Java实习生面试复习(六):MySQL索引
我是一名很普通的双非大三学生。接下来的几个月内,我将坚持写博客,输出知识的同时巩固自己的基础,记录自己的成长和锻炼自己,备战2021暑期实习面试!奥利给!!
作为一个后端程序员,那么数据库也是天天打交道的,回忆起以前写复杂SQL的时候还得请教别人,自己写的一手辣鸡SQL,简直不忍直视好嘛!看完这篇文章,至少让你对索引有个认识。
本文不会涉及那些很基础的增删改查语句,我相信这些你还是会的。 对于很多关键字的知识点可能只是简单提一下, 善用搜索引擎 ,一篇文章要想说清楚那么多,那太长了,很少有人能全部看完。
MySQL详细
SQL的执行过程
MySQL在接收到客户端传入的SQL语句后并不能马上对该SQL进行执行,是需要经过一系列复杂的流程,最终转变成二进制的机器码,才能被执行的,我们需要对执行的SQL进行优化,那么就有必须先来了解下,一个SQL语句的执行:
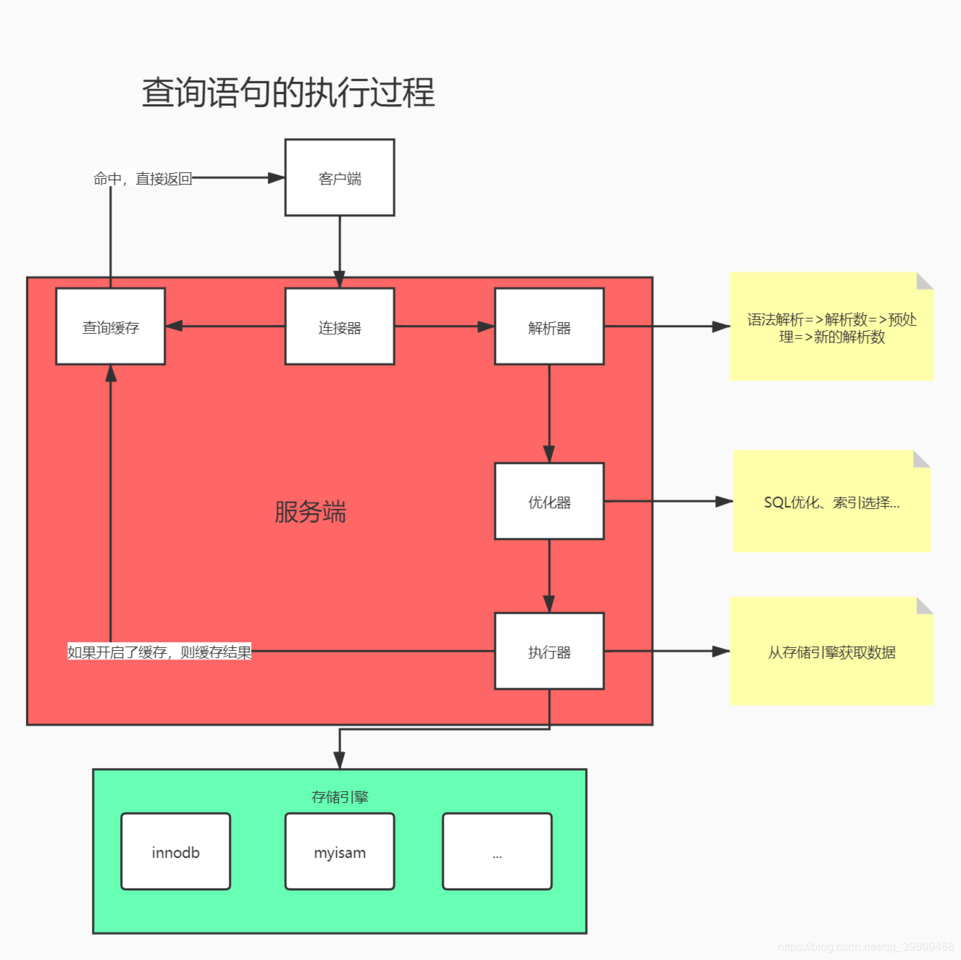
:
- 通过网络的通讯协议接收客户端传入的SQL
- 查看该SQL对应的结果在查询缓存中是否存在,存在则直接返回结果,不存在则继续往下走 ( ps:默认情况下是关闭的,mysql8.0以后移除了查询缓存功能 )
不建议使用查询缓存,因为查询缓存往往弊大于利,因为查询缓存的失效非常频繁,只要有对一个表的更新,这个表上的所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务有一张静态表,很长时间更新一次,比如系统配置表,那么这张表的查询才适合做查询缓存。
- 由解析器来解析当前SQL,最终形成初步的解析树
- 再由预处理器对解析树进行调整,完成占位符赋值等操作
- 查询优化器对最终的解析树进行优化,包括调整SQL顺序等
- 根据优化后的结果得出查询语句的执行计划,就是查询数据的具体实施方案,交给查询的执行引擎
- 查询执行引擎调用存储引擎提供的API,最后由存储引擎来完成数据的查询,然后返回结果
看完以为,你有没有发现,我们写代码时能做的只有对写SQL尽可能的做出优化,执行效率更高,有效的使用索引,因为其他的地方你都没办法去插手。
顺带提一句SQL的执行顺序
写SQL顺序: select...from...join...on...where...group by...having...order by...limit...
解析SQL时的顺序: from...on...join...where...group by...having...select...order by...limit...
数据库索引
索引是数据库系统里面最重要的概念之一,那么了解它是必须的,我们先看看概念性的东西。一句话简单来说,索引其实就是为了提高数据查询的效率,通俗来说可以理解为是字典的目录一样,可以通过目录快速的查找到对应的页码,但没有目录的情况下,那我估计你可得找一会儿。同样,对于数据库的表而言,索引其实就是它的“目录”。 B+树 的结构:
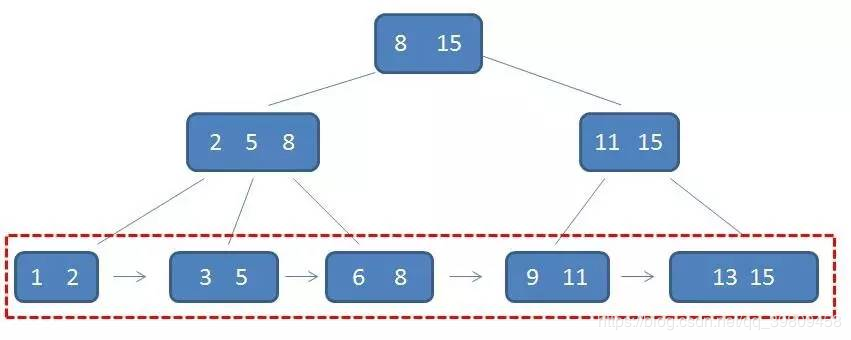
?(ps:这种类似的面试题还是很常见的吧)
- 为什么不用Hash,因为Hash虽然查找快,但是有局限性,无法应对范围和排序条件的查询情况
- 为什么不用二叉查找树,因为二叉查找树在特定的情况下,会出现链式的情况无法保证平衡,导致树的深度过深,增加磁盘IO次数。
