从一个小例子引发的Java内存可见性的简单思考和猜想以及DCL单例模式中的volatile的核心作用
环境
| OS | Win10 |
| CPU | 4核8线程 |
| IDE | IntelliJ IDEA 2019.3 |
| JDK | 1.8 -server模式 |
场景
最初的代码
一个线程A根据flag的值执行死循环,另一个线程B只执行一行代码,修改flag的值,让A线程死循环终止。
Visbility.java
public class Visbility {
private boolean flag;
public void cyclic(){
while (!flag){
}
}
public void setter(){
flag = true;
}
}
Main.java
public class Main {
public static void main(String[] args) {
Visbility visbility = new Visbility();
Thread cyclic = new Thread(visbility::cyclic);
Thread setter = new Thread(visbility::setter);
cyclic.start();
setter.start();
}
}
多次执行Main函数结果:程序很快就终止。
这是为什么呢?我没有让flag值在多线程之间内存可见呀,怎么线程setter修改flag后,cyclic线程获得了修改后的flag终止死循环?先带着疑问。
添加for循环耗时代码
接着,在setter方法里,在修改该flag之前,添加一行耗时代码(用for循环,为什么不用TimeUnit,后面会说到),此时Visbility.java如下:
public class Visbility {
private boolean flag;
public void cyclic(){
while (!flag){
}
}
public void setter(){
for (int i = 0; i < 999999; i++) ;
flag = true;
}
}
多次执行Main函数结果:程序一直不结束。
这是为什么呢?难道执行个循环99999次,CPU永远执行不完导致flag的值无法被修改该吗?还是说内存可见性的问题?
用volatile解决内存可见性
我们给flag加上 volatile 关键字进行修饰(后面有其他的方式如 锁 , System.out.println -_- 解决变量内存及时可见性),Visibility.java代码如下:
public class Visbility {
private volatile boolean flag;
public void cyclic(){
while (!flag){
}
}
public void setter(){
for (int i = 0; i < 999999; i++) ;
flag = true;
}
}
多次执行Main函数结果:程序几百毫秒后终止。
看来确实存在内存可见性的问题,线程cyclic获取到了setter线程修改后的flag并终止,解决内存可见性的方式特别多,后面再列几种;
但是结果证明了,并不是CPU执行不完了999999次的循环,而且是很快的执行完,那为什么和最初什么都没加的代码相比,加上了这99999次循环的耗时,就必须要加上volatile才能让setter线程中的flag的值被cyclic线程感知。
去掉volatile,减少for循环次数,减少耗时
继续修改代码,去掉volatile,并把for循环的次数999999减少至99999(大家不同的机器不同的环境可能需要设置不同数值),Visbility.java代码如下:
public class Visbility {
private boolean flag;
public void cyclic(){
while (!flag){
}
}
public void setter(){
for (int i = 0; i < 99999; i++) ;
flag = true;
}
}
多次执行Main函数结果:程序几百毫秒内结束。
这里我 去掉了volatile 关键字,仅仅减少了setter线程修改flag之前模拟的for循环 耗时 ,结果似乎又flag内存可见了(cyclic死循环线程终止)。
总结上面的几中情况
当setter线程修改flag之前 无任务 和 耗时相对较短的任务 时,不需要volatile修饰flag变量,cyclic线程能获得被setter修改该后的flag值;
当setter线程修改该flag之前有 耗时相对较长的任务 时,需要volatile修改flag变量,cyclic线程才能获得被setter修改该后的flag值。
几种猜想(暂未证明)
1. 在 皮秒级 内 (这也是为什么我这里模拟耗时用for循环,而不用TimeUnit,因为TimeUnit最小的单位是纳秒,开始我使用最小的单位时间TimeUnit.NANOSECONDS.sleep(1),多次执行程序,每次结果都是一直都不结束,所以我需要更小的耗时时间), JVM 已经感知到"flag"被修改,所以两个线程都获取的主存的值,第一个线程的循环终止
2. 由于setter线程的 任务实在是太小 (联想到了 进程调度算法 ),所以setter在极短时间内被CPU执行完后,线程cyclic也立刻被 同一个CPU 执行,即取的是 同一块本地内存 (CPU高速缓存)
3. 由于setter线程的任务实在是太小(联想到了进程调度算法),所以setter在极短时间内被CPU执行完后,值已经被刷新到 主存 ,cyclic获得的是主存中最新的值
本来想验证下第二种猜想,查了下,暂时无法简单的通过Java类库代码来获取当前线程是被哪个CPU执行(JNA+本地安装对应的Library:https://github.com/OpenHFT/Java-Thread-Affinity);
耗时任务的意义
有了这个耗时任务,如果上面的cyclic已经启动了, JVM 感知到(在耗时任务执行过程中,CPU早已做了多次运算了),除了cyclic这个线程以外, 没有 其他线程在操作"flag", JVM会假设"flag"的值一直都没有被改变,所以cyclic线程一直从 自身线程本地内存 中获取值(在 未使用synchronized, volatile等实现"flag"的内存可见性 时) , 所以就算setter线程修改"flag"的值,cyclic还是从自己的线程的 本地内存 中读取。
如何保证变量在内存中及时可见?
