Java 基础 - 数组
目录
数组是编程语言中最常见的一种数据结构,可以用于储存多个数据,通常可通过数组元素的索引来访问数组元素,包括数组元素赋值和取出数组元素的值.
初识数组
- 数组也是一种类型,属于引用数据类型.
- 数组元素的类型是唯一的,一个数组里只能存储一种类型的数据.
- 数组的长度是固定的,即一个数组一单初始化完成,数组在内存中所占的空间将被固定下来,长度不在发生改变.即使把某个数组的元素清空,其所占的空间依然被保留.
数组的初始化
定义数组变量
Java支持两种语法格式定义数组:
type[] arr; type arr[];
对于这两种定义而言,通常使用第一种格式来定义数组,因为第一种有更好的语义.第二种容易和变量名混淆
初始化
Java 数组只有初始化之后才能使用,所谓的初始化,就是为数组的元素分配内存空间.并为每个数组元素赋初始值.
静态初始化
由程序员显示的指定每个数组原始的初始值.由系统决定数组的长度.
静态初始化的语法格式为:
type[] arr = new type[]{item1, item2, item3,...};
type 为数组元素的数据类型, 数组元素类型必须为 type 类型,或者其子类的实例.
除此之外,静态初始化还有如下简化的语法格式:
type[] arr = {item1, item2, item3 ...};
动态初始化
动态初始化只指定数组的长度,由系统为每个元素指定初始值,动态初始化的语法格式如下:
type[] arr = new type[length];
上面的语法中,需要指定一个 int 类型的 length 参数,这个参数指定了数组的长度.
执行动态初始化时,程序员只指定数组的长度,数组元素的初始值由系统按照如下自动分配
- 数组元素类型是基本类型中的整数类型(byte, short, int, long),则数组元素的值是 0.
- 数组元素类型是基本类型中的浮点类型(float, double),则数组元素的值是 0.0.
- 数组元素类型是基本类型中的字符类型(char),则数组元素的值是'/u0000'.
- 数组元素的类型是基本类型中的布尔类型(boolean),则数组元素的值是 false.
- 数组元素的类型是引用类型(类,接口,数组),则数组元素的值是 null;
数组的访问
数组最常用的方法就是访问数组元素,包括对数组元素进行赋值和取出数组元素.
数组元素读取、赋值
int[] arr = {1,2,3};
// 数组取值 通过 arr[index] 访问
int a = arr[0];
// arr 为{1,3,3}
arr[1] = 3
如果访问数组元素时指定的索引值小于0,或者大于等于数组的长度,编译程序时不会出现任何错误,但运行时出现异常 java.lang.ArrayIndexOutOfBoundsException:N (数组越界异常), N 就是试图访问的数组索引.
数组的遍历
for 循环
int[] arr = new int[5];
// 输出 5 个 0
for(int i = 0; i < arr.length; i++){
System.out.println(arr[i])
}
arr[1] = 1;
arr[2 = 2;
// 输出 0 1 2 0 0
for(int i = 0; i < arr.length; i++){
System.out.println(arr[i])
}
上面的代码第一次循环输出 5 个 0,因为 arr 数组执行的是默认初始化,数组元素是 int 类型,系统为 int 类型的数组元素初始化赋值为 0.
foreach 循环
Java5 之后,Java 提供了一种更简单的循环: foreach循环 ,这种循环遍历数组和集合更加方便.
for (type item : array|collection){
//
}
使用 foreach 循环需要注意:
int[] arr = {1, 2, 3, 4, 5};
for (int item: arr){
System.out.println(item);
item = 0;
System.out.println(item);
}
System.out.println(arr[0]);
上例程序将输出
由输出结果可以看出来,在 foreach 循环中对数组元素进行赋值,结果导致不能正确的遍历数组元素.同时在循环中为改变的数组元素的值并没有真正改变数组元素,因为在 foreach 中循环变量相当于一个临时变量,系统会把数组元素一次赋值给这个临时变量,而这个临时变量并不是数组元素,它只是保存了数组元素的值.因此要注意: 如果希望改变数组元素的值,则不能使用这种 foreach 循环 .
深入了解数组
JDK 中的 Array
查看 Java源码中的 Array 类可以发现它是个 final class , 其中方法如下:
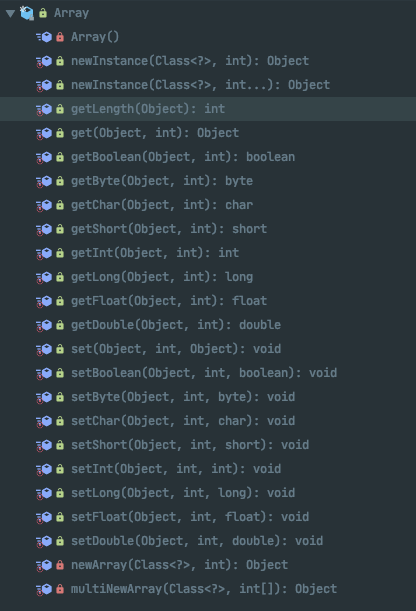
Array 类中基本都是 getXX 和 setXX 方法,
并且全部都为 native 方法.使用 native 关键字说明这个方法是原生函数,也就是这个方法是用 C/C++ 语言实现的,并且被编译成了DLL,由java去调用,因此我们可以将数组理解为是由计算机本地方法去实现的类,并不属于 Java.