- 为什么不用平衡二叉树,因为AVL树虽然解决了二叉查找树平衡的情况,但是在数据量大的情况下还是会出现深度过深的情况,在空间利用上还是有很大的问题。
- 为什么不用B树,因为B树虽然也解决了平衡以及深度的问题,将瘦高的树变成了矮胖的树, 由于B树在非叶子节点中也存在指针,占用了空间,导致叶子节点中的数据变少,所以这还不算最优的方法。
- 使用B+树,B+树在B树的基础上区分了叶子节点和非叶子节点,叶子节点只存放数据,非叶子节点只存放索引和子节点引用,不存放数据,我们知道磁盘读写是以磁盘块block为单位的,在innodb中也有页的概念,所以这样每次读的时候可以读取更多的索引到内存中,而且B+树的子节点叶是按顺序放置的双向链表所以b+树的IO效率稳定,且排序范围查找这些效率更高。
总结来说:B+树能够很好地配合磁盘的读写特性,减少单次查询的磁盘访问次数。
肯定又有小伙伴疑惑了,为什么磁盘IO慢?因为 磁盘IO时间 = 寻道 + 磁盘旋转 + 数据传输时间
索引类型
一个表是可以有多个不同的索引,阿里巴巴开发手册中有写到命名规范:“ 主键索引名为 pk-字段名;唯一索引名为 uk-字段名;普通索引名则为 idx-字段名 ”
- 主键索引 只在建立主键约束时自动添加,特点:非空且唯一
- 普通索引 单独对表中的某个列数据建立索引
- 唯一索引 在该索引中没有重复的数据,都是唯一的
- 复合索引 多个列的值组成的索引,当第一个列的值重复时,按照后面的组合继续查找数据。复合索引相当于字典的二级目录,当前一个值一致时,再使用后一个值做筛选
既然说到索引,那什么时候用普通索引什么时候用唯一索引呢?阿里巴巴开发手册中这样写到:业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。 说明:不要以为 唯一索引影响了 insert 速度 ,这个速度损耗可以忽略,但提高查找速度是明显的;另外, 即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。
学东西肯定得深究一下,为什么会影响了insert的速度?为了说明普通索引和唯一索引对更新语句性能的影响这个问题,你首先要知道change buffer。
当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下,InooDB会将这些更新操作缓存在change buffer中,这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行change buffer中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
对于唯一索引来说,所有的更新操作都要先判断这个操作是否违反唯一性约束。比如,要插入(4,400)这个记录,就要先判断现在表中是否已经存在4的记录,而这必须要将数据页读入内存才能判断。如果都已经读入到内存了,那直接更新内存会更快,就没必要使用change buffer了。因此,唯一索引的更新就不能使用change buffer,实际上也只有普通索引可以使用。
总结:如果这个记录要更新的目标页不在内存中。这时,InnoDB的处理流程如下:
- 对于唯一索引来说,需要将数据页读入内存,判断到没有冲突,插入这个值,语句执行结束;
