【JAVA程序员进阶之路】索引中一些易忽视的点
从接触java到现在也有差不多两年时间了,两年时间,从一名连java有几种数据结构都不懂超级小白,到现在懂了一点点的进阶小白,学到了不少的东西。知识越分享越值钱,我这段时间总结(包括从别的大佬那边学习,引用)了一些平常学习和面试中的重点(自我认为),希望给大家带来一些帮助
这是这篇文章的思维导图,因为用的是免费版的软件,所以有不少水印,需要的可以问我要
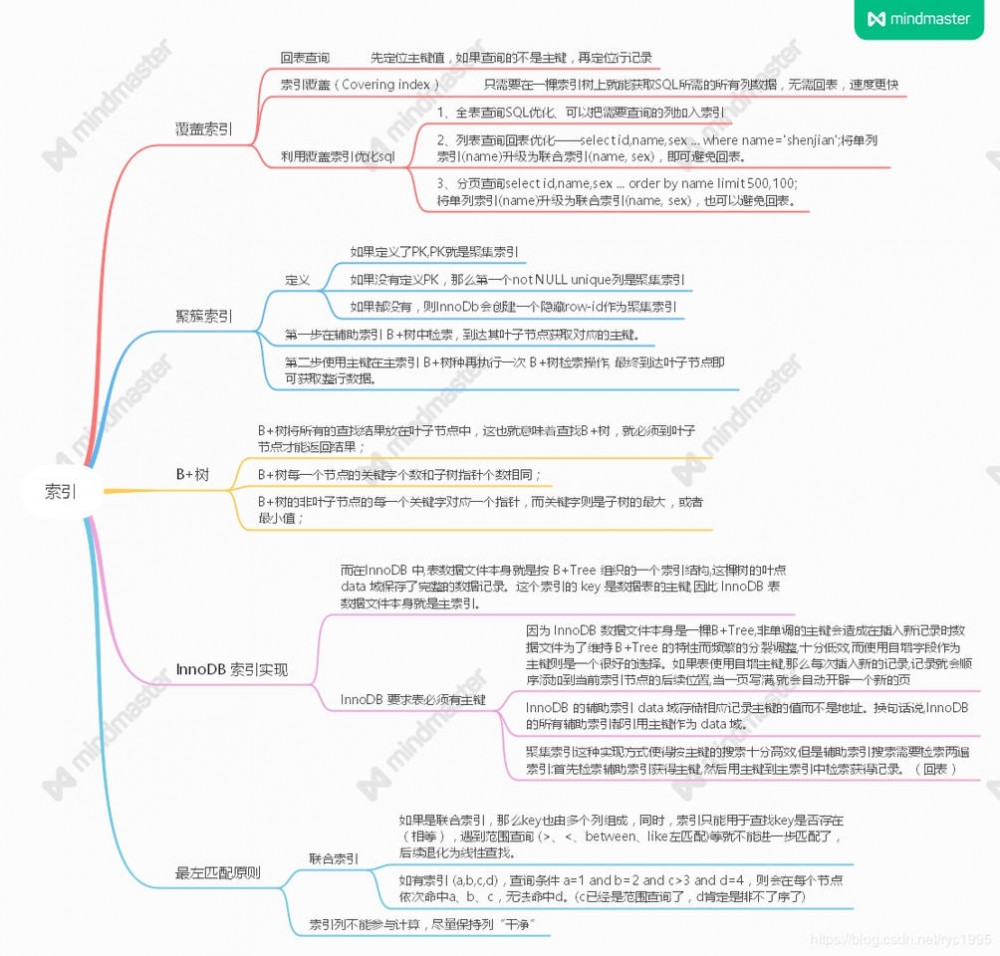
从索引开始
为什么会选择从索引开始,大概是我最近建了不少的表吧,其中一个负责做配置表同时负责了两个业务**(有不少通用字段,而且表内容很少很少,或许最多就30行吧)**,因主键和索引纠结了一会 (其实根本不需要纠结) ,所以就决定先分享(复习)一下索引的内容。
1、覆盖索引
什么是覆盖索引?如果一个索引包含了满足SQL语句中字段与条件的数据,那么它就叫做覆盖索引。 覆盖索引只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
既然提到了回表,那么我先讲一下什么叫回表。 说到了回表,又不得不提一下聚集索引和辅助索引 我得去大佬的文章找一下图片方便大家理解 (引用自大佬架构师之路的文章)
1、1回表
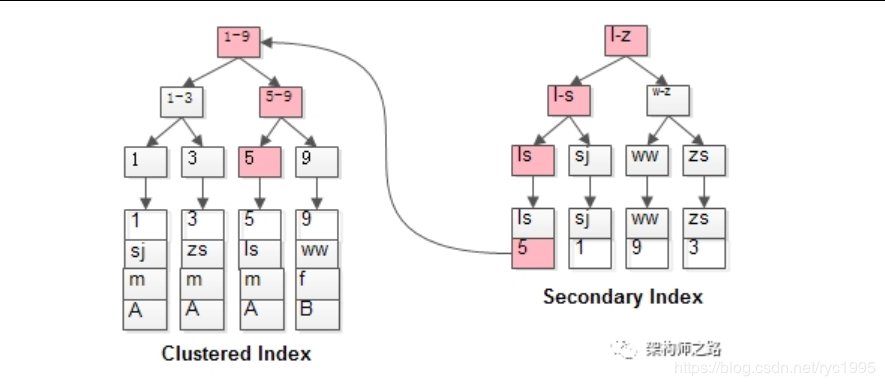
- 第一步在辅助索引 B+树中检索 , 到达其叶子节点获取对应的主键
- 第二步使用主键在主索引 B+树种再执行一次 B+树检索操作, 最终到达叶子节点即可获取整行数据。
我们能很清晰的看出来,左边的是 聚集索引 ,右边的是 辅助索引 ,上图告诉我们如果回表查询的话,会先在辅助索引中找到主键值,再去聚集索引中找到全部的信息。在InnoDB 中,表数据文件本身就是按 B+Tree 组织的一个索引结构,这棵树的叶点data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引(聚集索引)。 流程大概如下:
- 如果定义了主键,那么主键就是聚集索引
- 如果没有定义主键,那么第一个not NULL unique列是聚集索引
- 如果都没有,则InnoDb会创建一个隐藏row-id作为聚集索引
而辅助索引就是我们平常用到的非主键索引啦
1、2利用覆盖索引优化sql
我们通过覆盖索引,查询想要的数据字段都是索引键值的一部分,直接存放在索引的子叶层级,不需要通过辅助索引来一次回表查询,效率很高。 覆盖索引不仅仅只包含你写在WHERE条件内的字段,而且还包含所有SELECT 需要的字段,以及在GROUP BY 或ORDER BY 子句内的字段 。
那么我可以怎么通过覆盖索引来优化我们的sql呢? 1、全表查询SQL优化、可以把需要查询的列加入索引
select count(name) from user; 比如这个很常见的查询数量的sql,我们就可以把user加入索引,这样就可以免去回表查询 ALERT TABLE user ADD index index_name(name);