主要有两种,一种是用 volatile ,一种是 锁 ;
还有Atomic Class?底层value也是用的volatile,以及sun.misc.Unsafe: https://www.cnblogs.com/theRhyme/p/12129120.html ;
当然AQS也是volatile+sun.misc.Unsase。
Volatile保证变量在内存中及时可见
至于volatile例子上面已经写了,JAVA内存模型中VOLATILE关键字的作用: https://www.cnblogs.com/theRhyme/p/9396834.html
用锁来保证内存的可见性
锁有很多很多种,所以实现的方式也有很多,这里列几种有趣的实现,比如System.out.println也能保证能保证内存可见性?
System.out.println的形式
首先我们把setter修改flag之前添加耗时任务(仅66纳秒)TimeUnit.NANOSECONDS.sleep(66),即确保不触发刚才的猜想:
import java.util.concurrent.TimeUnit;
public class Visbility {
private boolean flag;
public void cyclic(){
while (!flag){
}
}
public void setter(){
try {
TimeUnit.NANOSECONDS.sleep(66);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = true;
}
}
执行结果和之前一样:多次执行Main函数,每次都不结束。
然后我们在cyclic死循环里添加一行输出语句:System.out.println,不加volatile关键字修饰flag,此时Visibility.java如下:
import java.util.concurrent.TimeUnit;
public class Visbility {
private boolean flag;
public void cyclic(){
while (!flag){
System.out.println(flag);
}
}
public void setter(){
try {
TimeUnit.NANOSECONDS.sleep(66);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = true;
}
}
多次执行Main函数的结果:都是输出了几十个false后程序终止。
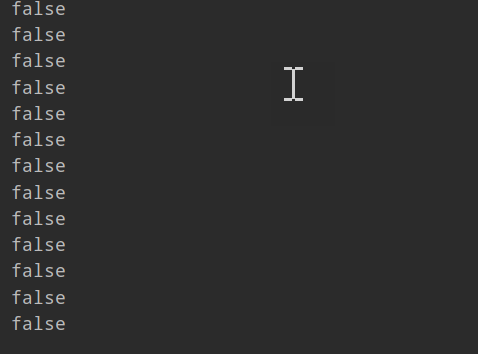
什么情况,这里没有用volatile修饰flag啊,也没用锁啊;
真的没用锁吗?println源码如下:
public void println(boolean x) {
synchronized (this) {
print(x);
newLine();
}
}
原来是锁住了this对象,即out属性的实例,所以我们在这个场景里用锁的形式保证变量内存及时可见甚至可以是下面这样:
import java.util.concurrent.TimeUnit;
public class Visbility {
private boolean flag;
public void cyclic(){
while (!flag){
System.out.println();
}
}
public void setter(){
try {
TimeUnit.NANOSECONDS.sleep(66);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = true;
}
}
甚至还可以这样:
public class Visbility {
private boolean flag;
public void cyclic(){
while (!flag){
synchronized ("123"){
}
}
}
public void setter(){
try {
TimeUnit.NANOSECONDS.sleep(66);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = true;
}
}
但是不能这样:
public class Visbility {
private boolean flag;
public void cyclic(){
synchronized ("123"){
}
while (!flag){
}
}
public void setter(){
try {
TimeUnit.NANOSECONDS.sleep(66);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = true;
}
}
正常用锁的方式
还是写点正常点的代码吧。。。也是最基础的例子
public class Visbility {
private boolean flag;
public void cyclic(){
while (!isFlag()){
}
}
public void setter(){
try {
TimeUnit.NANOSECONDS.sleep(66);
} catch (InterruptedException e) {
e.printStackTrace();
}
setFlag(true);
}
public synchronized boolean isFlag() {
return flag;
}
public synchronized void setFlag(boolean flag) {
this.flag = flag;
}
}
在这个场景中,用 锁的方式 大同小异,不管是用wait-notifyAll,还是lock*,await-signallAll,亦或是,countdown,await,take,put等方法 ,都是在用锁而已。
对DCL单例模式的思考
在DCL单例中,既然锁synchronized能保证 原子性 和 可见性 ,那volatile的作用是什么呢?volatile起的作用是 禁止指令重排序 和 可见性 。
public class DoubleCheckedLocking {
private volatile static DoubleCheckedLocking dcl = null;
private DoubleCheckedLocking() {
}
public static DoubleCheckedLocking getInstance() {
if (dcl == null) {
synchronized (DoubleCheckedLocking.class) {
if (dcl == null) {
dcl = new DoubleCheckedLocking();
}
}
}
return dcl;
}
}
对于"dcl = new DoubleCheckedLocking();"这行代码,首先DoubleCheckedLocking.java被编译成字节码,然后被 类加载器加载 ,接着还有下面3步骤:
memory = allocate(); // 1.分配内存空间
init(memory); // 2.将对象初始化
dcl = memory;// 3.设置dcl指向刚分配的内存地址, 此时dcl != null
step2和step3在单线程环境下允许指令重排,即先把未初始化的内存地址指向dcl( 此时dcl!=null ),然后才把内存空间初始化;
但是如果在多线程的环境下,JVM优化 指令重排 后执行顺序如果是 step1->step3->step2 ,A线程执行到step3此时 还未执行step2 对象还未初始化,但是此时dcl已经被赋值为memory,所以dcl!=null,同时另一个线程B执行最外层代码块if(dcl==null结果为false),就直接return 未 被初始化的错误的 dcl 。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