数组的内存分布
数组是一种引用数据类型,数组的引用变量时存储在栈内存中的,而数组元素是在堆内存中,并且是连续存放的.这是为了能快速存取数组元素,因为只需要移动index(内部计算物理地址: 数组起始地址+index * 元素size大小 )就可以访问,而这是很快的 O(1)。
在Java 内存模型中,数组对象被存储在堆(heap)内存中;如果引用该数组对象的变量是一个局部变量,那么它被存储在栈(stack)内存中.如下图所示:
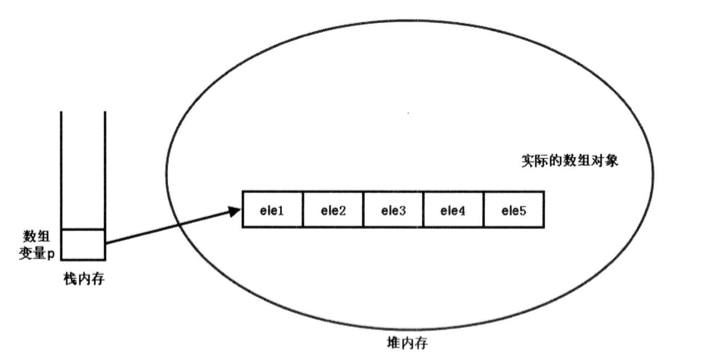
如果需要访问上图堆内存中的数组元素,在程序中只能通过 p[index]的形式实现.也就是说,数组引用变量时访问堆内存中数组元素的根本方式.
现有如下代码:
// 定义并静态初始化数组
int[] a = {5, 7, 20};
// 定义数组,使用动态初始化
int[] b = new int[4];
System.out.println("b 数组的长度为: " + b.length);
// 循环输出 a 数组的元素
for (int i = 0, len = a.length; i < len; i++ ){
System.out.println(a[i]);
}
// 循环输出 b 数组的元素
for (int i = 0, len = b.length; i < len; i++ ){
System.out.println(b[i]);
}
// 将 a 的值赋给 b,即将 b 的引用指向 a 引用指向的数组
b = a;
// 再次输出 b 数组的长度
System.out.println("b 数组的长度为: " + b.length);
运行上例代码,首先会输出 b 的长度为 4,然后输出 a,b 的各项元素,接着输出 b 的长度为 3.看起来数组的长度是可变的,其实这是一个假象.
上例代码内存分析:
-
初始化 a,b 数组,在内存中产生了 4 块区域,栈中的引用变量 a,b 以及堆中的实际数组对象. 其中 a 引用的数组对象长度为 3, b 引用的数组长度为 4.

-
程序执行
b = a操作.系统会将 a 的值赋给 b,即将 a 引用的数组对象的内存地址赋给 b,此时 b 的值为 a 引用的数组对象的内存地址.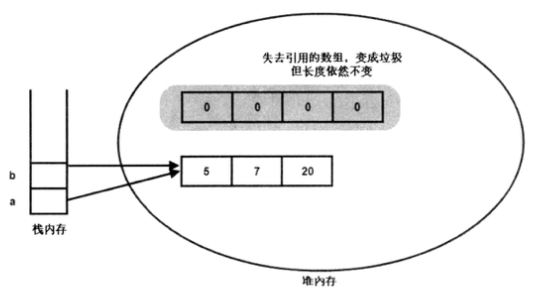
从上可以看出,程序执行 b = a 之后,b 之前引用的数组对象长度并没有发生任何改变,而 b 的值变成了 a 引用的数组对象的地址,此时 b 数组的长度即为 a 数组的长度 3.
需要注意的是数组元素的内存空间是连续的,是指
- 如果数组元素是原始类型,那么数组元素存放的就是原始类型的值,他们是连续存放的
- 如果数组元素是对象,那么数组元素就是存放引用了,数组元素是连续存放的,而引用的对象可能在另外的地方,与数组元素可能相隔很远,即不连续。
多维数组
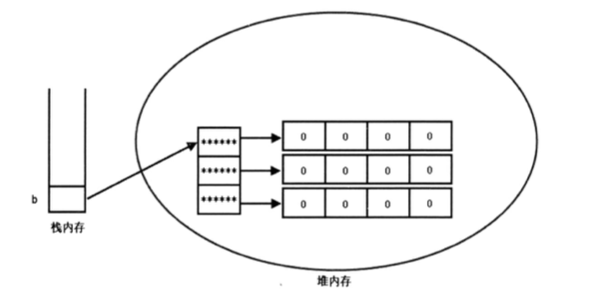
Java 提供了支持多维数组的语法,但是从数组底层的运行机制上来看,并不存在多维数组.
多维数组的定语语法为
type[][] arr = new type[length1][length2]
length2 可动态创建.
二维数组本质就是一位数组中的每个元素都是一个一维数组. 如上 length2 给出了值,则初始化了一维数组中的每个元素都是一个长度为 length2 的一维数组.其内存模型为:
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

