《 面试又挂了》这次竟然和 Random 有关......
小强最近面试又翻车了,然而令他郁闷的是,这次竟然是栽到了自己经常在用的 Random 上......
面试问题
既然已经有了 Random 为什么还需要 ThreadLocalRandom?
正文
Random 是使用最广泛的随机数生成工具了,即使连 Math.random() 的底层也是用 Random 实现的 Math.random() 源码如下:
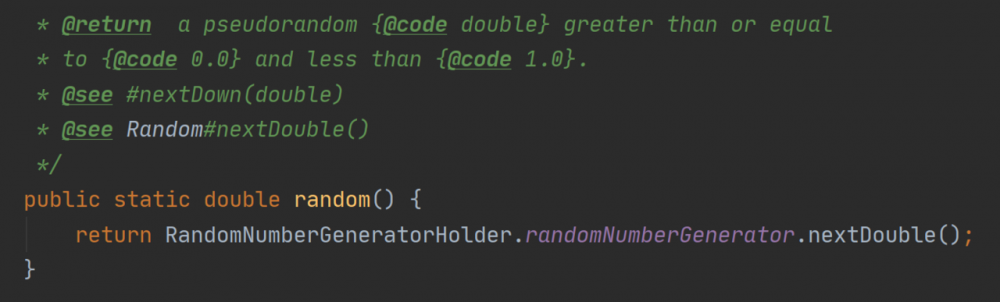
Math.random() 直接指向了
Random.nextDouble()
方法。
Random 使用
这开始之前,我们先来了解一下 Random 的使用。
Random random = new Random();
for (int i = 0; i < 3; i++) {
// 生成 0-9 的随机整数
random.nextInt(10);
}
复制代码
以上程序的执行结果为:
1
0
7
Random 源码解析
可以看出 Random 是通过 nextInt() 方法生成随机整数的,那他的底层的是如何实现的呢?我们来看他的实现源码:
/**
* 源码版本:JDK 11
*/
public int nextInt(int bound) {
// 验证边界的合法性
if (bound <= 0)
throw new IllegalArgumentException(BadBound);
// 根据老种子生成新种子
int r = next(31);
// 计算最大值
int m = bound - 1;
// 根据新种子计算随机数
if ((bound & m) == 0) // i.e., bound is a power of 2
r = (int)((bound * (long)r) >> 31);
else {
for (int u = r;
u - (r = u % bound) + m < 0;
u = next(31))
;
}
return r;
}
复制代码
从以上源码我们可以看出,整个源码最核心的部分有两块:
- 根据老种子生成新种子;
- 根据新种子计算出随机数。
根据新种子计算出随机数的代码已经很明确了,我们需要确认一下 next() 方法是如何实现的,继续看源码:
/**
* 源码版本:JDK 11
*/
protected int next(int bits) {
// 声明老种子和新种子
long oldseed, nextseed;
AtomicLong seed = this.seed;
do {
// 获取原子变量种子的值
oldseed = seed.get();
// 根据当前种子计算出新种子的值
nextseed = (oldseed * multiplier + addend) & mask;
} while (!seed.compareAndSet(oldseed, nextseed)); // 使用 CAS 更新种子
return (int)(nextseed >>> (48 - bits));
}
复制代码
根据以上源码可以看出, 在使用老种子去获取新种子的时候,如果是多线程操作,则同一时刻只会有一个线程 CAS (Conmpare And Swap,比较并交换) 成功,其他失败的线程会通过自旋等待获取新种子,因此会有一定的性能消耗 。
这也是为什么 JDK 1.7 会引入 ThreadLocalRandom 的答案了,它的出现主要为了提升多线程情况下 Random 的执行效率。那它是如何来提升的?接下来一起来看。
ThreadLocalRandom 使用
我们先来看 ThreadLocalRandom 的类关系图:
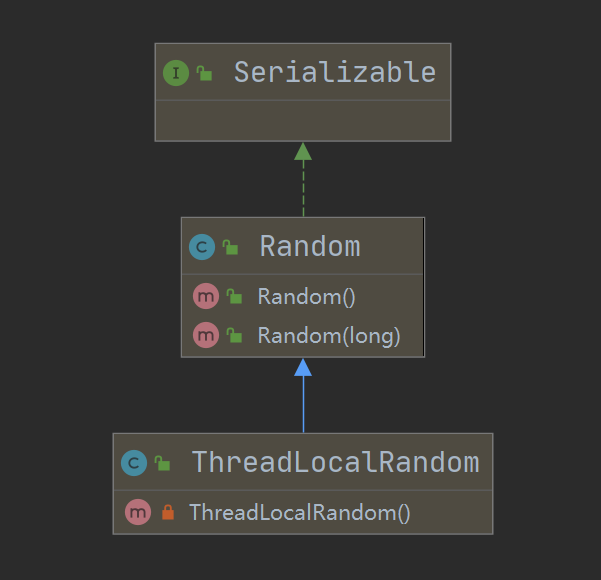
可以看出 ThreadLocalRandom 继承于 Random 类,先来看它的使用:
ThreadLocalRandom threadLocalRandom = ThreadLocalRandom.current();
for (int i = 0; i < 3; i++) {
