什么?知乎又挂了?我们来聊聊微服务的高可用如何保障
故事
今天中午知乎又一次宕机,访问返回502错误,如下图所示:

高可用标准
那服务既然挂了,我们来聊聊如何在微服务中如何保障他能够不挂呢?首先我们来看看业界的高可用标准,一般常见的概括如下:
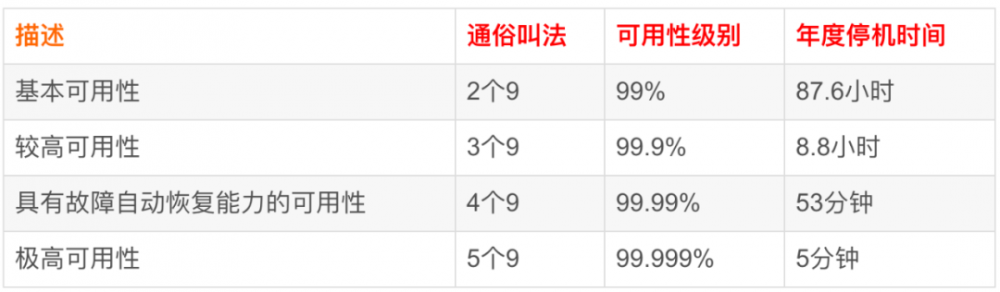
5个9的SLA在一年内只能是5分钟的不可用时间,5分钟啊,如果按一年只出1次故障,你也得在五分钟内恢复故障,感觉还是有点厉害。
什么是高可用?
那我们在做高可用之前,先通过维基百科了解一下到底什么是真正的高可用呢?
系统无中断地执行其功能的能力,代表系统的可用性程度,是进行系统设计时的准则之一。
这个难点或是重点在于“无中断”,要做到 7 x 24 小时无中断无异常的服务提供。
为什么需要高可用?
一套对外提供服务的系统是需要硬件,软件相结合,但是我们的硬件总是会出故障,软件会有 Bug,硬件会慢慢老化,网络总是不稳定,软件会越来越复杂和庞大。
除了硬件软件在本质上无法做到“无中断”,外部环境也可能导致服务的中断,例如断电,地震,火灾,光纤被挖掘机挖断,这些影响的程度可能更大。
如何保障服务的高可用?
高可用是一个比较复杂的命题,基本上在所有的处理中都会涉及到高可用,所有在设计高可用方案也涉及到了方方面面。这中间将会出现的细节是多种多样的,所以我们需要对这样一个微服务高可用方案进行一个顶层的设计,围绕服务高可用,先检查下我们手里有多少张牌。一般的策略主要有:服务冗余、无状态化、数据存储高可用、柔性化、兜底容错、负载均衡、服务限流、服务监控等。
服务冗余
每一个访问可能都会有多个服务组成而成,每个机器每个服务都可能出现问题,所以第一个考虑到的就是每个服务必须不止一份可以是多份,所谓多份一致的服务就是服务的冗余,这里说的服务泛指了机器的服务,容器的服务,还有微服务本身的服务。
在机器服务层面需要考虑,各个机器间的冗余是否有在物理空间进行隔离冗余,例如是否所有机器是否有分别部署在不同机房,如果在同一个机房是否做到了部署在不同的机柜,如果是docker容器是否部署在分别不同的物理机上面。采取的策略其实也还是根据服务的业务而定,所以需要对服务进行分级评分,从而采取不同的策略,不同的策略安全程度不同,伴随这的成本也是不同,安全等级更高的服务可能还不止考虑不同机房,还需要把各个机房所处的区域考虑进行,例如,两个机房不要处在同一个地震带上等等。
无状态化
服务的冗余会要求我们可以随时对服务进行扩容或者缩容,有可能我们会从2台机器变成3台机器,想要对服务进行随时随地的扩缩容,就要求我们的服务是一个无状态化,所谓无状态化就是每个服务的服务内容和数据都是一致的。
例如,从我们的微服务架构来看,我们总共分水平划分了好几个层,正因为我们每个层都做到了无状态,所以在这个水平架构的扩张是非常的简单。
假设,我们需要对网关进行扩容,我们只需要增加服务就可以,而不需要去考虑网关是否存储了一个额外的数据。
服务存储高可用
分布式领域中有一个著名的CAP定理,从理论上论证了存储高可用的复杂度,也就是说,存储高可用不可能同时满足“一致性,可用性,分区容错性”,最多只能满足2个,其中分区容错在分布式中是必须的,就意味着,我们在做架构设计时必须结合业务对一致性和可用性进行取舍。
存储高可用方案的本质是将数据复制到多个存储设备中,通过数据冗余的方式来现实高可用,其复杂度主要呈现在数据复制的延迟或中断导致数据的不一致性,我们在设计存储架构时必须考虑到一下几个方面:
- 数据怎么进行复制
- 架构中每个节点的职责是什么
- 数据复制出现延迟怎么处理
- 当架构中节点出现错误怎么保证高可用
数据主从复制
主从复制是最常见的也是最简单的存储高可用方案,例如Mysql,redis等等。
其架构的优点就是简单,主机复制写和读,而从机只负责读操作,在读并发高时候可用扩张从库的数量减低压力,主机出现故障,读操作也可以保证读业务的顺利进行。
