分析器(MAT)
Eclipse Memory Analyzer 是一个快速且功能丰富的 Java 堆分析器,它可以帮助您发现内存泄漏并减少内存消耗。
使用内存分析器分析数亿个对象的高效堆转储,快速计算对象的保留大小,查看是谁阻止垃圾收集器收集对象,运行报告自动提取泄漏嫌疑人。
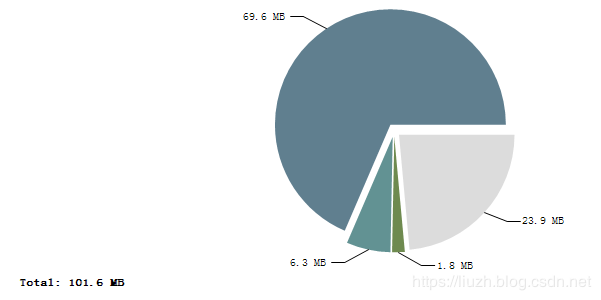
用 mat 打开后,根据提示信息找到了下面的地方:
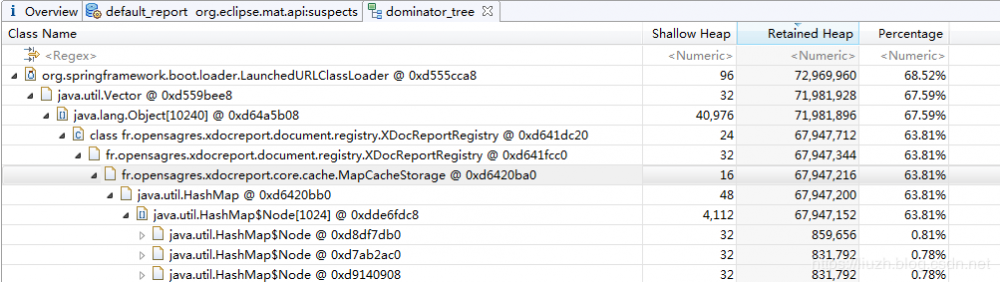
XDocReportRegistry 中的 MapCacheStoreage 占用了 63.81% 的空间,从名字来看是缓存,而缓存是最容易出现内存溢出的地方。
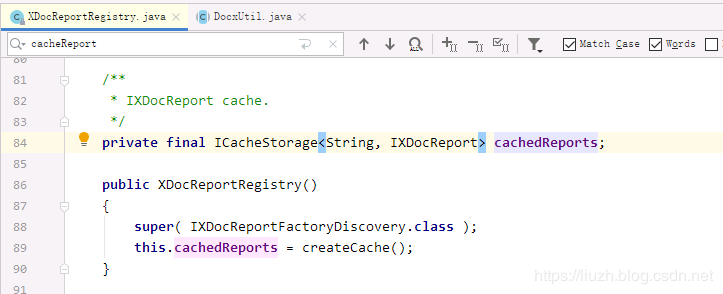
在工具类中有如下调用:
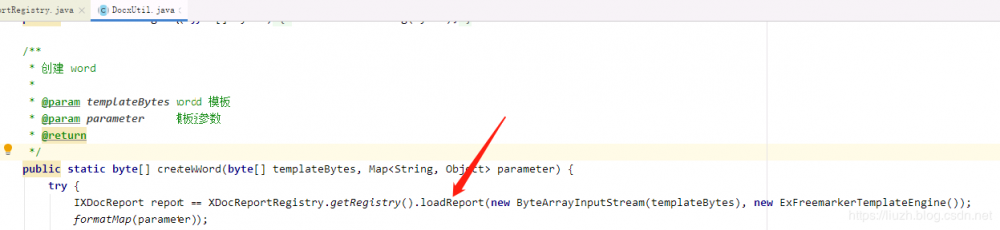
这里的 loadReport 如下:
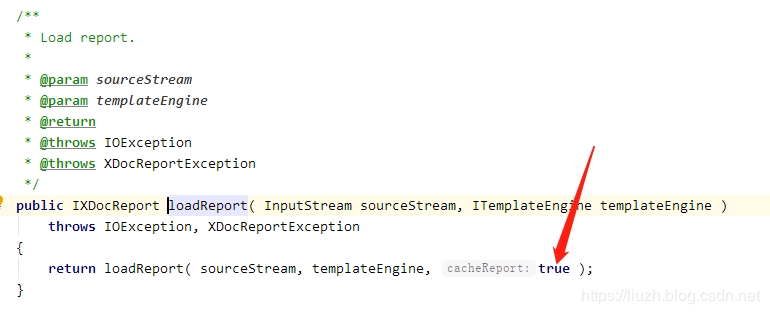
这个方法默认是缓存的,但是使用的地方每次都是传入新的 InputStream ,缓存的 IXDocReport 根本没有用上,因此该方法只要执行一次都会导致缓存增加一个,最终会将内存占满。
最简单的解决方法就是调用 loadReport 的时候指定 cacheReport=false 禁用缓存。
解决了这里内存溢出的问题后,服务所用内存应该会大幅度降低,等服务运行一两天后再补充两张资源占用图。
在2019 年博客总结 中提过:
因为我发现很多技术博客的内容中,很少涉及相关内容的出处,如果我只了解了别人博客提到的,关注的内容,看不到全貌,我自己总感觉不够,我想看到更详尽的资料,即使用到的只是其中一部分,但是提供出处就可以让人有了解更多的机会,对你博客内容的可信度提高很多。因此 2020 年会多一些轮子似的博客,但是会提供详细的出处和扩展资料。
所以,本文中提供的所有链接的价值要远远大于本文。如果有兴趣,一定要看!
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

