.Net微服务实战之技术选型篇
王者荣耀
去年我有幸被老领导邀请以系统架构师的岗位带技术团队,并对公司项目以微服务进行了实施。无论是技术团队还是技术架构都是由我亲自的从0到1的选型与招聘成型的,此过程让我受益良多,因此也希望在接下来的系列博文尽可能的与大家分享我的经验。
古人有云:将军难打无兵之仗。想要把微服务很好的实施也并非能一个人可以完成的事,一来需要有出色的运维提供支持,二来需要花时间做技术选型与攻关,三来还要开发兄弟们配合实施。因此,这次能顺利实施并不是一个人的王者,而是团队的荣耀。
框架源码:https://github.com/SkyChenSky/Sikiro (文末有说明)
工欲善其事,必先利其器
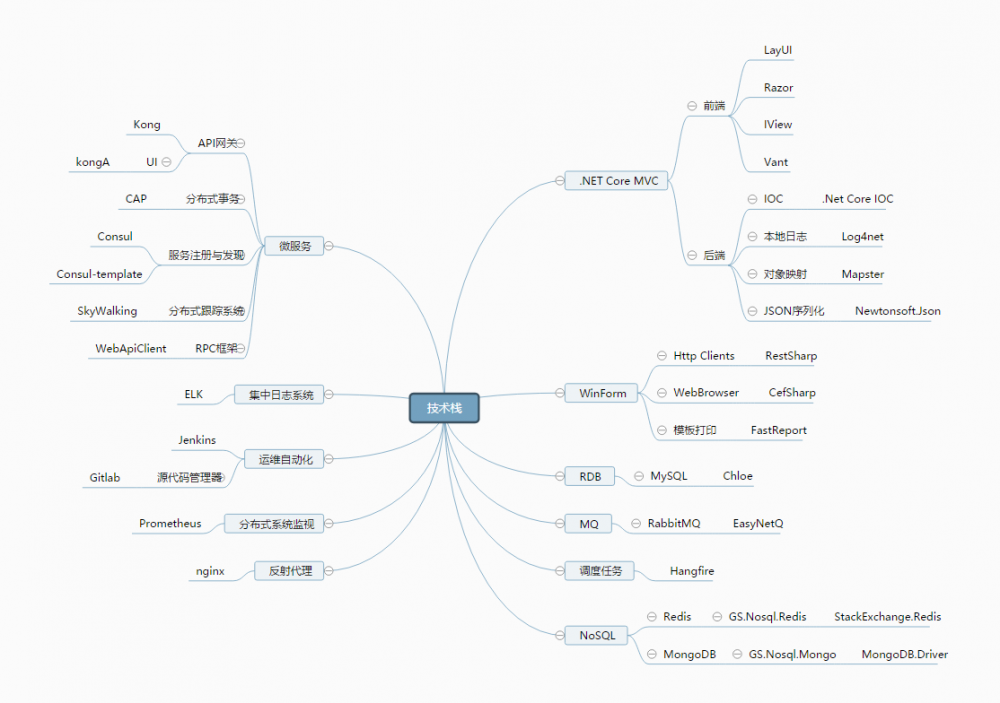
以上是我们公司的技术栈(点击图片可在浏览器打开),除了统一配置中心没有服务器资源和Hangfire还没场景使用外,其他都已经上线使用了。
俗话说得好: 工欲善其事,必先利其器 。一个优秀的工程师应该善于使用框架和工具,在微服务这一块的技术栈选型并非一蹴而就,也是我多次对比验证后,并良好的集成到公司项目然后落地实施。这系列框架单纯这么去用其实是可以无缝集成的,但是在落实项目的时候,我为了集成得更加友好和使用上更加便利,在基础上做了扩展,例如SkyWalking添加Request和Response,CAP与Chloe.ORM的集成等,下文我会逐个分享。
有需要的朋友可以参照我这套去实施,这样大家就可以花更多的时间把精力放在业务、调优、拆分、设计等方面。
此外大家看得出,我所有的技术栈基本上找的都是开源社区的比较出名的项目,没有一个属于自研的。这样做的原因:
- 快速搭建
- 降低成本
- 社区支持维护
- 利于人才引进
其实可以看出.Net不缺优秀的开源项目,那么实施这么久让我唯一觉得深刻的印象是: 缺少整合。
之前我也跟不少同行讨论过甚至在面试的时候,他们觉得应该自己造一个轮子,原因各种各样,但唯独缺少了 希望在开源项目基础上完善下 这个原因。我也理解他们的心理,因为“优秀”的工程师应该自己写一套证明下自己。其实我认为这也许是 包容心 的在作祟,我们应当 求同存异 ,学会接受已经检验过的轮子,在基础上完善您的需要,有必要还可以给社区做贡献,双赢。
