JAVA面试系列 - MySQL InnoDB 索引介绍
概述
先来看到题,建表语句:
create table user(
`id` bigint auto_increment COMMENT '主键ID',
`age` int not null COMMENT '年龄',
`name` varchar(1024) not null COMMENT '姓名',
`country` varchar(1024) not null COMMENT '国家',
`city` varchar(1024) not null COMMENT '城市',
PRIMARY KEY (`id`),
KEY `IDX_NAME` (`name`),
KEY `IDX_AGE` (`age`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户信息';
除了主键外,建立了2个索引,name和age,那么下面两句sql分别会命中哪些索引呢?
select * from user where name='yang' and age=10; select * from user where name='yang' or age=10;
如果对这道题没啥思路的,那么就往下看吧,看完本文后相信答案也就出来了。
页
InnoDB是一个将表中的数据存储到磁盘上的存储引擎,所以即使关机后重启我们的数据还是存在的。而真正处理数据的过程是发生在内存中的,所以需要把磁盘中的数据加载到内存中,如果是处理写入或修改请求的话,还需要把内存中的内容刷新到磁盘上。而我们知道读写磁盘的速度非常慢,和内存读写差了几个数量级,所以当我们想从表中获取某些记录时,InnoDB存储引擎需要一条一条的把记录从磁盘上读出来么?不,那样会慢死,InnoDB采取的方式是: 将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB中页的大小一般为 16KB。 也就是在一般情况下,一次最少从磁盘中读取16KB的内容到内存中,一次最少把内存中的16KB内容刷新到磁盘中。
这里不对InnoDB的页做过多介绍,有兴趣的同学可以研究这两篇文章: InnoDB记录存储结构 , InnoDB数据页结构 。
