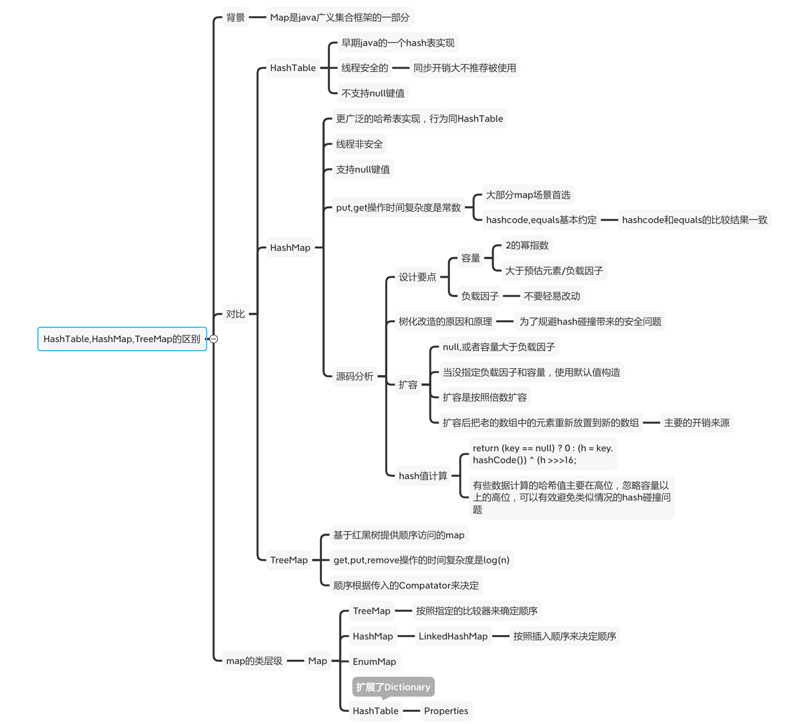
面试刷题9:HashTable HashMap TreeMap的区别?

map是广义集合的一部分。
我是李福春,我在准备面试,今天我们来回答:
HashTable,HashMap,TreeMap的区别?
共同点:都是Map的子类或者间接子类,以键值对的形式存储和操作数据。
区别如下表:
| 项目 | 线程安全 | 是否支持null键值 | 使用场景 |
|---|---|---|---|
| HashTable | 是 | 不支持 | java早期hash实现,同步开销大不推荐被使用 |
| HashMap | 否 | 支持 | 大部分场景的首选put,get时间复杂度是常数级别 |
| TreeMap | 否 | 不支持 | 基于红黑树提供顺序访问的map,传入比较器来决定顺序,get,put,remove操作时间复杂度log(n) |
下面分析一下面试官可能根据上面的问题进行一些扩展的点。
Map的类层级
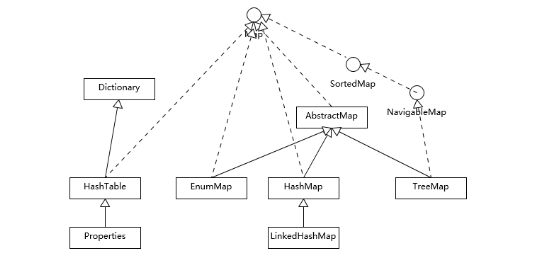
HashTable是java早期的hash实现,实现了Dictionary接口;
TreeMap是根据比较器来决定元素的顺序;
LinkedHashMap 按照插入的顺序来遍历。下面的代码是一个不经常使用的资源自动释放的例子。
package org.example.mianshi;
import java.util.LinkedHashMap;
import java.util.Map;
/**
* 不常使用的资源被释放掉
*
*/
public class App
{
public static void main( String[] args )
{
LinkedHashMap<String,String> linkedHashMap = new LinkedHashMap<String,String>(){
@Override
protected boolean removeEldestEntry(Map.Entry<String, String> eldest) {
return size()>3;
}
};
linkedHashMap.put("a","aaa");
linkedHashMap.put("b","bbb");
linkedHashMap.put("c","ccc");
linkedHashMap.forEach((k,v)->System.out.println(k+" = " + v));
System.out.println(linkedHashMap.get("a"));
System.out.println(linkedHashMap.get("b"));
System.out.println(linkedHashMap.get("c"));
linkedHashMap.forEach((k,v)->System.out.println(k+" = " + v));
linkedHashMap.put("d","ddd");
System.out.println("=========");
linkedHashMap.forEach((k,v)->System.out.println(k+" = " + v));
}
}
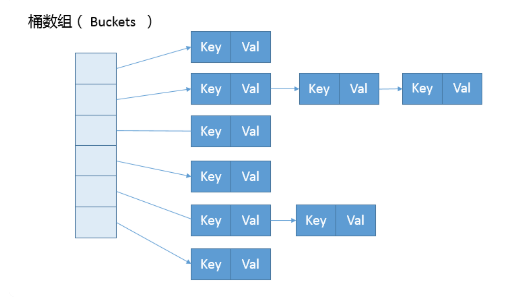
HashMap的源码分析
数据结构: Node[] table , 首先是一个数组,数组的元素是一个链表;
如下图: 数组叫做桶,数组的单个元素中的链表叫做bin;
put操作涉及的关键源码如下:
final V putVal(int hash, K key, V value, boolean onlyIfAbent,boolean evit) {
Node<K,V>[] tab; Node<K,V> p; int , i;