原则
我做技术选型的时候,坚持着三大原则, 简单、适合、运维优先 。
在满足需求的情况下,优先选择轻量级的框架,因为轻量级总比重量级的易学习,易于扩展,易于理解源码。试想一下,有个框架什么都很齐全,但是学习曲线高,在写一个demo的时候各种踩“坑”找原因,还有可能出了问题不知道怎么解决,除了开始你初认识该框架觉得他很厉害之外,后面使用每走一步都是阻碍和吐槽。
在有限的资源、人力、时间,我们更新技术的同时还要保证业务的正常开展,我会优先选择我比较熟悉的技术,我会将他们进行封装、优化、集成,尽可能的 减少开发人员对技术细节的认知负担, 尽可能以他们最熟悉的使用方式提供。此外,我们团队是有运维岗,如果问题由运维解决更快、更方便则优先交给运维,尽可能让开发关注数据流转与业务流程。
PS:我选型的时候不是一蹴而就的,下文可能我会提到某些框架工具我没有去选择原因,并不是否认它们存在的价值,而绝大问题是这些不适用于我们团队。最后我向伟大的开源项目与其作者致敬。
微服务
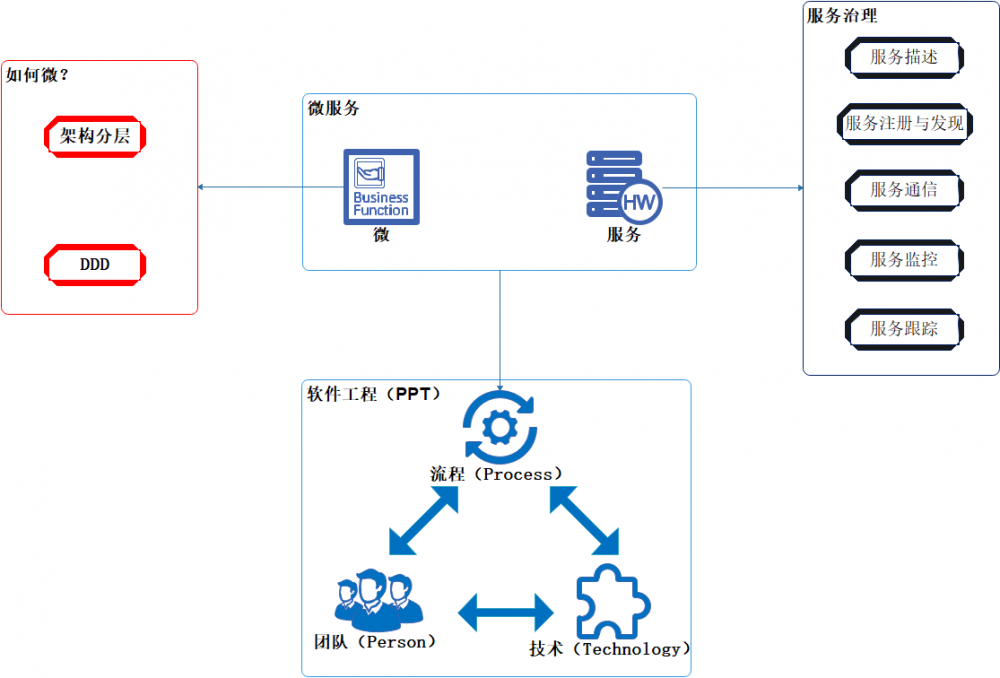
有一条盛传于我们行业的公式: 软件 = 程序 + 软件工程 。
程序就是我们经常产出的算法、数据结构、脚本、框架、架构等。
为什么称之为软件工程?因为这是具有科学方法论引导的、多人协作、有明确目标、有阶段性的。从以前瀑布开发再到10年前盛行的敏捷开发最后到最近几年流行的DevOps,可见开发模式也随着技术架构更新也不停的演进。我们团队选用了原型模式+DevOps模式来应对我们的微服务架构的开发。
书本的教条主义我就不多说了,我对微服务的理解分为 微 和 服务 。
微
如何微?微到什么程度?我借助两样东西,合理的 系统架构分层 与 DDD思想 ,两者分别管理架构的纵向拆分与横向拆分。
架构分层,我采用了前后端分离+多层架构,自顶向下的依赖,各司其职。
DDD在最近几年非常流行,然而这并非新的技术,十几年前就已经它的出现了。随着微服务盛行,DDD的划分域的 化繁为简 的思想与微服务的本质- 拆 不谋而合,因此DDD也随之热门起来。
