高并发场景-请求合并(一)SpringCloud中Hystrix请求合并
在互联网的高并发场景下,请求会非常多,但是数据库连接池比较少,或者说需要减少CPU压力,减少处理逻辑的,需要把单个查询,用某些手段,改为批量查询多个后返回。 如:支付宝中,查询“个人信息”,用户只会触发一次请求,查询自己的信息,但是多个人同时这样做就会产生多次数据库连接。为了减少连接,需要在JAVA服务端进行合并请求,把多个“个人信息”查询接口,合并为批量查询多个“个人信息”接口,然后以个人信息在数据库的id作为Key返回给上游系统或者页面URL等调用方。
目的
- 减少访问数据库的次数
- 单位时间内的多个请求,合并为一个请求。让业务逻辑层把单个查询的sql,改为批量查询的sql。或者逻辑里面需要调用redis,那批量逻辑里面就可以用redis的pipeline去实现。
主要解决手段
- SpringCloud的Hystrix的自定义BookCollapseCommand 或者 注解方式。
- 没有服务质量框架时,利用JDK队列、定时任务线程池处理。 鉴于现在大部分都有SpringCloud,所以先说第一种的注解方式,后续再说第二种,注解方式比较方便。
交互流程
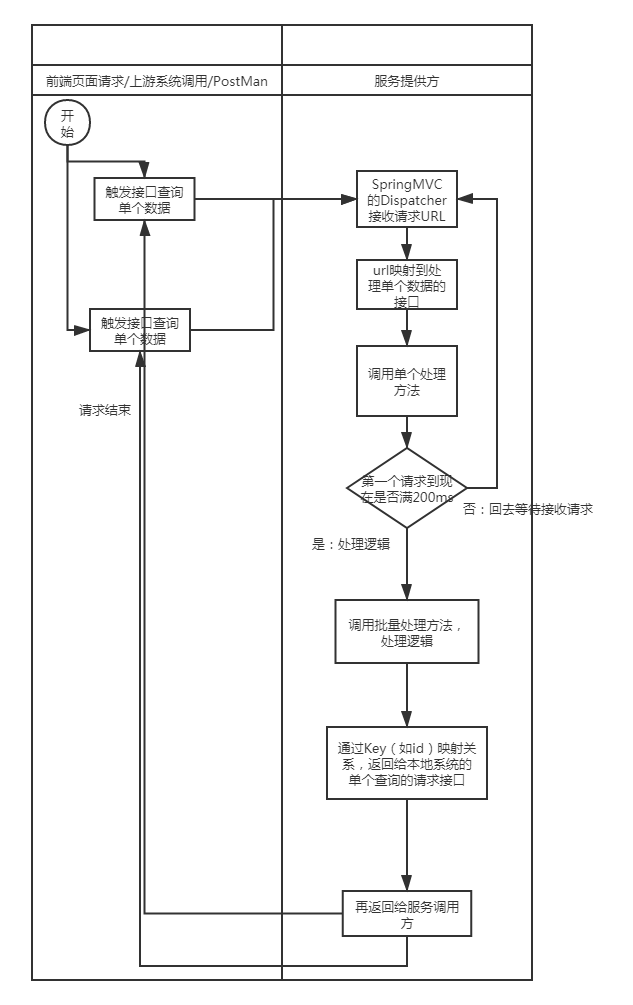
- 主思路是接收请求后,从上一次计数开始累计等待200ms
- 一次过处理200ms内的接口入参
- 然后以id为key,批量查询多个id的结果
- 批量查询完后,以id为key,返回给上游系统的单个查询
测试手段
- Postman
- 在本地系统创建单元测试方式,调用自己启动的服务
- 建立上游系统工程来调用
- 手动在页面请求多次
- Jmeter生成多线程请求
选其一种。建议1、2
开发
本文主要使用注解的方式去实现,其实还有另外一种办法实现的,那种方法是建立两个类,一个继承HystrixCollapser,另一个继承HystrixCommand,这个方法比较显式的编码声明有助于理解。
编码方式和注解方式实现请求合并的优劣
虽然注解方式比较快,但是不能做到实时更改等待的单位时间,放在注解上,如果要更改单位时间,其实都需要重启服务或者重新编译打包。
用编码方式比较好的地方就是可以在运行过程中,读字典表去更改单位时间,这样线上出问题了就不用重启了。
但是编码方式缺点还是有的,因为绑定一个批量方法就要建立一个HystrixCommand类,如果有多个请求合并的情况,就只能建立多个HystrixCommand类了。
1. 添加POM
声明springboot 和springcloud版本 以前的工程使用了1.4.7.RELEASE,Camden.SR2。其实大家可以用新版本的,只是新版本的eureka、Feign依赖的artifactId改变了,但是后续使用方式是一样的。
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.4.7.RELEASE</version> </parent> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Camden.SR2</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> 复制代码
添加关键依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.2.2</version>
</dependency>
复制代码
2. 启动注解
除了SpringCloud客户端所基本需要的@SpringBootApplication @EnableEurekaClient,主要加上@EnableCircuitBreaker。因为使用到hystrix的都必须声明这个注解,为了启动断路器的意思,如熔断的时候也会使用,熔断也是通过hystrix来实现的。 这个比较关键,不启动的话,后续编码怎么弄都不生效的
@SpringBootApplication
@EnableDiscoveryClient
//使用hystrix必须增加
@EnableCircuitBreaker
@EnableEurekaClient
@EnableSwagger2
public class ProviderRequestMergeApplication {
public static void main(String[] args) {
SpringApplication.run(ProviderRequestMergeApplication.class, args);
}
}
复制代码
3. 请求接口Controller