if ((tab = table) == null || (n = tab.length) = 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == ull)
tab[i] = newNode(hash, key, value, nll);
else {
// ...
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for first
treeifyBin(tab, hash);
// ...
}
}
路由规则:
key计算hash值, hash值%数组长度= 数组的索引; 通过索引找到对应的数组元素,如果hash值相同,则在该链表上继续扩展。
如果链表的大小超过阈值,则链表会被树化。
hashMap的hash值的计算:
static final int hash(Object kye) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>>16;
}
这么设置算法是为了降低hash碰撞的概率,数据计算出来的hash值差异一般是在高位,上面的代码是忽略容量以上的高位(进行了位移)。
扩容逻辑
final Node<K,V>[] resize() {
// ...
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACIY &&
oldCap >= DEFAULT_INITIAL_CAPAITY)
newThr = oldThr << 1; // double there
// ...
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// zero initial threshold signifies using defaultsfults
newCap = DEFAULT_INITIAL_CAPAITY;
newThr = (int)(DEFAULT_LOAD_ATOR* DEFAULT_INITIAL_CAPACITY;
}
if (newThr ==0) {
float ft = (float)newCap * loadFator;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);
}
threshold = neThr;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newap];
table = n;
// 移动到新的数组结构e数组结构
}
如果没指定容量和负载因子,按照默认的负载因子和容量初始化;
门阀值=容量 * 负载因子,门阀值按照倍数扩容
扩容后,会把老的数组中的元素复制到新的数组,这是扩容开销的主要来源;
树化
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
//树化改造逻辑
}
}
哈希碰撞:元素在放入hashmap的过程中,如果一个对象hash冲突,妒被放置到同一个桶里面,会形成一个链表,链表的存取耗费性能,无法达到常数级别的时间复杂度;如果大量的hash冲突,则会形成一个长链表,如果客户端跟这些数据交互频繁,则会占用大量的cpu,导致服务器宕机拒绝服务。
树化的目的是:为了安全,减少hash冲突;
小结
先从线程安全,是否允许null键值,使用场景方面说出来HashTable,HashMap,TreeMap的区别。
然后扩展到了Map的类层级,分析了面试官喜欢问的hashmap的数据结构,hash值计算,扩容,树化问题。
原创不易,转载请注明出处,让我们互通有无,共同进步,欢迎沟通交流。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