索引
为什么需要索引呢?索引可以帮助我们解决什么问题?
查字典大家都了解吧,碰到一个不认识的字,会用笔划的方式进行查询,如下图

其实这个目录就是索引,帮助你能够更快的按照某种规则查找到你需要的内容。试想下,如果没有这个『笔划索引』,如果要找一个字,怎么办?只能一页一页翻了,需要全部遍历。如果字典的排序是按照笔划数排序的,那么你还能用二分查找的方式,加速查找过程。哈哈,扯远了,回过来,索引的存在,其实就是 将无序的数据变成有序(相对),提高检索速度。
大家都知道,InnoDB的索引使用的数据结构是B+树,那么为什么是B+树呢?在介绍B+树索引机制前,我们先了解另外两种数据解构,哈希和B树。
哈希索引
说到索引,我们很容易想到通过哈希的方式实现,时间复杂度O(1)。相信在你的日常业务代码中,应该会经常出现下面的代码,将一个list根据某个key转化为Map,其实就这个就是索引思想。
Map<Long, User> id2User = Maps.uniqueIndex(users, User::getId);
哈希索引示意图:
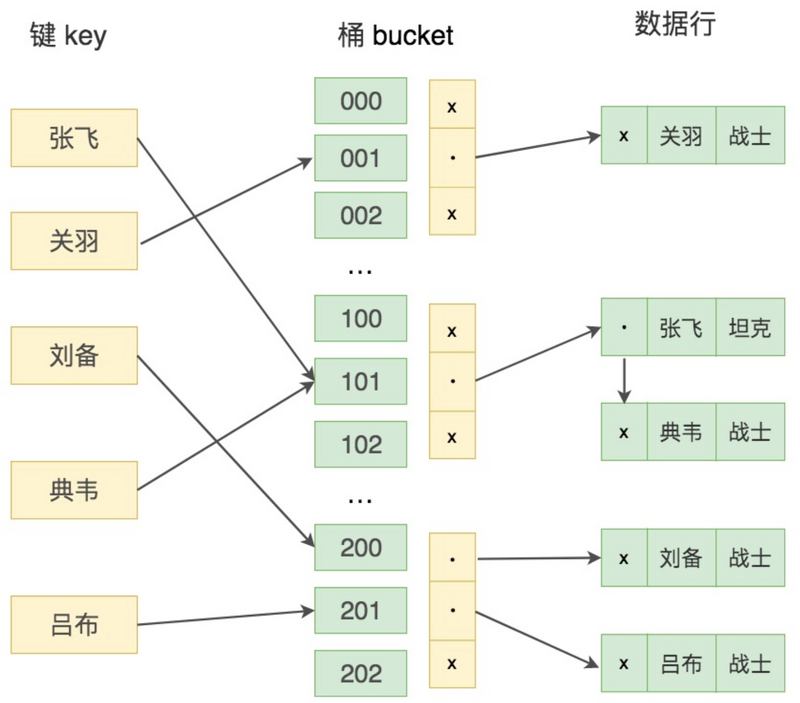
键值key通过Hash映射找到bucket。在这里bucket指的是一个能存储一条或多条记录的存储单位。一个桶的结构包含了一个内存指针数组,其中的每一行数据都会指向下一条,形成链表结构,当遇到Hash冲突时,会在桶中进行键值的查找。
采用Hash进行检索效率非常高,如果查找的字段建立了索引,那么基本上一次检索就可以找到数据。但是大家忽略了,查找场景并不只有精确检索( where name=xxx ),还有范围检索、模糊检索等等。
Hash索引主要存在以下缺点:
- 没法利用索引进行排序,即 ORDER BY,因为 Hash 索引指向的数据是无序的,因此无法起到排序优化的作用。例如上述案例中需要按照name排序,虽然name字段建立了索引,但是不是有序的,所以对排序效率无任何正向作用。
- 不支持最左匹配原则,即联合索引。因为Hash索引在计算Hash值时,是将索引键合并后再一起计算Hash值,所以不会对每个索引单独计算Hash值,因此如果用到联合索引的一个或几个索引时,联合索引无法被利用。