- 对于普通索引来说,则是将更新记录在change buffer,语句执行就结束了。 将数据从磁盘读入内存涉及随机IO的访问,是数据库里面成本最高的操作之一。change buffer因为减少了随机磁盘访问,所以对更新性能的提升是会很明显的。
Explain命令
Explain命令在解决数据库性能上是第一推荐使用命令,大部分的性能问题可以通过此命令来简单的解决,Explain可以用来查看SQL语句的执行效 果,可以帮助选择更好的索引和优化查询语句,写出更好的优化语句。 执行截图如下:

下面对各个属性进行了解:
- id:这是SELECT的查询序列号,越大越先执行
- select_type:select_type就是select的类型,可以有以下几种:
SIMPLE:简单SELECT(不使用UNION或子查询等) PRIMARY:最外面的SELECT UNION:UNION中的第二个或后面的SELECT语句 DEPENDENT UNION:UNION中的第二个或后面的SELECT语句,取决于外面的查询 UNION RESULT:UNION的结果。 SUBQUERY:子查询中的第一个SELECT DEPENDENT SUBQUERY:子查询中的第一个SELECT,取决于外面的查询 DERIVED:导出表的SELECT(FROM子句的子查询)
-
table:显示这一行的数据是关于哪张表的
-
type:这列最重要,显示了连接使用了哪种类别,有无使用索引,是使用Explain命令分析性能瓶颈的关键项之一。
常见的几种按照执行性能排列为:systme > const > eq_ref > ref > range > index > all
const: 根据主键索引或者唯一索引查询到的结果
- explain select id,name from employee where id = 1;
ref: 指的是使用普通的索引(normal index)做查询,常见于多表查询中
- explain select * from department d join employee e on d.id = e.dept_id;
range: 索引做范围查询,常见于<、<=、>、>=、between等操作符
- explain select age from employee where age >= 20 and age <= 30
index: 索引全查询,MySQL遍历整个索引来查找匹配的行。
- explain select age from employee where age >= 20
注意:该值没有优化的情况下一般都是all,阿里巴巴开发手册中有提到 “SQL性能优化的目标:至少要达到 range 级别,要求是 ref级别,如果可以是 consts最好”。
-
possible_keys: 对某表进行单表查询时可能用到的索引
-
key:经过查询优化器计算不同索引的成本,最终选择成本最低的索引 ,显示实际决定使用的索引。如果没有选择索引,键是NULL
-
key_len:显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。使用的索引的长度。在不损失精确性的情况下,长度越短越好
-
ref:显示使用哪个列或常数与key一起从表中选择行。
-
