真的,你不可不知的 Java 反射

古时的风筝原创文章
第一次在程序的世界中听到反射这个概念,我有些疑惑,不知道它和光的反射有什么异曲同工之处。 后来,等我真正了解它的时候,才发现,好像并没有什么关系。 可能就是翻译的有问题而已。
那么问题来了,你了解反射到底是个什么吗,灵魂三问。
1、反射的作用,为什么要用反射?
2、反射在常用框架中的应用,Spring 中哪些地方使用了反射你知道吗?
3、反射为什么性能比较差?

遥想当年,我初识反射
遥想刚毕业那年,水到不行,第一次真正见识反射还是在某个项目上。当时我还在做 .NET ,有一个为某国企开发 Portal 系统的项目,其中有个「待办任务」模块,任务来自其他几个系统,话说国企就是国企,系统真是多,这些待办任务来自 5 个不同的系统,据说这还不是全部。我表示无话可说。

当时也根本不用消息队列,自然就想到两种方案,要么我们做接口定时去另外 5 个系统拉数据,要么那 5 个系统一产生待办就直接推给我们。定时去其他系统拉数据会有一个延时的问题,而且据说有两个系统用的服务器很古老,配置很低,别谈什么并发了,请求频繁点儿都不行,没想到国企也不是很有钱(呵呵)。所以最终决定我们写接口,其他 5 个系统实时请求我们的接口推过来数据。
然后我们就开始动手写接口文档,提供了接口地址、请求参数、数据格式等等,经过一场友好的会议讨论后,有 3 系统接口人表示数据格式不能按照我们的来,说是他们的待办实体已经确定了,改动太大,只能按照他们内部的格式转换成字符串传过来。好吧,谁让人家是内部人开发的呢,字符串就字符串吧。

说了这么多跟反射有个啥子关系,来了,重点来了。
当时,我作为一个菜鸟,当时我一下子想到两种方案。
第一种:为 5 个系统各开一个接口,对应的自然就可以用不同的逻辑解析主体信息了。
但是我有觉得,这种写法虽然清晰,但会不会太傻了一些,于是,我想到了第二种方式,根据传过来的系统来源参数(有一个参数表示来自那个系统,用一个字符串表示)判断,几个 if 区分,当时我甚至想到了如果方法过长,要单独提取出去变成几个私有方法,以便可以内联(心想,我竟然如此牛X)。
于是我把这个想法愉快的告诉了我的组长,听罢,他默默点上了一支烟,径自走到了窗前,刚抽了两口反应过来不能抽烟,赶紧掐灭,又走了回来,从始至终,一言未发。我只好回到座位,一定是组长惊叹于我刚刚毕业,竟有如此才华,我不禁心里暗暗得意。
半个小时之后,组长发过来消息:
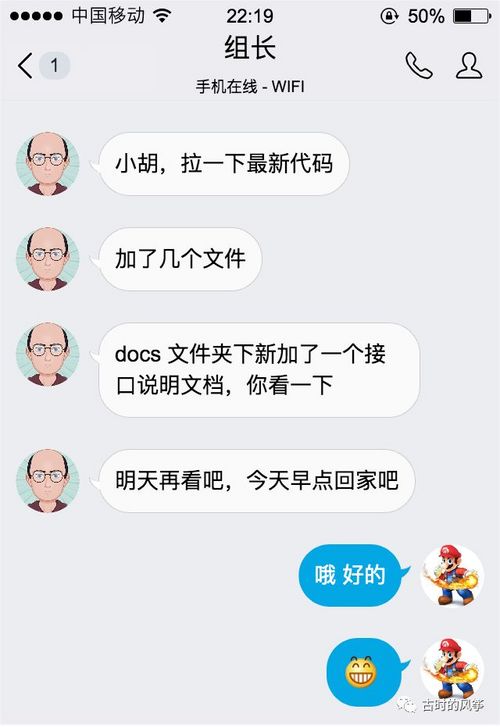
先回家!当然,我还是先回家了。第二天到公司,第一件事儿,获取最新代码,多了个 interface、一个配置文件和 5 个普通类文件,一脸懵的我选择先看看那个说明文档。
怎么可能,竟然没用我昨天说的方案。等等,这是什么方法,能行吗?大致思路是这样的:
首先 5 个普通类都实现自那个 interface,里面都只有一个方法,用来处理请求主体的。然后读配置文件,配置文件就是系统来源那个参数作为 key,另外那 5 个普通类的完全类名作为 value。然后用了 reflect 库下什么方法加载了那 5 个类,然后再调用里面的方法。
那时才知道,有一种方式叫做反射,竟然比 if 大法还好用。
什么是反射
反射这一概念最早由编程开发人员Smith在1982年提出,主要指应用程序访问、检测、修改自身状态与行为的能力。几乎所有的面向对象的开发语言都提供了反射机制。
Java 中的反射是指在程序运行时动态获取和操作当前程序中类型,比如获取类(class)的名称、实例化一个类实体、操作属性、调用方法等。
Java 是编译型语言,绝大多数对象在编译期就确定了类型。而反射为 Java 提供了动态编译的实现方式,也就是在 JVM 已经运行的情况下动态的加载并操作类型。
比如下面这个初始化语句,在编译之后就已经确定了 user 对象为 User 类型,在 JVM 启动之后就被加载到 JVM 中了。
kite.lab.reflect.User user = new kite.lab.reflect.User();
而下面这个利用反射的操作,在编译和 JVM 启动的时候并没有确定类型,而是当程序执行到这两行代码的时候才加载 kite.lab.reflect.User 类,并在调用 newInstance() 方法时才实例化 User 对象。