2、列表查询回表优化
select id,name,sex from user where name='fawaikuangtuzhangsan' 复制代码
ALERT TABLE user ADD index index_name_sex(name,sex);
将单列索引(name)升级为联合索引(name, sex),即可避免回表。
3、其他的都差不多,都是通过将所有查询的列加入覆盖索引以达成防止回表的目的,当然,这个东西需要看情况用,不然长长的索引列也会带来长长的麻烦,比如我开头提到的表就完全不需要
覆盖索引可以完美的解决二级索引回表查询问题。但是前提是一定得注意查询时候索引的最左侧匹配原则
2、最左匹配原则
什么是最左匹配原则? 最左优先,以最左边的为起点任何连续的索引都能匹配上。如果是联合索引,那么key也由多个列组成,同时,索引只能用于查找key是否存在(相等),遇到范围查询 (>、<、between、like左匹配)等就不能进一步匹配了,后续退化为线性查找。
比如我建立了联合索引abc
ALTER TABLE `ryc` ADD INDEX index_a_b_c(`a`,`b`,`c`); 复制代码
select * from ryc where a = '1' and b = '2' and c = '3' select * from ryc where b = '2' and a = '1' and c = '3' select * from ryc where c = '3' and b = '2' and a = '1' select * from ryc where a = '3' and b = '2' select * from ryc where a = '3' 复制代码
这些情况搜索都不影响查询结果,因为它们都是从最左边开始,同时因为Mysql中有查询优化器,会自动优化查询顺序 ,当然我们最好可以按顺序写,最少看起来都舒服一些
select * from ryc where b = '3' and c = '2' select * from ryc where b = '3' 复制代码
而这些没情况有从最左边开始,最后查询没有用到索引,用的是全表扫描
select * from ryc where a = '3' and c = '2' 复制代码
如果是这种情况呢,就只命中了a的索引,c还是得老老实实的去扫描
如果遇到了><之类的范围查询,在范围查询之前,如果满足最左匹配原则,那么就可以按索引走,在范围查询之后的就不管了 如:
select * from ryc where a = '3' and b = '2' and c<7 复制代码
这种情况就满足了最左匹配原则的查询
select * from ryc where a > 3 and b = '2' and c<7 复制代码
这种情况就只有a能够查索引了,bc都需要全表扫描了
如果是order by排序的情况,那么又有一些不同
select * from ryc order by b,c,a limit 10; 复制代码
大家觉得这种情况能不能用到索引?