// 生成 0-9 的随机数
System.out.println(threadLocalRandom.nextInt(10));
}
复制代码
以上程序的执行结果为:
1
7
5
可以看出 ThreadLocalRandom 和 Random 一样,都是通过 nextInt() 方法实现随机整数生成的。
ThreadLocalRandom 源码解析
接下来我们来看 ThreadLocalRandom 的随机数是如何生成的,源码如下:
/**
* 源码版本:JDK 11
*/
public int nextInt(int bound) {
if (bound <= 0)
throw new IllegalArgumentException(BAD_BOUND);
// 根据老种子生成新种子
int r = mix32(nextSeed());
int m = bound - 1;
// 根据新种子计算算出随机数
if ((bound & m) == 0) // power of two
r &= m;
else { // reject over-represented candidates
for (int u = r >>> 1;
u + m - (r = u % bound) < 0;
u = mix32(nextSeed()) >>> 1)
;
}
return r;
}
复制代码
从以上源码可以看出 ThreadLocalRandom 的 nextInt() 和 Random 的 nextInt() 在写法和实现思路都很像,他们主要的区别在 nextSeed() 方法上,源码如下:
/**
* 源码版本:JDK 11
*/
final long nextSeed() {
Thread t; long r; // read and update per-thread seed
// 把当前线程作为参数生成一个新种子
U.putLong(t = Thread.currentThread(), SEED,
r = U.getLong(t, SEED) + GAMMA);
return r;
}
@HotSpotIntrinsicCandidate
public native void putLong(Object o, long offset, long x);
复制代码
从以上源码可以看出,ThreadLocalRandom 并不是像 Thread 那样使用 CAS 和自旋来获取新种子,而是在每个线程中使用每个线程中保存自己的老种子来生成新种子,因此就可以避免多线程竞争和自旋等待的时间,所以在多线程环境下性能更高。
ThreadLocalRandom 注意事项
在使用 ThreadLocalRandom 时需要注意一下, 在多线程不能共享一个 ThreadLocalRandom 对象,否则会造成生成的随机数都相同 ,如下代码所示:
// 声明多线程
ExecutorService service = Executors.newCachedThreadPool();
// 共享 ThreadLocalRandom
ThreadLocalRandom threadLocalRandom = ThreadLocalRandom.current();
for (int i = 0; i < 10; i++) {
// 多线程执行随机数并打印结果
service.submit(() -> {
System.out.println(Thread.currentThread().getName() + ":" + threadLocalRandom.nextInt(10));
;
});
}
复制代码
以上程序执行结果如下:
pool-1-thread-2:4 pool-1-thread-1:4 pool-1-thread-3:4 pool-1-thread-10:4 pool-1-thread-6:4 pool-1-thread-7:4 pool-1-thread-4:4 pool-1-thread-9:4 pool-1-thread-8:4 pool-1-thread-5:4