Class clazz = Class.forName("kite.lab.reflect.User");
Object userInstance = clazz.newInstance();
反射的基本用法
反射虽然听上去高深,但用起来还是很简单的,它就是 JDK 提供给我们的一套简单易用的 API,在 java.lang.reflect 这个 package 下,再加上一个 java.lang.Class 。
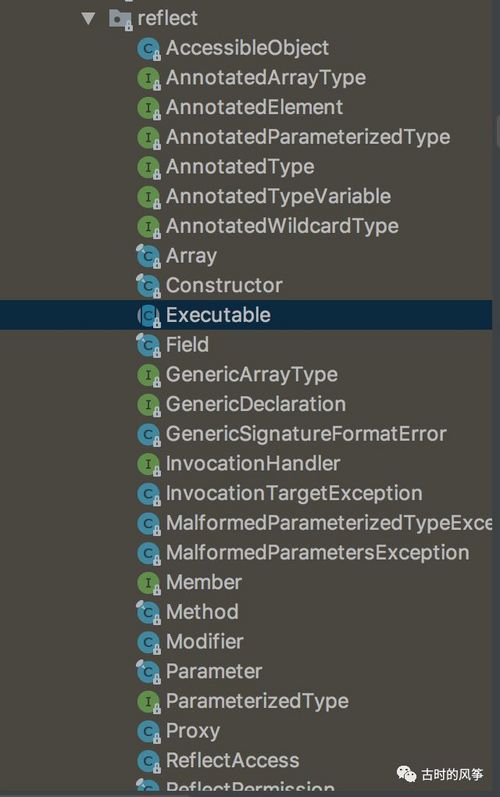
java.lang.Class 提供了一系列操作类型的方法,常用的就是获取类的全名、获取属性集合、根据名称获取属性、获取方法集合、根据方法名称获取方法、实例化一个对象、获取属性值、修改属性值、调用方法等。
下面是一个简单的例子,演示了反射的基本用法。
public class User {
static String country;
private String name;
public int age;
private Result<String> result;
public void say(String world){
System.out.println("我说:" + world);
}
private void writeNote(){
System.out.println("写日记");
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Result<String> getResult() {
return result;
}
public void setResult(Result<String> result) {
this.result = result;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '/'' +
", age=" + age +
'}';
}
}
public class ReflectTest {
public static void main(String[] args) throws Exception{
reflectDemo();
}
public static void reflectDemo() throws Exception{
Class clazz = Class.forName("kite.lab.reflect.User");
Field[] declaredFields = clazz.getDeclaredFields();
for(Field declaredField:declaredFields){
System.out.println(declaredField.getName());
}
Method[] methods = clazz.getDeclaredMethods();
for(Method method:methods){
System.out.println(method.getName());
}
Object userInstance = clazz.newInstance();
Method sayMethod = clazz.getDeclaredMethod("say", String.class);
sayMethod.invoke(userInstance,"你好");
Method writeNoteMethod = clazz.getDeclaredMethod("writeNote");
writeNoteMethod.setAccessible(true);
writeNoteMethod.invoke(userInstance);
}
}
上面例子演示了获取 User 类的所有声明的属性和方法,并调用了 public 的 say() 方法和 private 的 writeNote() 方法。
反射的使用场景
在能确定类型的情况下能不用反射就不用反射,因为反射的性能比直接调用的性能略差。大多数在无法事先确定类型的时候才会用到反射。