编写两个接口,user方法是没有经过合并请求的样例,在本案例实际没有作用,只是用于校验合并与不合并的效果。 userbyMerge方法在合并请求的方法,其作为请求接口入口,合并请求的逻辑,并不需要在Controller里面实现,使得Controller只作为请求这一层,不耦合其他功能。
/**
*
* @author kelvin.cai
*
*/
@RestController
public class UserController {
@Autowired
private UserBatchServiceImpl userBatchServiceImpl;
@RequestMapping(method = RequestMethod.POST,value = "/user/{id}")
public User user(@PathVariable Long id) {
User book = new User( 55L, "姚雪垠2");
return book;
}
@RequestMapping(method = RequestMethod.GET,value = "/userbyMerge/{id}")
public User userbyMerge(@PathVariable Long id) throws InterruptedException, ExecutionException {
Future<User> userFu = this.userBatchServiceImpl.getUserById(id);
User user = userFu.get();
return user;
}
}
复制代码
4. 编写请求合并逻辑
/**
*
* @author kelvin.cai
*
*/
@Component
public class UserBatchServiceImpl {
@HystrixCollapser(batchMethod = "getUserBatchById",scope=Scope.GLOBAL,
collapserProperties = {@HystrixProperty(name ="timerDelayInMilliseconds",value = "2000")})
public Future<User> getUserById(Long id) {
throw new RuntimeException("This method body should not be executed");
}
@HystrixCommand
public List<User> getUserBatchById(List<Long> ids) {
System.out.println("进入批量处理方法"+ids);
List<User> ps = new ArrayList<User>();
for (Long id : ids) {
User p = new User();
p.setId(id);
p.setUsername("dizang"+ids);
ps.add(p);
}
return ps;
}
}
复制代码
这里有几个关键点(如果没生效可以看看)
- @HystrixCollapser参数batchMethod 的值为批量处理的方法的名字,批量处理方法必须在同一个类中。
- 单个处理方法和批量处理方法必须要同一个基本类型,只是批量方法需要使用List去包裹
- 单个处理方法,建议用Future,这个是jdk线程异步获取的那个类,用于异步获取结果。其实有另外的返回类型,让调用getUserById使用同步阻塞的方式去使用,但是不是很建议。
- scope有两个值一个是Scope.REQUEST,意思就是当次请求接口内调用UserBatchServiceImpl.getUserById多次才会合并。想想看,如果我一个接口内,调用多次单个插叙,为何不直接使用一个批量查询呢?我没想到有什么场景会需要这个值。 scope有另外一个值Scope.GLOBAL,就是样例所示的值,意思就是,所有请求接口进来都合并。大家回顾一下需求目的,就比较符合要求了,如多个支付宝用户查询自己的信息时就是合并全局请求。
- @HystrixProperty填合并请求的单位时间,debug时可以把他设置为5秒,比较好测试。
这里有个包路径的建议
这个合并请求类UserBatchServiceImpl 不建议放在业务逻辑层,为了保持业务逻辑service层代码是干净的只保留业务逻辑,所以这个UserBatchServiceImpl 类建议放在另外一个包collapser下,让这个包路径只是用于处理请求合并的事情。
因为这个类是利用springcloud框架实现,万一以后不用springcloud来做合并请求而用原始队列加线程池怎么办?