Random VS ThreadLocalRandom
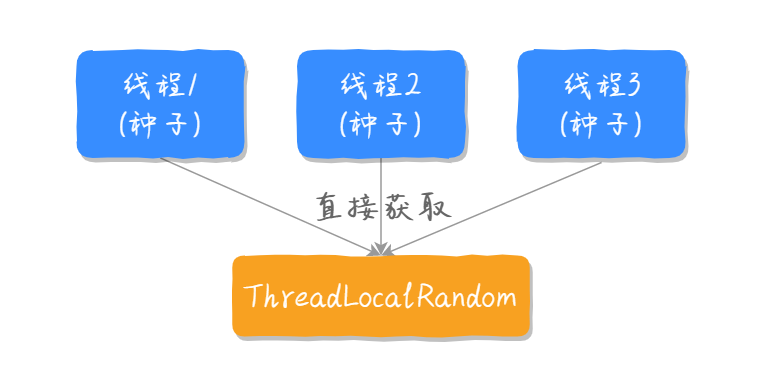
Random 生成获取新种子,如下图所示:

ThreadLocalRandom 生成获取新种子,如下图所示:
性能对比
接下来我们使用 Oracle 官方提供的性能测试工具 JMH (Java Microbenchmark Harness,JAVA 微基准测试套件),来测试一下 Random 和 ThreadLocalRandom 的吞吐量(单位时间内成功执行程序的数量):
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.Random;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadLocalRandom;
import java.util.concurrent.TimeUnit;
/**
* JDK:11
* Windows 10 I5-4460/16G
*/
@BenchmarkMode(Mode.Throughput) // 测试类型:吞吐量
//@Threads(16)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class RandomExample {
public static void main(String[] args) throws RunnerException {
// 启动基准测试
Options opt = new OptionsBuilder()
.include(RandomExample.class.getSimpleName()) // 要导入的测试类
.warmupIterations(5) // 预热 5 轮
.measurementIterations(10) // 度量10轮
.forks(1)
.build();
new Runner(opt).run(); // 执行测试
}
/**
* Random 性能测试
*/
@Benchmark
public void randomTest() {
Random random = new Random();
for (int i = 0; i < 10; i++) {
// 生成 0-9 的随机数
random.nextInt(10);
}
}
/**
* ThreadLocalRandom 性能测试
*/
@Benchmark
public void threadLocalRandomTest() {
ThreadLocalRandom threadLocalRandom = ThreadLocalRandom.current();
for (int i = 0; i < 10; i++) {
threadLocalRandom.nextInt(10);
}
}
}
复制代码
测试结果如下:

。
从 JMH 测试的结果可以看出,T hreadLocalRandom 在并发情况下的吞吐量约是 Random 的 5 倍 。
完整基准测试代码下载: github.com/vipstone/bl…
总结
本文讲了 Random 和 ThreadLocalRandom 的使用以及源码分析,Random 是通过 CAS 和自旋的方式生成随机数,在多线程模式下同一时刻只能有一个线程通过 CAS 获取到新种子并生成随机数,其他线程只能自旋等待,所以有一定的性能损耗。而在 JDK 1.7 时新增了 ThreadLocalRandom 它的种子保存在各自的线程中,因此不会有自旋等待的过程,所以高并发情况下性能更优秀。
最后,我们通过官方提供的基准测试工具 JMH 得到的结果,ThreadLocalRandom 的性能大约是 Random 的 5 倍,所以在高并发情况下尽量使用 ThreadLocalRandom。
参考 & 鸣谢 《Java 并发编程之美》翟陆续
更多 Java 原创文章,请关注我微信公众号 「Java中文社群」
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

