揭秘万亿级别的全域数据统计分析平台技术架构演进
作者:友盟+技术专家 王翔
截止到2019年6月,友盟+已累计为180万移动应用和815万家网站提供10年的专业稳定数据服务;当前友盟+每天接收日志量达万亿级别,实现每秒处理2亿次事件的能力,相当于每眨眼一次,就有2亿数据被刷新了!友盟+数据存量高达50PB,相当于A4纸正反面写满数字并装满15万辆卡车;且还在持续快速增涨,如何搭建一个高可用、高安全、高性能、高稳定的友盟+全域数据统计分析数据平台架构,成为友盟+技术人首先需要考虑的问题。
把时间轴拉回到2016年初,当时友盟+的业务处于快速成长期,友盟+的数据统计分析服务都搭建在一系列的开源软件之上,业务前端是Nginx采集层,后端离线计算是的Hadoop集群,后端实时计算是用的Storm集群;而当业务快速增长,用户各类个性化统计需求层出不穷,之前开源集群上一些小bug会被放大,导致业务出现波动,稳定性无法保障,而且在使用场景上也无法根据自己业务特点来进行调整。为保障平台业务稳定性,满足用户在统计方面提出的各种新的统计需求,在2016年中旬我们制定了把友盟+全域数据统计分析平台升级计划:
友盟+新统计分析数据平台简述
友盟+数据平台技术架构主要包含数据采集&接入、数据清洗&传输、数据建模&存储、计算&分析、查询&可视化,其SaaS服务部分基本架构参考下图。
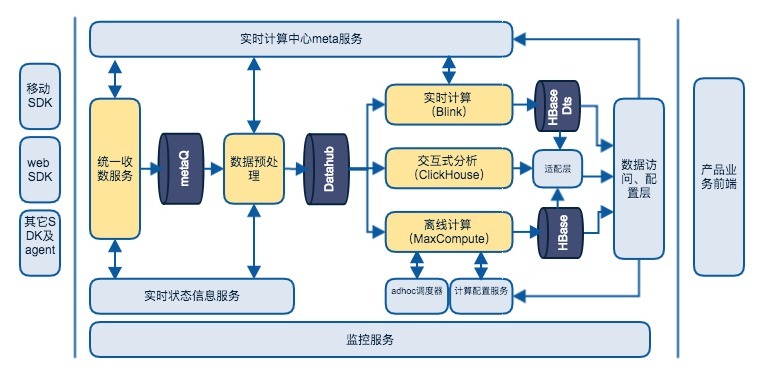
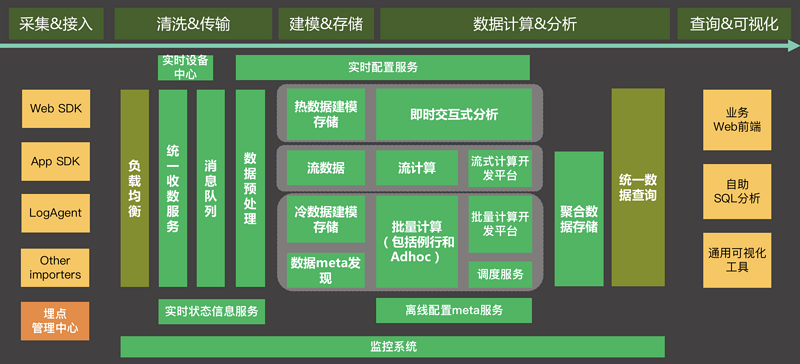
这是一个非常概要的架构图,这个架构被称为lambda+架构。尽管近几年有一些新的架构提法,比如Kappa之类,但lambda仍然是经典架构。友盟+统计分析产品无论是移动分析U-App还是网站分析U-Web,都为用户预置了功能丰富的报表,这些报表是在多年服务客户的过程中积累的需求。对于预定义报表,lambda架构进行预计算非常适合,客户只需要集成基本的SDK,就能得到这些丰富的报表。因为结果都是预计算好的,直接查询结果,报表响应很快。
那为什么叫lambda+架构呢,加的部分主要是指adhoc分析,adhoc分析对数据化运营真正进行了赋能。友盟+新的统计分析服务允许客户进行adhoc细分、漏斗、留存、分群等,并对一些常规的分析则可以设置为例行计算。但adhoc分析从时效上可以有两种服务,一种是慢分析,一种是交互式分析。前者能提供精确的全量分析,后者侧重分析探索效率,这种分级方式是我们对成本和效率的折中。
在友盟+新的统计分析平台中,最主要的能力集中于海量数据的实时计算能力和离线计算能力和交互式分析能力,以及这些能力提供出来的数据分析能力。
友盟+实时计算使用blink(flink),blink功能非常完整,有高效状态存储及checkpoint机制,支持数据幂等计算。实际上友盟+实时计算引擎进行数次更换(storm->galaxy->blink),以后还可能再换或引入别的引擎(比如私有化),所以我们开发了一套与引擎无关的实时计算框架,该框架整体上分为两层:core层和适配层。core层定义了一些基本的对象、接口、算子,以及一些通用的辅助对象和业务flow。这些基本对象、接口、业务flow与前面提到的lambda通用计算框架是一致的。适配层的目的是适配不同的计算引擎,比如blink、beam、spark streaming,这一层实现较薄,其关注点不再是业务逻辑,而是如何选择作业参数、如何配置资源、是否做作业拆分这些问题。
实时计算的挑战主要有以下这些:
数据倾斜问题:个别客户数据量巨大,用户数巨多,站点及应用级别的统计数据倾斜十分严重;某些统计粒度太小(比如按受访页面或来路页面),对细粒度统计进行排序甩尾的节点压力会比较大。数据倾斜的普通解法是通过数据加salt打散局部聚合再汇总的方式,但这种方式需要多加一个处理层,资源消耗较大。我们采取的方式将实时计算变为小批量,然后在map层进行local reduce(类似于hadoop map层的local combine)。这种简单处理系统性地既解决了数据倾斜的问题,又减少了聚合计算map层和reduce层传输的数据量,提升了性能。
巨量groupby key和状态存储:以web统计为例,需要对来路页面、受访页面级别进行pv、uv统计。个别大客户单天key的数量就超过2亿,总key的数量是百亿级。解决办法包括:短key替换长key、长尾key过滤、自动采样还原等。
高tps输出:以web统计为例,因为几乎所有指标都进行实时计算,高峰期每秒更新的统计结果超过300W。我们一方面通过异步buffer刷新方式牺牲一定时效性(秒级延时->分钟级延时),降低实际数据输出tps;另一方面没有使用通常的hbase等系统存储实时计算结果,而是使用自研的一套系统,该系统不但支持很高的刷写性能,而且还支持不同列的topN索引功能。
distinct计算优化。我们的优化手段:再etl阶段打标,将count distinct转化为count,比如新增用户首次出现时增加一个新增标记;使用自适应基数估计算子(比如hyperloglog),当基数低于一定阈值时使用set,超过后自动转为基数估计数据结构,还可以进一步结合bitmap压缩算法;基于bloomfilter将count distinct转换为count。
在友盟+新的统计分析平台中,离线计算与实时计算类似,其实现方式与前面提到的lambda通用计算框架一致,单个作业即支持不同用户不同的计算需求。与实时计算的差别在于distinct计算不需要使用基数估计,更加精确。
离线计算使用阿里云MaxCompute,例行计算使用MaxCompute的SQL+UDX通过类似Apache Tez的DAG计算完成工作,对速度要求较高的adhoc分析使用MaxCompute集成的Spark进行计算。
在友盟+新的统计分析平台中交互式分析使用的是俄罗斯Yandex开源的Clickhouse。Clickhouse不是一个通用型分析数据库,但针对基于明细数据的多维分析做了深度优化,在成本和性能上表现很好,同时支持数据的准实时写入。Clickhouse除了一般多维分析,内置算子也十分丰富,同时允许用户自定义聚合函数做复杂行为分析。Clickhouse的存储设计同样遵循我们前面讨论的一些原则。Clickhouse对纯的基于Event的分析支持很好,但如果引入User表进行交叉分析则不是很方便,所以我们也在深入研究Event + User 模型,尝试为其设计开发特定的存储引擎。
新的统计分析平台中数据分析系统主要解决产品研发及运营效率问题,比如通过精准推广降低拉新、留活成本,比如基于数据(a/b test)优化产品流程减少试错成本、加快迭代速度。分析的主要数据基础就是用户对产品功能、推广活动等的行为反馈,这些数据本质上是运营样本数据。通过这些样本数据做一些假设,指导运营活动和产品设计。