而且有些工程设计时,是建立server工程只做请求和服务治理,搞另外一个工程专门写domain领域下的东西,不包含其他框架的,这样为了第三个工程叫job定时任务工程可以直接使用domain工程的依赖。 这个领域驱动设计,请看我之前的文章。
测试方法
1. 触发测试
swagger-ui 如果你有添加swagger,那你打开http://localhost:7902/swagger-ui.html,对接口填一下参数请求两次。
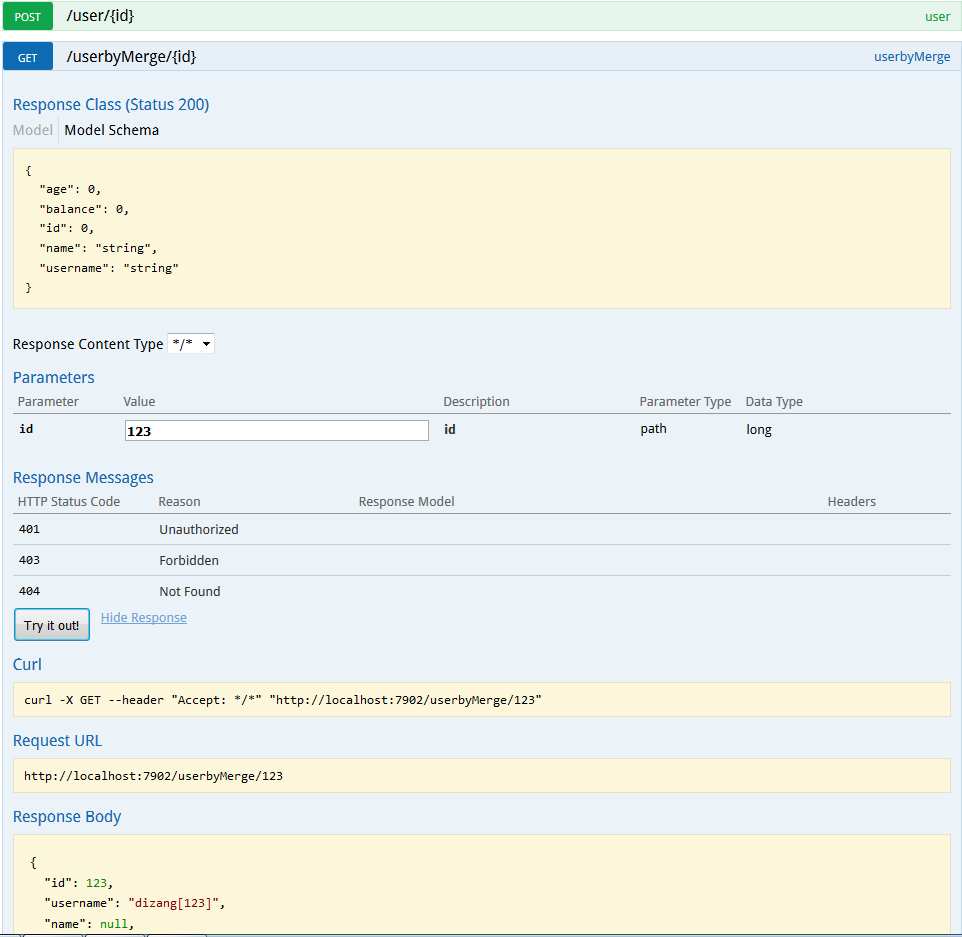
2. 结果输出
下图中,console日志已经输出了两次请求的入参

3. PostMan测试
其实还可以使用Postman来同时请求相同接口。做法暂时不描述。
总结
到这里相信大家都已经完成了合并请求了,其实原理还是基于原始做法,利用队里存入参,然后利用线程池定时的获取队列的入参,再批量处理,利用线程的Future,异步返回结果。大致流程是这样的就不再描述了,如果有空会继续弄原始方法的请求合并。 大家还可以去看看Hystrix合并请求的其他参数,搜索相关信息来扩展hystrix功能。
正文到此结束
- 本文标签: http 线程 id redis DOM 单元测试 总结 Property sql 需求 Hystrix Eureka web src 数据库 服务端 数据 HTML 连接池 开发 质量 线程池 cat 代码 bug list java client tar IO UI App ArrayList dependencies pom Job 互联网 多线程 springboot value spring 同步 https 个人信息 支付宝 JMeter Feign 参数 测试 文章 压力 IDE 高并发 key 并发 provider ip Service map 时间 springcloud REST 编译
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