一般在设计通用型框架的时候会用到反射,所谓通用型框架,指的是框架搭好了,你可以拿去用,但是里面有很多的细节需要结合你的具体需求来实现。
举个例子,其实和前面初识反射的经历中所用到的方案是同一个意思。比方说我要实现一个日志采集分析框架,框架要实现的就是收集日志,然后分析出警告信息、异常信息的条数、占比以及对高级别异常做特殊标记等。
那如果我这个框架只是给使用了 SLF4J 的 Java 项目使用就简单了,可现在要做的是不限制日志来自哪儿,可以是 SLF4J,也可以是其他日志框架,甚至可以来自 Nginx、Redis 或者你自己定义的日志格式。 假设框架有诸多细节,包括数据怎么流转、如何分析等,这些都不提,仅仅说数据收集这块,这块儿是整个框架中存在不确定性的地方,因为不知道你的日志来源是哪里。
基于以上原因,框架规定好了最后需要的日志格式,比如"类型(exception|warn|info):日志内容:时间戳"这种格式。框架给你开放一个接口出来,你实现接口,按照这种格式返回就好了。
public interface ILogHandler {
String collect();
}
然后在配置文件中配置上你自定义的接口实现类。
public class LogCollectHander implements ILogHandler{
@Override
public String collect(){
// 获取你的日志 并返回固定格式
return "类型(exception|warn|info):日志内容:时间戳";
}
}
然后在系统中增加配置,比如这样配置:
kite:
log:
analysis:
handler: org.my.project.LogCollectHander
那像 org.my.project.LogCollectHander 这个实现类就是框架之外你自定义的,每个使用框架的开发者都会定义不同的实现类,所以,框架在编译的时候就事先不知道具体类型,只有当程序运行到这里的时候,通过配置文件获取实现类的全名,然后根据反射获取 class,然后调用 collect() 方法,实现逻辑差不多是这样:
Class clazz = Class.forName("org.my.project.LogCollectHander");
ILogHandler logHandler = (ILogHandler)clazz.newInstance();
logHandler.collect();
这整个过程其实用到了一个设计模式-「工厂模式」。完善一下代码如下:
public class MyFactory {
private static class SingletonHolder {
private static final MyFactory INSTANCE = new MyFactory();
}
private MyFactory (){}
public static final MyFactory create() {
return SingletonHolder.INSTANCE;
}
public ILogHandler build() throws Exception{
// 来自于配置文件
String className = "org.my.project.LogCollectHander";
Class clazz = Class.forName(className);
ILogHandler logHandler = (ILogHandler)clazz.newInstance();
return logHandler;
}
}
//调用
ILogHandler myLogCollectHander = MyFactory.create().build();
myLogCollectHander.collect();
这样一来,利用反射,轻松把不通用的地方整合到了通用框架中。
概括说来,反射可以兼容通用框架中不通用(个性化)的部分。
Spring 控制反转/依赖注入
类似的通用型框架有很多,比如 Spring 中就有很多地方用到了反射,Spring 核心科技「控制反转(IoC)-依赖注入(DI)」就用到了反射。控制反转的意思就是将控制权由开发者转交给 Spring 框架,我们用 Spring MVC 的时候,经常会将 bean 写到 xml 配置文件中,比如这样:
<bean id="userService" class="org.my.project.userServiceImpl"></bean>
简单来说,Spring 框架在启动的时候会加载这些 bean 所指定的 class,注册到一个 map 中,之后,用到的时候直接在 map 中取就可以了。那这个加载的过程就要用到反射。
JDK 数据库操作部分
JDK 中关于数据库驱动的部分,也用到反射,不管你是用 mysql 还是 oracle,只要你配置好对应的驱动配置信息并添加好驱动依赖包,JDK 就会利用反射动态的加载对应驱动类,然后执行驱动类中具体的方法。
Dubbo SPI
Dubbo 框架中的 SPI 技术也用到了反射。
这么说吧,当你阅读开源代码时,碰到配置文件中配置了具体类的完全名称的地方,那几乎都会用到反射。
动态代理,比如AOP
动态代理技术也会用到反射,要在生成的代理类中动态的调用原始被代理的方法,比如 AOP。
实体类拷贝
还有我们经常会遇到的两个 bean 实体的属性拷贝,例如 Spring 中的 BeanUtils.copyProperties() 方法。
IDE 和调试器
另外,还有我们每天开发都会用到的编辑器中和调试工具,你在编辑器中敲下"."之后,编辑器会智能给你相关方法和属性的列表,这就是通过反射实现的。调式过程中,监视属性值等也都是通过反射实现。
反射为什么性能比较差
说起反射,大家可能都知道性能差,每一本讲 Java 的书籍提到反射的部分都会说反射性能比较差,能不用反射的地方尽量不要用。那反射的性能为什么差呢?
根本的原因就是因为反射是动态加载,所以 jit 对其所做的优化极其有限。
jit - 即时编译器,是 JVM 优化性能的杀手级利器,它会对热点代码进行一系列优化,比如非常重要的优化手段-方法内联。而反射的代码则享受不到这种待遇。
反射中性能最差的部分在于获取方法和属性的部分,比如 getMethod() 方法,是因为获取这个方法需要遍历所有的方法列表,包括父类。而如果不是反射的话,那这个方法地址都是提前确定的。
还有在 method#invoke() 方法执行的过程中需要执行要对参数做封装和解封操作,invoke 方法的参数是 Object[] 类型,所以传入的参数要转换为 Object 并封装成数组,而到了真正执行方法的时候,还要把 Object 数组解封。这样一来一回就浪费了不少时间。
另外还需要需要检查方法可见性和参数的校验,这样做是为了保证调用安全,检查的过程也要耗时。
总结
那其实除非发生大量的反射调用,正常使用的情况下,性能只是略差而已,这样的性能损耗比起反射带来的灵活性来讲可以忽略不计,比如 Spring 框架要靠反射来支撑最核心的技术,Spring 给我们日常开发带来的好处和它采用反射技术对性能的影响而言,那自然不值一提。
另外,如果真的是会频繁调用反射方法,采用缓存的方案可以很大程度上优化性能。比如在第一次调用某个方法的时候将它缓存起来,下次再调用直接从缓存拿就可以了。
还可以读:
为什么要使用接口编程
系统内存爆满,原来是线程搞的鬼
Spring Cloud 系列吐血总结
-----------------------
公众号:古时的风筝
一个斜杠程序员,一个纯粹的技术公众号,多写 Java 相关技术文章,不排除会写其他内容。
【鱼怕是不会飞了!】

正文到此结束
- 本文标签: 开发 ACE Spring cloud 服务器 数据库 调试 灵魂 消息队列 参数 http id Nginx Oracle 开发者 时间 实例 快的 src AOP java 抽烟 UI 需求 遍历 copyProperties build IO spring 科技 配置 代码 解析 BeanUtils dubbo ioc mysql https map API 程序员 开源 bean 并发 sql IDE 智能 value 总结 Service 缓存 翻译 安全 redis CTO key final 文章 JVM 编译 线程 数据 设计模式 XML
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