rows:如果使用全表扫描,那么rows就代表需要扫描的行数,如果使用索引,那么rows就代表预计扫描的行数
-
Extra:包含MySQL解决查询的详细信息,也是关键参考项之一。
Using index:查询的列被索引覆盖,并且where筛选条件是索引的前导列,是性能高的表现。一般是使用了覆盖索引(索引包含了所有查询的字段)。对于innodb来说,如果是辅助索引性能会有不少提高
Using where:查询的列未被索引覆盖,where筛选条件非索引的前导列
Using where Using index:查询的列被索引覆盖,并且where筛选条件是索引列之一但是不是索引的前导列,意味着无法直接通过索引查找来查询到符合条件的数据
NULL:查询的列未被索引覆盖,并且where筛选条件是索引的前导列,意味着用到了索引,但是部分字段未被索引覆盖,必须通过“回表”来实现,不是纯粹地用到了索引,也不是完全没用到索引
Using index condition:与Using where类似,查询的列不完全被索引覆盖,where条件中是一个前导列的范围;
Using temporary:mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化。
Using filesort:mysql 会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。此时mysql会根据联接类型浏览所有符合条件的记录,并保存排序关键字和行指针,然后排序关键字并按顺序检索行信息。这种情况下一般也是要考虑使用索引来优化的。
创建索引时避免有如下极端误解:
- 宁滥勿缺。认为一个查询就需要建一个索引。
- 宁缺勿滥。认为索引会消耗空间、严重拖慢记录的更新以及行的新增速度。
- 抵制唯一索引。认为业务的唯一性一律需要在应用层通过“先查后插”方式解决。
建立索引的原则:
- 较频繁的作为查询条件的字段应该创建索引,如:登录操作。
- 唯一性太差的字段不适合单独创建索引;如:性别,状态不多的状态列)。
- 更新非常频繁的字段不适合创建索引,原因:索引有维护成本 。
- 索引不是越多越好(ps:只为必要的列创建索引)。
索引失效常见的几种情况:
- where语句中索引列参与算术计算,该索引失效
- where语句中索引列参与函数运算,该索引失效
- where语句中使用in运算符有时会让索引失效
- where语句中做不等于( != , <> )运行,该索引失效
- where语句中发生类型转发,该索引失效
- where语句中模糊查询时以%开头,该索引失效
- 在复合索引的使用时跟声明时顺序不一致或者中间有列的缺失,该索引失效
如:声明了(a,b,c)的复合索引,但是在用是时候中间有列的缺失where a = xx and c = xx中间缺失了b,所以无法使用该复合索引,只要不是缺失中间列,其他情况索引均有效
最左前缀匹配原则,是一个非常重要的原则,可以通过以下这几个特性来理解:
- 对于联合索引,MySQL 会一直向右匹配直到遇到范围查询(> , < ,between,like)就停止匹配。比如 a = 3 and b = 4 and c > 5 and d = 6,如果建立的是(a,b,c,d)这种顺序的索引,那么 d 是用不到索引的,但是如果建立的是 (a,b,d,c)这种顺序的索引的话,那么就没问题,而且 a,b,d 的顺序可以随意调换。