缺点就是客户端必须感知主从关系的存在,将不同的操作发送给不同的机器进行处理,而且主从复制中,从机器负责读操作,可能因为主从复制时延大,出现数据不一致性的问题。
数据主从切换
刚说了主从切换存在两个问题: 1.主机故障写操作无法进行 2.需要人工将其中一台从机器升级为主机
为了解决这个两个问题,我们可以设计一套主从自动切换的方案,其中设计到对主机的状态检测,切换的决策,数据丢失和冲突的问题。
数据分片
上述的数据冗余可以通过数据的复制来进行解决,但是数据的扩张需要通过数据的分片来进行解决(如果在关系型数据库是分表)。
何为数据分片(segment,fragment, shard, partition),就是按照一定的规则,将数据集划分成相互独立、正交的数据子集,然后将数据子集分布到不同的节点上。
HDFS , mongoDB 的sharding 模式也基本是基于这种分片的模式去实现,我们在设计分片主要考虑到的点是:
- 做数据分片,如何将数据映射到节点
- 数据分片的特征值,即按照数据中的哪一个属性(字段)来分片
- 数据分片的元数据的管理,如何保证元数据服务器的高性能、高可用,如果是一组服务器,如何保证强一致性
柔性化/异步化
在每一次调用,时间越长存在超时的风险就越大,逻辑越复杂执行的步骤越多存在失败的风险也就越大,如果在业务允许的情况下,用户调用只给用户必须要的结果,而不是需要同步的结果可以放在另外的地方异步去操作,这就减少了超时的风险也把复杂业务进行拆分减低复杂度。
当然异步化的好处是非常多,例如削封解耦等等,这里只是从可用的角度出发。
所谓的柔性化,就是在我们业务中允许的情况下,做不到给予用户百分百可用的通过降级的手段给到用户尽可能多的服务,而不是非得每次都交出去要么100分或0分的答卷。
怎么去做柔性化,更多其实是对业务的理解和判断,柔性化更多是一种思维,需要对业务场景有深入的了解。
在电商订单的场景中,下单,扣库存,支付是一定要执行的步骤,如果失败则订单失败,但是加积分,发货,售后是可以柔性处理,就算出错也可以通过日志报警让人工去检查,没必要为加积分损失整个下单的可用性。
兜底/容错
兜底是可能我们经常谈论的是一种降级的方案,方案是用来实施,但是这里兜底可能更多是一种思想,更多的是一种预案,每个操作都可以犯错,我们也可以接受犯错,但是每个犯错我们都必须有一个兜底的预案,这个兜底的预案其实就是我们的容错或者说最大程度避免更大伤害的措施,实际上也是一个不断降级的过程。
负载均衡
相信负载均衡这个话题基本已经深入每个做微服务开发或设计者的人心,负载均衡的实现有硬件和软件,硬件有F5,A10等机器,软件有LVS,nginx,HAProxy等等,负载均衡的算法有 random , RoundRobin , ConsistentHash等等。
服务限流降级熔断
先来讲讲微服务中限流/熔断的目的是什么,微服务后,系统分布式部署,系统之间通过rpc框架通信,整个系统发生故障的概率随着系统规模的增长而增长,一个小的故障经过链路的传递放大,有可能会造成更大的故障。
服务监控
服务监控是微服务治理的一个重要环节,监控系统的完善程度直接影响到我们微服务质量的好坏,我们的微服务在线上运行的时候有没有一套完善的监控体系能去了解到它的健康情况,对整个系统的可靠性和稳定性是非常重要,可靠性和稳定性是高可用的一个前提保证。
【注:文章部分内容参考 李云华《从0开始学架构》杨波老师《微服务》】关注“SpringForAll社区”公众号,2020让我们一起精进。
[]( https://tva1.sinaimg.cn/large...
本文由博客一文多发平台 OpenWrite 发布!
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