。
select * from ryc order by a limit 10; select * from ryc order by a,b limit 10; select * from ryc where a =1 order by b,c limit 10; 复制代码
这些情况是可以用到覆盖索引的,因为他实现了最左匹配原则,至于为什么,请大家思考一下
B+树
其实,B+树非常好理解,我去大佬哪边拿(读书人的事情)一张图片来康康(引用自https://baijiahao.baidu.com/s?id=1655665549235267594&wfr=spider&for=pc)
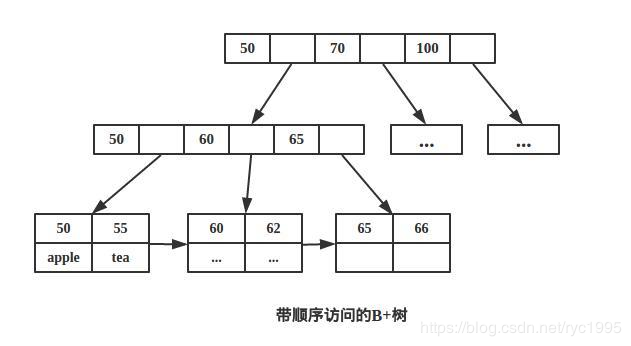
B+树最核心的特点:
- 只有叶子节点保存数据
- 多路非二叉
- 增加了相邻接点的指向指针
- B+树的非叶子节点的每一个关键字对应一个指针,而关键字则是子树的最大,或者最小值
通过这些特点,我们就能总结出B+树的优点
- B+树相比B树的存储效率更高 。B+树其实是多级索引,这种结构与Redis中跳跃表是非常的相似(以后会讲),最下一层是所有关键码的全集,因此可以把此层形成顺序的双链链表,正因为在B+树里面非叶层节点不需要存储额外的指向磁盘的指针,所以相比之前的B树,B+树存储效率更高。
- B+树的高度更小,也就是说B+树的检索效率更高
- B+树支持范围检索 ,因为最下方是链表,和分页查询简直是天作之和
- 插入和删除更为方便 ,其实流程和B树类似,但B+树里面,关键码的个数和子节点的个数是对等的,所以从记忆角度来说,B+树更方便记忆使用,而B树则需要时刻注意节点数和关键码的对应关系。
当然,相比于B树,其实B+树还是有一些缺点的,比如只有叶子节点才存放数据,所以不会出现那种 灵机一动 ,这也就意味着查找B+树,就必须到叶子节点才能返回结果。
4、InnoDB 索引实现
刚刚我们已经讲了一下B+树,在InnoDB 中,表数据文件本身就是按 B+树组织的一个索引结构,这棵树的叶点data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。
所以我们可以得出一个关键的信息:
InnoDB 要求表必须有主键,最好是一个自增的主键
因为 InnoDB 数据文件本身是一棵B+树,非单调的主键会造成在插入新记录时数据文件为了维持 B+Tree 的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。 如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置 ,当一页写满,就会自动开辟一个新的页。 InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址。换句话说, InnoDB 的所有辅助索引都引用主键作为 data 域 。 聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。(回表)
emmmm,这篇文章慢慢的写完了,在写文章的过程中,有些记忆模糊的地方也再次去查了一些资料,也引用了不少大佬令人眼前一亮的地方,如果各位有兴趣的话,可以加我微信,我会把我总结的一些思维导图分享出来,毕竟,知识越分享越有价值。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

