科普分布式架构
本系列文章Github 后端进阶指南 已收录,此项目正在完善中,欢迎star。
1. 分布式架构解决什么问题
主要是两个:
-
大流量的处理
通过集群技术将大规模并发请求负载均衡到不同的机器上。
-
关键业务的保护
提高后台服务的可用性,把故障隔离起来,阻止多米诺骨牌效应,如果流量过大,需要对业务降级。已保证关键业务的流转。
说白了就是干两件事、一是提高整体架构的吞吐量,二是提高系统的稳定性,让系统的可用性更高。
2. 如何提高架构性能
- 缓存系统
- 异步调用
- 负载均衡
- 数据分区
- 数据镜像
3. 如何提高架构稳定性
- 服务拆分
- 服务冗余
- 限流降级
- 高可用架构
- 高可用运维
4. 分布式系统的核心

5. 全栈监控
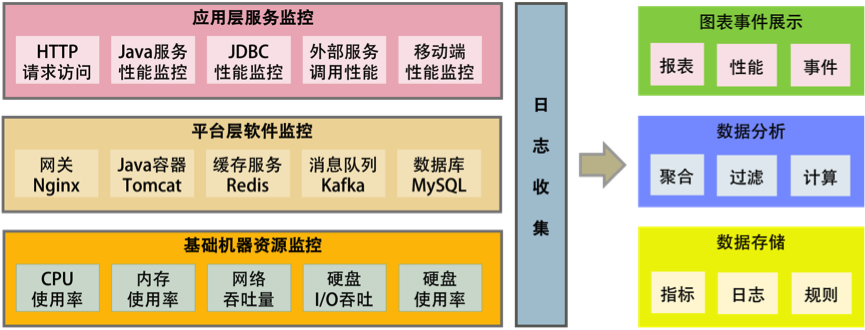
- 基础层:监控主机和底层资源。比如:CPU、内存、网络吞吐、硬盘I/O、硬盘使用等。
- 中间层:就是中间件层的监控。比如:Nginx、Reids、ActiveMQ、Kafka、MySQL、Tomcat等。
- 应用层:监控应用层的使用。比如:HTTP访问吞吐量、响应时间、返回码、调用链路分析、性能瓶颈、还包括用户端的监控。
6. 服务治理
- 梳理服务之间的依赖关系 (zipkin)
- 服务状态和服务声明周期管理 (服务发现)
- 整体架构版本管理 (类似于Springboot和Spring clound之间的版本对应)
- 资源/服务调度
- 服务状态的维持和拟合(一种不预期的变化会维持服务状态,例如服务挂掉。预期的变化会拟合服务状态、例如服务启动)
- 服务的弹性伸缩和故障迁移 (docker、kubernetes)
- 服务工作流和编排
7. 总结
7.1 构建分布式系统面临的问题
- 分布式系统的硬件故障发生率高。故障发生是常态,需要尽可能地将运维流程自动化。
- 需要良好的设计服务,避免某服务的单点故障对依赖它的其他服务造成大面积影响。
- 为了容量的可伸缩性,服务的拆分、自治和无状态变得更加重要,可能需要对老的软件逻辑做大的修改。
- 老的服务可能是异构的,此时需要让他们使用标准的协议,以便可以被调度、编排、且互相之间可以通信。
- 服务软件故障的处理也变得复杂,需要优化的流程,以加快故障的恢复。
- 为了管理各个服务的容量,让分布式系统发挥出最佳性能,需要有流量调度技术。
- 分布式存储会让事务处理变得复杂;在事务遇到故障无法被自动恢复的情况下,手动恢复流程也会变得复杂。
- 测试和查错的复杂度增大。
- 系统的吞吐量会变大,但响应时间会变长。
7.2 了解一些解决方案
- 需要有完善的监控系统,以便对服务运行状态有全面的了解。
- 设计服务时要分析其依赖链;当非关键服务故障时,其他服务要自动降级功能,避免调用该服务。
- 重构老的软件,使其能被服务化;可以参考 SOA 和微服务的设计方式,目标是微服务化;使用 Docker 和 Kubernetes 来调度服务。
- 为老的服务编写接口逻辑来使用标准协议,或在必要时重构老的服务以使得它们有这些功能。
- 自动构建服务的依赖地图,并引入好的处理流程,让团队能以最快速度定位和恢复故障,详见《故障处理最佳实践:应对故障》一文。
- 使用一个 API Gateway,它具备服务流向控制、流量控制和管理的功能。
- 事务处理建议在存储层实现;根据业务需求,或者降级使用更简单、吞吐量更大的最终一致性方案,或者通过二阶段提交、Paxos、Raft、NWR 等方案之一,使用吞吐量小的强一致性方案。
- 通过更真实地模拟生产环境,乃至在生产环境中做灰度发布,从而增加测试强度;同时做充分的单元测试和集成测试以发现和消除缺陷;最后,在服务故障发生时,相关的多个团队同时上线自查服务状态,以最快地定位故障原因。
- 通过异步调用来减少对短响应时间的依赖;对关键服务提供专属硬件资源,并优化软件逻辑以缩短响应时间。
本系列文章Github 后端进阶指南 已收录,此项目正在完善中,欢迎star。
公众号内文章都是博主原创,并且会一直更新。如果你想见证或和博主一起成长,欢迎关注!

正文到此结束
- 本文标签: src 分布式 灰度发布 tomcat 集群 需求 Uber id 一致性 自动化 cat GitHub MQ 数据镜像 测试 tar API 总结 IO 数据分区 并发 协议 SOA 软件 ActiveMQ 分布式系统 微服务 Nginx 负载均衡 管理 文章 springboot 限流 zip https 数据 Docker http zipkin 单元测试 spring git UI Kubernetes 主机 高可用 缓存 mysql ip sql 时间
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