- 不支持范围查询,同样是因为 Hash 索引指向的数据是无序的,所以没法对 where id > 10 这样的范围查询语句有任何效率提升的作用。
B树索引
B树和B+树的区别

如图所示,区别有以下两点:
- B+树中只有叶子节点会带有指向记录的指针(ROWID),而B树则所有节点都带有,在内部节点出现的索引项不会再出现在叶子节点中。
- B+树中所有叶子节点都是通过指针连接在一起,而B树不会。
B+树的优点:
- 非叶子节点不会带上ROWID,这样,一个块中可以容纳更多的索引项,一是可以降低树的高度。二是一个内部节点可以定位更多的叶子节点。
- 叶子节点之间通过指针来连接,范围扫描将十分简单,而对于B树来说,则需要在叶子节点和内部节点不停的往返移动。
B树的优点:
- 对于在内部节点的数据,可直接得到,不必根据叶子节点来定位。
可以看到,B+树的两个优点对于提升DB检索效率都是非常有用的。第一个在一定大小的空间中可以存放更多索引,降低树的高度,即检索时间。第二个在对于范围扫描更加方便。
B+树索引
索引结构
单条记录的结构
先看下mysql中一行记录的结构示意图
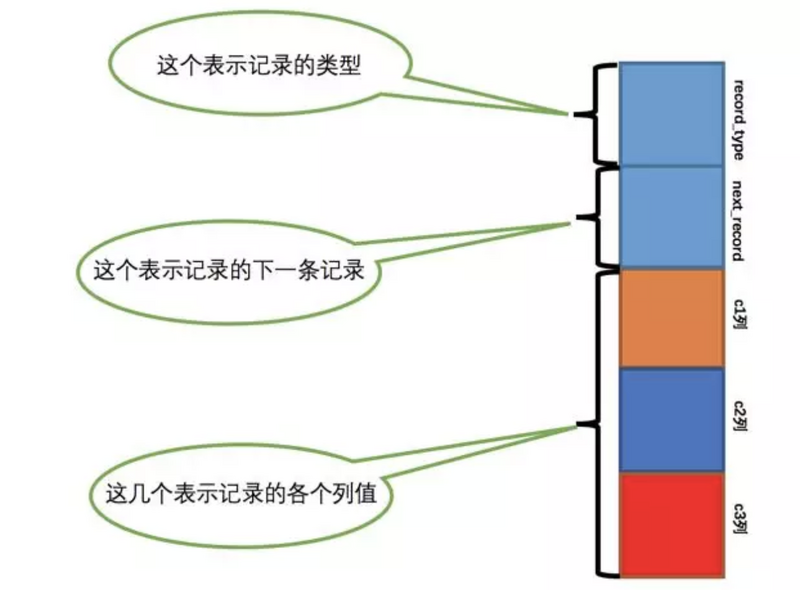
主要几个部分:
-
record_type:记录头信息的一项属性,表示记录的类型,0表示普通记录、1表示目录项、2表示最小记录、3表示最大记录 -
next_type:记录头信息的一项属性,表示下一条地址的偏移量,为了方便大家理解,我们都会用箭头来表明下一条记录是谁。 -
各个列的值:就是各个数据列的值,其中我们用橘黄色的格子代表c1列,深蓝色的格子代表c2列,红色格子代表c3列。 -
其他信息:除了上述3种信息以外的所有信息,包括其他隐藏列的值以及记录的额外信息。
单页结构
然后再看下单个页的结构示意图
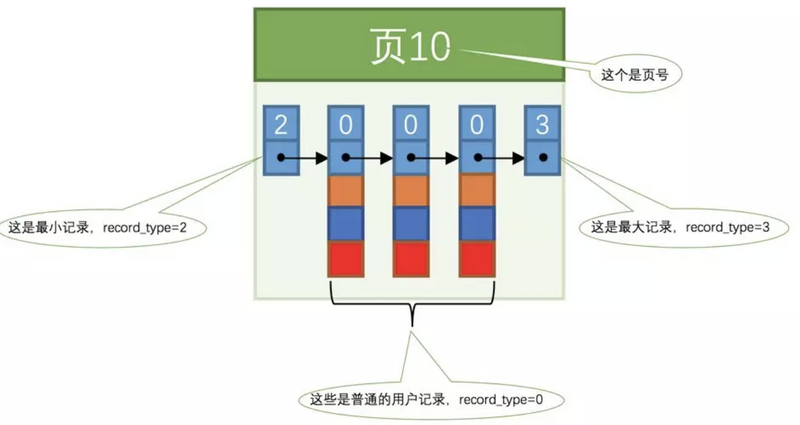
3条普通记录,一条最小记录,一条最大记录,5条记录形成单向链表。
多页结构
上面说的每个页的大小是16KB,为了便于说明问题,假设每页只能放3条普通记录,增加记录就需要增加页,下面是多页结构示意图:

几点需要注意
- 下一个数据页的主键值必须大于上一个页中的主键值