下面是我们的架构图,这个话题在下一篇重点再讨论。
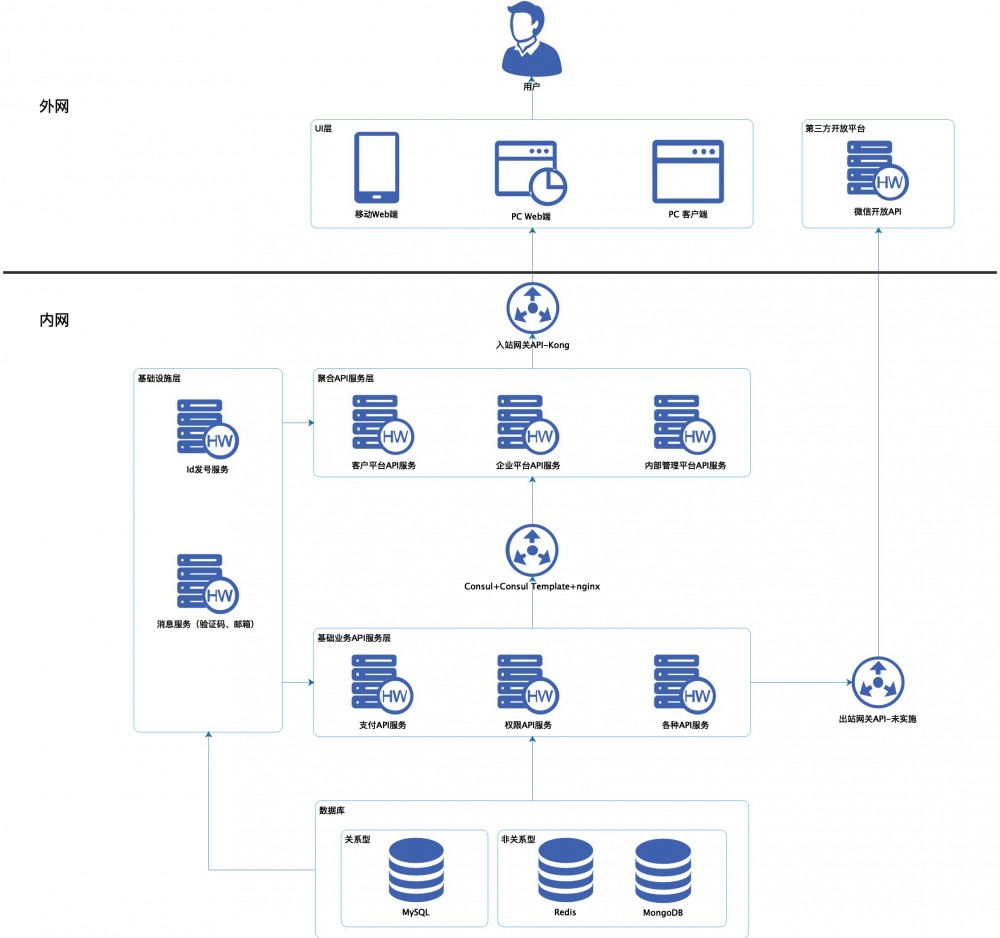
服务治理
我接下来用一段话描述一下服务化的需要。首先 API网关 作为我们请求流量的入口,隔离了外网与内网的作用。接着开发人员得知道如何调用服务,那么可以从 注册中心 发现已注册的服务的IP地址、端口的列表,这就是 服务的注册与发现; 接着我们需要知道服务下接口路径、请求与响应的格式,因此我们需要 服务描述。 满足前面两个条件后,我们就可以进行调用服务了,因此我们需要 RPC框架 进行 服务通信 。当服务运作后,我们需要 服务监控 来监控服务的运行情况以此方便调优。随着服务拆分得越细、跨度越大,服务出问题的时候不容易定位,因此我们需要 服务跟踪 进行问题定位。
由上述可见组件主要包括以下6点:
- API网关
- 服务描述
- 服务注册中心
- RPC框架
- 服务监控
- 分布式链路跟踪
API网关
API网关主要起到了隔离内外网、身份验证、路由、限流等作用。我用一个生活的例子搭地铁比喻来描述下:过闸前我们需要经过安检保证客流的 安全性, 上下班高峰期还会排队进行 限流, 我们还可以通过看指示牌或者询问工作人员了解到应该往什么方向走,这就是 路由。
我们团队选型了Kong和KongA作为我们的API网关,Kong是一个在Nginx运行的Lua应用程序,由lua-nginx-module实现。Kong和OpenResty一起打包发行,其中已经包含了lua-nginx-module。基本功能有路由、负载均衡、基本认证、限流、跨域、日志等功能,其他功能例如jwt认证可以通过插件进行扩展。
有人会问为什么不用Ocelot?回答这个问题之前,我首先声明我尊敬Ocelot项目与其开发者。
1.易用性。需要二次开发,虽然对.Net开发者来说能接受,但不利于运维。
2.性能。社区很多测试数据,据我了解就是kong 11K,Ocelot 3.5K,四舍五入3倍性能差,作为流量的入口,性能这块我还是比较注重的。
3.可扩展性,Kong很多功能可以通过插件式按需使用与开发。
