Java线程池的使用笔记
线程池
简单理解,它就是一个管理线程的池子。
- 它帮我们管理线程,避免增加创建线程和销毁线程的资源损耗 。因为线程其实也是一个对象,创建一个对象,需要经过类加载过程,销毁一个对象,需要走GC垃圾回收流程,都是需要资源开销的。
- 提高响应速度。 如果任务到达了,相对于从线程池拿线程,重新去创建一条线程执行,速度肯定慢很多。
- 重复利用。 线程用完,再放回池子,可以达到重复利用的效果,节省资源。
线程池可以通过ThreadPoolExecutor来创建,它的构造函数如下:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
几个核心参数的作用
- corePoolSize: 线程池核心线程数最大值
- maximumPoolSize: 线程池最大线程数大小
- keepAliveTime: 线程池中非核心线程空闲的存活时间大小
- unit: 线程空闲存活时间单位
- workQueue: 存放任务的阻塞队列
- threadFactory: 用于设置创建线程的工厂,可以给创建的线程设置有意义的名字,可方便排查问题。
- handler: 线城池的饱和策略事件,主要有四种类型。
线程池流程图
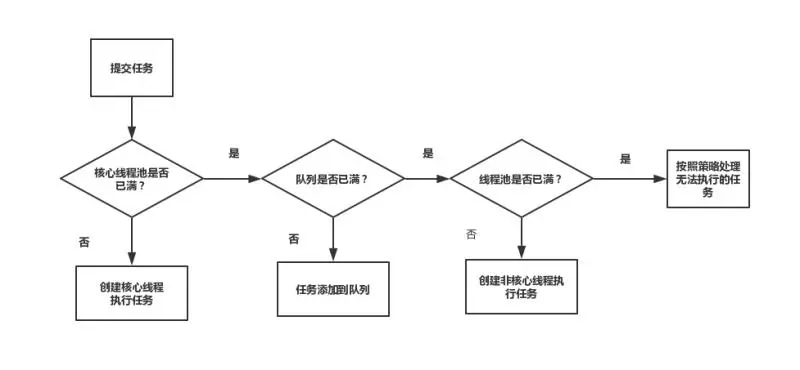
- 提交一个任务,线程池里存活的核心线程数小于线程数corePoolSize时,线程池会创建一个核心线程去处理提交的任务。
- 如果线程池核心线程数已满,即线程数已经等于corePoolSize,一个新提交的任务,会被放进任务队列workQueue排队等待执行。
- 当线程池里面存活的线程数已经等于corePoolSize了,并且任务队列workQueue也满,判断线程数是否达到maximumPoolSize,即最大线程数是否已满,如果没到达,创建一个非核心线程执行提交的任务。
- 如果当前的线程数达到了maximumPoolSize,还有新的任务过来的话,直接采用拒绝策略处理。
四种拒绝策略
- AbortPolicy(抛出一个异常,默认的)
- DiscardPolicy(直接丢弃任务)
- DiscardOldestPolicy(丢弃队列里最老的任务,将当前这个任务继续提交给线程池)
- CallerRunsPolicy(交给线程池调用所在的线程进行处理)
ExecutorCompletionService
假设现在有一大批需要进行计算的任务,为了提高整批任务的执行效率,你可能会使用线程池,向线程池中不断submit异步计算任务,同时你需要保留与每个任务关联的Future,最后遍历这些Future,通过调用Future接口实现类的get方法获取整批计算任务的各个结果。
虽然使用了线程池提高了整体的执行效率,但遍历这些Future,调用Future接口实现类的get方法是阻塞的,也就是和当前这个Future关联的计算任务真正执行完成的时候,get方法才返回结果,如果当前计算任务没有执行完成,而有其它Future关联的计算任务已经执行完成了,就会白白浪费很多等待的时间,所以最好是遍历的时候谁先执行完成就先获取哪个结果,这样就节省了很多持续等待的时间。
而ExecutorCompletionService可以实现这样的效果,它的内部有一个先进先出的阻塞队列,用于保存已经执行完成的Future,通过调用它的take方法或poll方法可以获取到一个已经执行完成的Future,进而通过调用Future接口实现类的get方法获取最终的结果。
实例演示
@Test
public void test() throws InterruptedException, ExecutionException {
Executor executor /= Executors.newFixedThreadPool(3);
CompletionService<String/> service /= new ExecutorCompletionService</>(executor);
for (int i /= 0 ; i < 5 ;i++) {
int seqNo /= i;
service.submit(new Callable<String/>() {
@Override
public String call() throws Exception {
return "HelloWorld-" + seqNo + "-" + Thread.currentThread().getName();
}
});
}
for (int j /= 0 ; j < 5; j++) {
System.out.println(service.take().get());
}
}
执行结果:
HelloWorld-2-pool-1-thread-3
HelloWorld-1-pool-1-thread-2
HelloWorld-3-pool-1-thread-2
HelloWorld-4-pool-1-thread-3
HelloWorld-0-pool-1-thread-1
参考文章:
https://juejin.im/post/5d1882...
https://cloud.tencent.com/dev...正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