- 新分配的数据页编号可能并不是连续的,也就是说我们使用的这些页在存储空间里可能并不挨着。它们只是通过维护着上一个页和下一个页的编号而建立了链表关系
- 单页之间是单向链表,多页之间是双向链表
因为这些 16KB 的页在物理存储上并不挨着,所以如果想从这么多页中根据主键值快速定位某些记录所在的页,我们需要给它们做个目录,每个页对应一个目录项,每个目录项包括下边两个部分:
key page_no
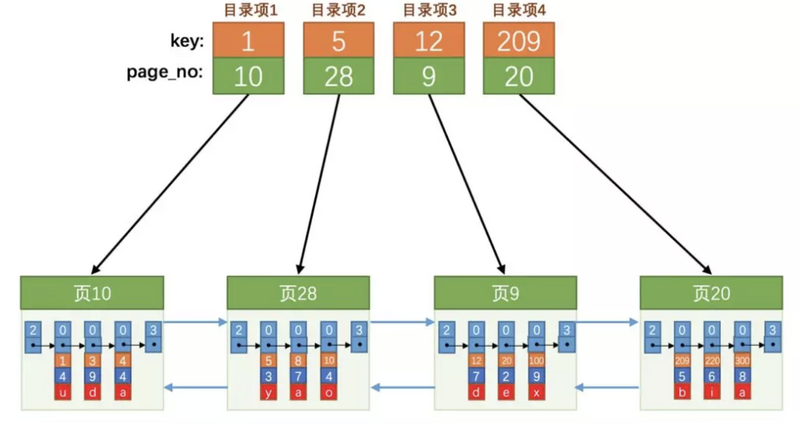
然后我们看下如何寻找id=20的记录。
- 先从目录项中根据二分法快速确定出主键值为
20的记录在目录项3中(因为12 < 20 < 209),它对应的页是页9。 - 再在
页9中根绝二分法快速定位具体的记录。
这样是不是查找数据就快了?嗯,正是这个目录的功劳!对了,忘记说了,这个目录有个别名,叫 索引 。
下面再看一个高度为3的B+树索引:
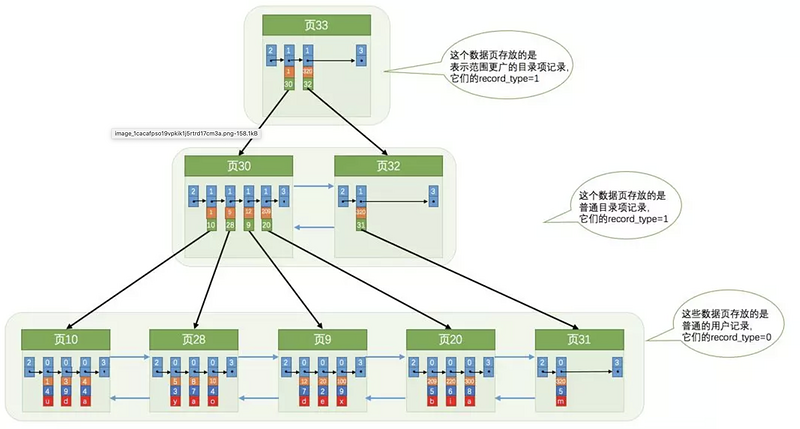
从图中可以看出来,一个 B+ 树的节点其实可以分成好多层,设计 InnoDB 的大叔们为了讨论方便,规定最下边的那层,也就是存放我们用户记录的那层为第 0 层,之后依次往上加。上边我们假设一页只能放3条普通记录,其实真实环境中一个页存放的记录数量是非常大的,假设,假设,假设所有的数据页,包括存储真实用户记录和目录项记录的页,都可以存放 1000 条记录,那么:
- 如果
B+树只有1层,也就是只有1个用于存放用户记录的节点,最多能存放1000条记录。 - 如果
B+树有2层,最多能存放1000×1000=1000000条记录。 - 如果
B+树有3层,最多能存放1000×1000×1000=1000000000条记录。 - 如果
B+树有4层,最多能存放1000×1000×1000×1000=1000000000000条记录。哇咔咔~这么多的记录!!!
你的表里能存放 1000000000000 条记录么?所以一般情况下,我们用到的 B+ 树都不会超过4层,那我们通过主键去查找某条记录最多只需要做4个页面内的查找,又因为在每个页面内有所谓的 Page Directory (页目录),所以在页面内也可以通过二分法实现快速定位记录,是不是很高效!