服务描述
我们团队采用了Swagger,以此来衔接前后端开发的接口对接,省去了编写接口文档的成本,此外也支持接口调试,让开发效率提高不少。我们的服务都是以HTTP协议提供,对外API用RESTful风格,对内统一以POST的RPC风格提供。
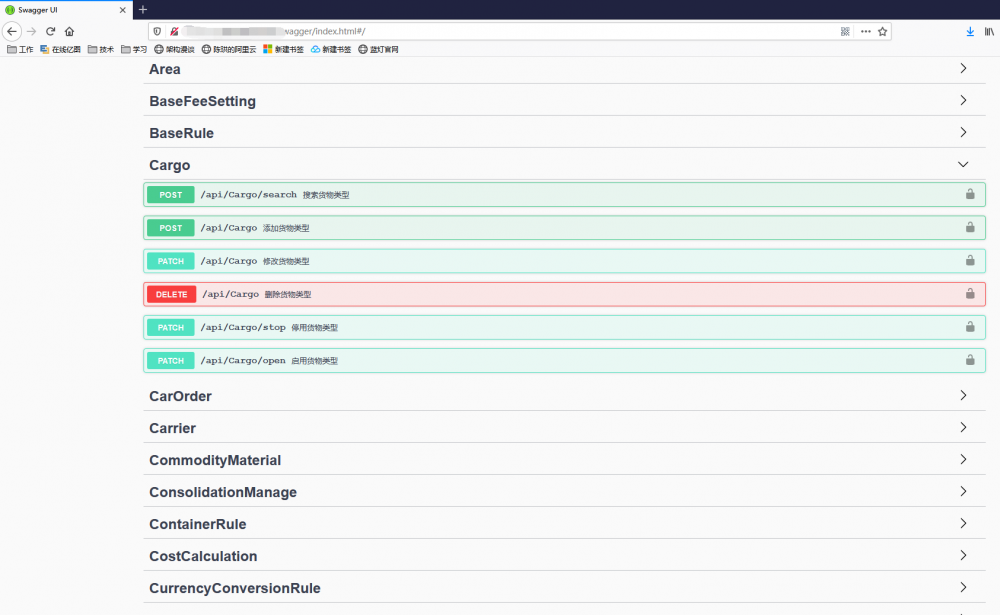
服务注册中心
服务注册,服务在发布后自动把 IP地址与端口 注册进 服务中心; 服务发现,通过调用服务中心的接口获取到某服务 IP地址与端口的 列表。我们团队选用Consul+Consul Tamplate+nginx,Consul是基于GO语言开发的开源工具,主要面向分布式,服务化的系统提供服务注册、服务发现和配置管理的功能。Consul的核心功能包括:服务注册/发现、健康检查、Key/Value存储、多数据中心和分布式一致性保证等特性。
Consul作为服务注册中心的存在,但是我们服务发现只能拿到IP列表,我们使用RPC调用时还是得做负载均衡算法,于是使用了Consul Tamplate把服务列表同步到nginx的配置,那么RPC框架就无需集成负载均衡算法经过nginx路由。
开始选型我并没有选择Consul Tamplate,而是选择了fabio的这个中间件。fabio是一个应用于Consul的轻量级、零配置负载均衡路由器,开始用的时候部署起来很方便、很简单。后来上了Skywalking分布式链路跟踪系统,只要经过fabio路由的都无法把调用链串起来,虽然将就的用是没什么问题,但是Skywalking的调用链日志无法很好的展示出来就会影响日后的问题排查。我当时花了两天时间研究与issue提问,并没有很好的结果,所以最后另外选择了Consul Tamplate+nginx。
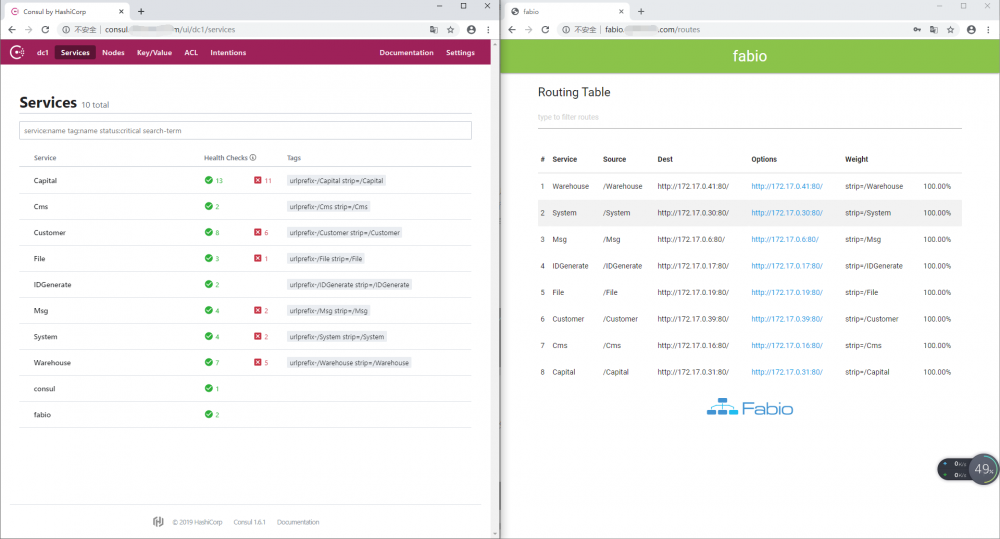
服务通信
RPC框架主要三大核心,序列化、通信细节隐藏、代理。协议支持分TCP和HTTP,当然还有两者兼容+集成MQ的。我们选择了WebApiClient做客户端,服务端仍是.Net Core WebAPI,主要考虑到WebAPIClient的轻量、易用,而且和Skywalking、Consul集成方便。我当时用的时候时.Net Core 2.2版本,gRPC并没有集成进来。