- = 和 in 可以乱序,比如 a = 3 and b = 4 and c = 5 建立 (a,b,c)索引可以任意顺序。
- 如果建立的索引顺序是 (a,b)那么直接采用 where b = 5 这种查询条件是无法利用到索引的,这一条最能体现最左匹配的特性。
覆盖索引
如果执行的语句是 select id from student where class between 1 and 3 ,这时只需要查ID的值,而ID的值已经在k索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引k已经“覆盖了”我们的查询需求,我们称为覆盖索引。 执行流程:
- 在k索引树上找到 class = 1的记录,取得 id;
- 再到主键id 索引树查到 id 对应的数据;
- 在k索引树取下一个值class = 3,取得ID;
- 再回到主键id 索引树查到 id 对应的数据;
- 在k索引树取下一个值 class = 4,不满足条件,循环结束。
在这个过程中, 回到主键索引树搜索的过程,我们称为回表 。可以看到,这个查询过程读了k索引树的3条记录(步骤1、3和5),回表了两次(步骤2和4)。在这个例子中,由于查询结果所需要的数据只在主键索引上有,所以不得不回表。那么,有没有可能经过索引优化,避免回表过程呢?这个时候,我们可以用覆盖索引来减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
索引下推
索引下推优化(index condition pushdown), 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
假设一个表包含有关人员及其地址的信息,并且该表的索引定义为INDEX(zipcode,lastname,firstname)。如果我们知道一个人的邮政编码值但不确定姓氏,我们可以这样搜索:
SELECT * FROM people WHERE zipcode='95054' AND lastname LIKE '%etrunia%' AND address LIKE '%Main Street%';
MySQL可以使用索引来扫描zipcode='95054'的人。第二部分(姓氏LIKE'%etrunia%')不能用于限制必须扫描的行数,因此如果没有 索引下推 优化,此查询必须为所有拥有zipcode ='95054'的人检索完整的表行。
使用 索引下推 后,MySQL在读取整个表行之前检查姓氏LIKE '%etrunia%' 部分。这样可以避免读取与zipcode条件匹配的索引元组对应的完整行,但不会读取lastname条件。
延迟关联
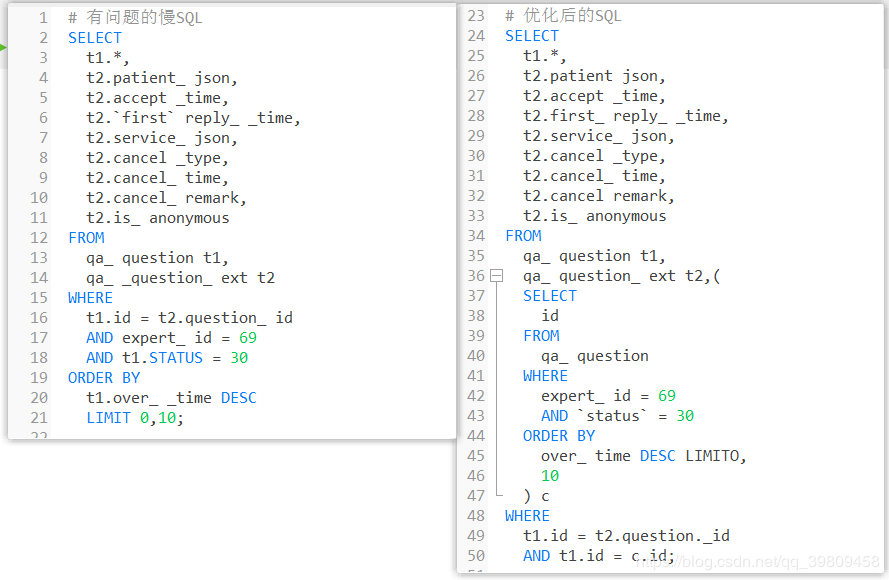
SELECT id FROM qa_question WHERE expert_id = 69 AND STATUS = 30 ORDER BY over_time DESC LIMIT 0, 10 , 这里其实利用了索引覆盖,where条件后的expert_id 是有添加索引的,这里查询id 可以避免回表,大大提升效率。这种也叫
延迟关联
。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