聚集和非聚集索引
下面看个例子,表创建语句如下:
create table user(
`id` bigint auto_increment COMMENT '主键ID',
`age` int not null COMMENT '年龄',
`name` varchar(1024) not null COMMENT '姓名',
`country` varchar(1024) not null COMMENT '国家',
`city` varchar(1024) not null COMMENT '城市',
PRIMARY KEY (`id`),
KEY `IDX_NAME` (`name`),
KEY `IDX_COUNTRY_CITY` (`country`, `city`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户信息';
可以看到一共建立了3个索引,主键id索引、name索引、country+city的联合索引。其中id就是聚集索引,name就是非聚集索引(二级索引)。
简单概括:
- 聚集索引就是以 主键 创建的索引
- 非聚集索引就是以 非主键 创建的索引
区别:
- 聚集索引在叶子节点存储的是 表中的数据
- 非聚集索引在叶子节点存储的是 主键和索引列
- 使用非聚集索引查询出数据时, 拿到叶子上的主键再去查到想要查找的数据 。(拿到主键再查找这个过程叫做 回表 )
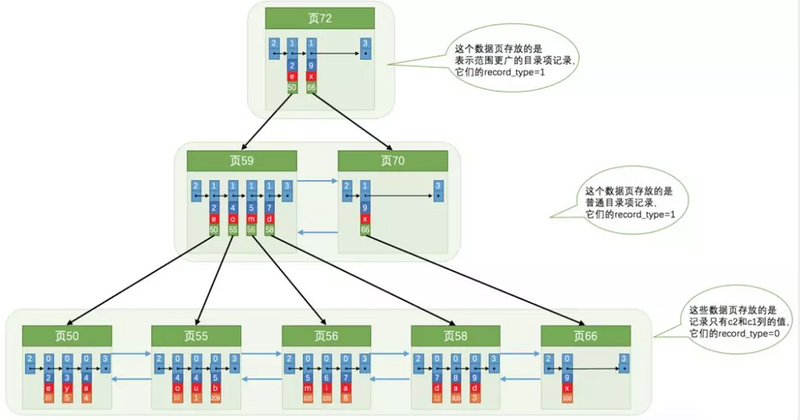
以上有3个索引,所以会有3颗B+树
- 聚集索引树,索引是主键id,即上面图中的黄色框对应记录中的id字段,然后在叶子节点中存储的是表中数据,即有多少个字段就会在黄色方块下面有多少个数据方块
- 非聚集索引树,索引是字段name,在叶子节点中存储的是主键id,即黄色方块后面只会有一个方块,存储主键id,然后如果要获取除id和name外的字段字段,需要在做一次检索,即回表
- 非聚集索引树,索引字段是country+city,和情况2类似,知识索引字段有2个方块,然后叶子节点会存储主键id,所以叶子节点中数据方块是3个。如下图
索引最左匹配原则
上面提到了联合索引,联合索引有一个最左匹配原则,介绍如下:
- 索引可以简单如一个列
(a),也可以复杂如多个列(a, b, c, d),即 联合索引 。 - 如果是联合索引,那么key也由多个列组成,同时,索引只能用于查找key是否 存在(相等) ,遇到范围查询
(>、<、between、like左匹配)等就 不能进一步匹配 了,后续退化为线性查找。 - 因此, 列的排列顺序决定了可命中索引的列数 。
例子:
- 如有索引
(a, b, c, d),查询条件a = 1 and b = 2 and c > 3 and d = 4,则会在每个节点依次命中a、b、c,无法命中d。(很简单:索引命中只能是 相等 的情况,不能是范围匹配)
=、in自动优化顺序
不需要考虑=、in等的顺序,mysql会自动优化这些条件的顺序,以匹配尽可能多的索引列。
例子:
- 如有索引
(a, b, c, d),查询条件c > 3 and b = 2 and a = 1 and d < 4与a = 1 and c > 3 and b = 2 and d < 4等顺序都是可以的,MySQL会自动优化为a = 1 and b = 2 and c > 3 and d < 4,依次命中a、b、c。
参考文档
- B树和B+树的区别
- 数据库两大神器【索引和锁】
- MySQL的索引
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