此外我也选择过ServiceStack,ServiceStack的技术栈很全,缺点是依赖得很深,当时试用的时候,它所以依赖的一个底层包ServiceStack.Common的某个类与WebAPI冲突了,所以对于不熟悉该框架的我断定存在依赖污染,无论我需要还是不需要都统统依赖进来了,然而我只是希望要一个简单的RPC框架。此外还需要破解。
Surging也作为我当时选型的目标,开始也是我抱着最大希望的,因为描述得很牛逼,什么都是全得。然而深入去用的时候,没有一个完整的文档,入门demo也不友好,说实话我驾驭不住只能放弃。
服务跟踪
市面上的分布式链路跟踪系统基本上都是根据谷歌的dapper论文实现的,基本上都分三大块,UI、收集器、代理(探针),原理大概是把涉及的服务链路的RequestID串起来。
我们团队选择了SkyWalking作为了项目的分布式链路跟踪系统,原因很简单:易用,无侵入,集成良好。
实施到我们项目的时候我做了点扩展,把Reqeust、Response、Header、异常给记录了下来,并过滤了部分不需要记录的路径。
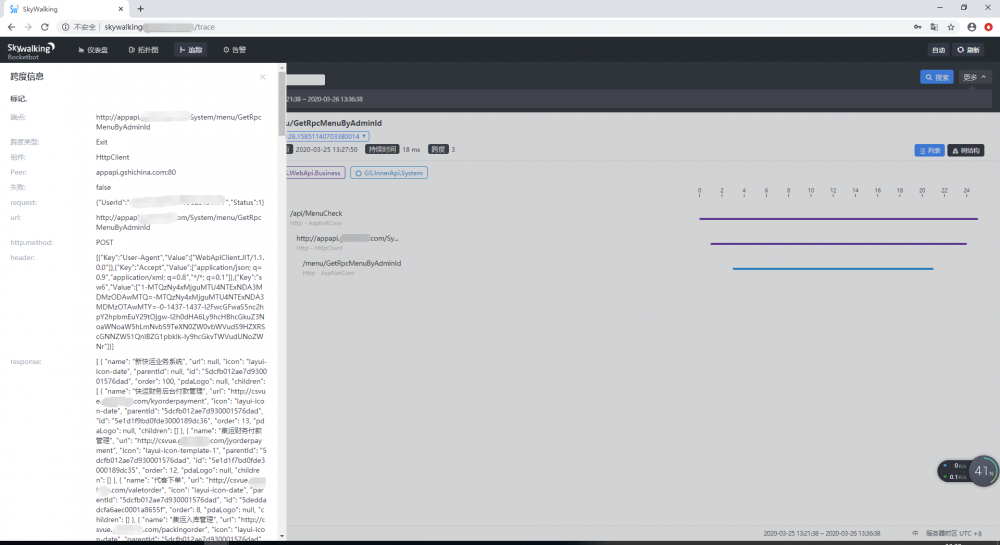
分布式事务
只要在分布式系统,分布式事务必不可缺。
| 分类 | 理论 | 案例 | 中间件 |
| 强一致性 | ACID | 二阶段提交 | msdtc |
| 最终一致性 | BASE | 本地消息表 | CAP |
本地消息表是eBay在N年前提出的方案,而CAP以该思想实现的一门框架,原理大概是,本地业务表与消息凭据表作为一个事务持久化,通过各种补偿手段保证MQ消息的可靠性,包括MQ正常发布与消费。
我花了多天的时间专门测试了该框架可靠性,的确有保证。然而有个地方我认为可以优化,Retry的查询语句条件可以更加严谨点,只需要负责相应的Group进行Retry就好,没必要全部都查询出来,因为这个问题我在测试环境与本地环境共同调试时,刚好两个环境的Group不一致,导致会Retry失败的问题。