广义的用户行为分析包括用户自定义分群、留存分析、漏斗分析、流失分析、路径分析等等。目的是根据用户的历史行为以及用户profile信息,了解不同人群的特征,从而差异化的进行运营,以满足更精准的营销。其中历史行为是基于时间的纵向信息,该信息往往有时效性,也即越靠近分析时间点,越有价值。但并不是说旧的历史行为就完全没有价值,很久以前发生的行为虽然单个事件价值低(且直接使用成本也比较高),但通过数据挖掘可沉淀出用户标签,将具体行为变为抽象描述。相对于用户历史行为,用户profile是横向信息,其中有一些属性是完全静态的,比如性别;另外一些会保持稳定一段时间,比如标签;还有一些是adhoc即时生成(比如临时根据某种条件筛选一个用户分组)。
用户行为分析的基本计算过程是:过滤、分组、按人建立事件行为拉链、时间序列算法(不同的分析目标有不同的时间序列算法)、汇总统计。友盟+对常用用户行为分析模型进行了统一的计算抽象。使用者只需要在页面配置相关参数,即可通过数据平台提供的标准计算作业完成分析。用户行为分析也支持例行、adhoc(单次)两种执行方式。其中adhoc支持离线和交互式分析两种,但需要在数据量和计算时效上折中,也即:对较短时间内数据(比如一个月)提供即席分析,而对更大时间跨度或更老的数据进行分析,使用离线的adhoc分析。离线分析使用MaxCompute SQL或者SPARK。
同时为保证友盟+新的统计分析平台的安全和合规,我们在安全方面实施了一系列部署(全站https、网络层ddos攻防演练和策略实施),来提升安全性,保障业务稳定性。
友盟+获得了ISO/IEC 27001:2013 信息安全管理体系认证、ISO/IEC 27018:2019 公有云个人信息保护管理体系认证,成为国内首批获得此高标准公有云个人信息保护证书的大数据服务商。友盟+同时拥有公安部颁发的信息系统安全三级等保证书。
为保障友盟+新的统计分析平台整体的稳定性和高效性,在效能方面,我们统一了开发语言,提高了代码的可维护性;建立了统一的采集平台,把原来多业务的多套采集服务归一化,在提供代码可维护性的同时,也把原来多个小的资源池转变为一个大的资源池,增加了业务异常增量的可控性,保证了业务的稳定性,同时推动业务无状态和容器化,当前95%的应用已完成无状态改造,并跑在容器上,通过平台的快速扩容能力,可以应对90%的客户业务量突增情况。
在稳定性方面,友盟+开始规划和部署采集服务双机房异常部署,同时参加机房容灾演练,从架构上保证业务稳定性;同时在接入层推动对IPv6的支持,保障各种网络场景下采集数据的完整性;在业务层,我们推行核心业务稳定性分策略,通过发布控制,代码强制review控制,灰度时常控制,应急策略控制等等来进一步增加业务的稳定性。
当前友盟+新的统计分析平台已支持多样性的数据采集、个性化的自定义分析、可实现精细化运营分析;同时提供可视化埋码能力,降低用户使用门槛;扩展多平台的数据采集能力,协助用户打通多域数据,完善数据化运营的闭环。
正文到此结束
- 本文标签: web 数据库 map 代码 参数 统计 个人信息 lambda apache sql 可控性 阿里云 core ORM 幂等 云 https HBase 管理 软件 src 业务层 存储引擎 ip 安全 大数据 架构演进 dist 营销 索引 Hadoop 集群 数据 key 自适应 数据挖掘 本质 认证 网站 开源软件 App http bug 2019 站点 产品 UI 时间 开源 推广 模型 部署 Nginx 压力 配置 需求 开发 运营 高可用 stream
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