框架源码
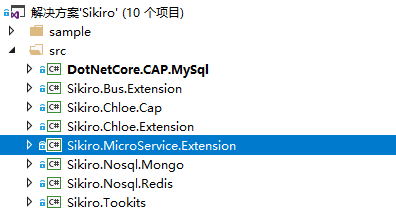
写到这里,本篇的分享差不多要结束了,我将开源我们公司的工具库,有需要的朋友可以去使用。
- Sikiro.Tookits -公共基础库
- Sikiro.Nosql.Redis-StackExchange.Redis的基本封装
- Sikiro.Nosql.Mongo-mongodb驱动封装更新、排序等支持lambda
- Sikiro.MicroService.Extension-RPC注册,微服务框架-服务注册,终端跟踪忽略
- Sikiro.Chloe.Extension-支持多数据、事务封装、分页、IOC
- Sikiro.Chloe.Cap-把Chloe,ORM与CAP整合
额外说明下DotNetCore.CAP.MySql,这个是我从CAP源码拷贝过来然后改了MySql.Data的依赖,原本CAP.MySql是用的MySqlConnector,和我的Chloe.ORM冲突了。
正文到此结束
- 本文标签: 认证 UI RESTful HTML 插件 OpenResty ioc id 配置中心 测试环境 云 源码 负载均衡 系统架构 管理 App 敏捷 同步 Service 服务端 Lua BIO mysql 测试 https 配置 领导 CTO 谷歌 Go语言 希望 mongo 架构师 git NOSQL 开源项目 TCP value 开源 招聘 MQ 本质 回答 部署 协议 ip sql redis 时间 key 开发 http HTTP协议 工程师 提问 微服务 服务器 db 安全 数据 需求 ebay 分页 core IO 一致性 consul retry Nginx 端口 人才 调试 GitHub 分布式事务 REST src 图片 分布式系统 服务注册 lambda 探针 tab 地铁 开发者 API MongoDB 软件 client ORM 分布式 注册中心 限流 web
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

