【JAVA程序员进阶之路】Redis基础知识两篇就满足(二)
大家好,我是南橘,从接触java到现在也有差不多两年时间了,两年时间,从一名连java有几种数据结构都不懂超级小白,到现在懂了一点点的进阶小白,学到了不少的东西。知识越分享越值钱,我这段时间总结(包括从别的大佬那边学习,引用)了一些平常学习和面试中的重点(自我认为),希望给大家带来一些帮助
这篇文章的出现,首先要感谢一个人 三太子敖丙 ,就是他的文章让我发现,原来Redis的知识如此的多姿多彩。恩恩,他的文章,我是期期都看
这是这篇文章的思维导图,因为用的是免费版的软件,所以有不少水印,需要原版的可以问我要

Redis篇,因为时间和篇幅的原因,并没有一次性写完,于是乎,分成了上下两篇,没有看过上半部分的小伙伴可以去看一下~
Redis基础知识两篇就满足(一)
一、缓存雪崩、击穿、穿透
这一次,从Redis最为人津津乐道(面试也经常常问)的缓存三崩坏来说起
缓存雪崩
顾名思义,大家应该都见过雪崩,南橘我更是远远地亲眼见过,那场景,颇有种天崩地裂的感觉,而对于数据库来说,缓存雪崩,也说得上是一种天崩地裂了。 同一时间Redis缓存大面积失效,那一瞬间Redis跟不存在一样,这个时候数据直接请求到数据库。你想想,缓存的意义就是减少DB,如果缓存没有了,大量的请求还不直接打爆数据库?
缓存雪崩如何出现的?
- 大量的缓存同时失效,可能是同时间生成,同时间到期
- 缓存同时被删除
- 缓存层出现了错误,不能正常工作了
解决办法:
- 1、批量网Redis存数据的时候,把每个KEY失效时间都增加随机值,保证不会同时失效
- 2、设置热点数据永不过期,有更新操作就更新缓存(但是这个方法不好,永不过期导致缓存大量堆积,很多缓存不一定有用)
- 3、Redis集群部署,将热点数据均匀分布在不同Redis库中也能避免全部失效,避免了Redis出现问题导致缓存雪崩
缓存击穿
有一个Key非常热点,在不停扛着大并发,大并发集中对这一点进行访问,当这个Key失效的瞬间、大量并发击穿缓存,直接访问数据库。
其实缓存击穿,真的算不上什么特别大的问题,毕竟不是每个公司都在同一个Key上都有那么大的热点,只需要设置好过期时间,稳定好Redis集群,缓存击穿不难避免。
解决办法:
- 1、设置热点数据永不过期
- 2、增加互斥锁【简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存】
在我的经验来看,设置互斥锁显然没有必要,一个热点永不过期就能解决的问题,为什么还要用到锁?这不是平白增加复杂度吗?也许在特殊场景能看到,但是对于我这个小白来说,仅仅能在各位大牛的博客里看到这个观点。
缓存穿透
从名字上来看,缓存击穿和缓存穿透很像,实际上页比较像,但是既然区分了出来,自然有一些不同的地方
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
但是,缓存穿透真正要防止的是黑客。
如果一个黑客每次故意查询一个在缓存内必然不存在的数据,导致每次请求都要去存储层去查询,这样缓存就失去了意义。如果在大流量下数据库可能挂掉,这也是缓存击穿。 解决办法:
- 1、增加参数校验
- 2、从网关层Nginx增加配置项,对单个IP每秒访问次数超出阈值的拉黑处理
- 3、Bloom Filter 能很好地防止缓存穿透、他的原理也很简单的就是利用高效的数据结构和算法快速判断出你这个Key是否在数据库,不存在直接return、存在就直接去DB刷新KV再return
利用布隆过滤器来防止缓存击穿,主要是通过将已存在的缓存放到布隆过滤器中,当黑客访问不存在的缓存时迅速返回避免缓存及DB挂掉。
至于什么是布隆过滤器
布隆过滤器本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
布隆过滤器是由 一个很长的bit数组和一系列哈希函数组成的。
数组的每个元素都只占1bit空间,并且每个元素只能为0或1。
布隆过滤器拥有k个哈希函数,当一个元素加入布隆过滤器时,会使用k个哈希函数对其进行k次计算,得到k个哈希值,并且根据得到的哈希值,在维数组中把对应下标的值置位1。
判断某个数是否在布隆过滤器中,就对该元素进行k次哈希计算,得到的值在位数组中判断每个元素是否都为1,如果每个元素都为1,就说明这个值在布隆过滤器中。
当插入的元素越来越多时,当一个不在布隆过滤器中的元素,经过同样规则的哈希计算之后,得到的值在位数组中查询,有可能这些位置因为其他的元素先被置1了。
所以布隆过滤器存在误判的情况,但是如果布隆过滤器判断某个元素不在布隆过滤器中,那么这个值就一定不在。
通过这个方法,就可以有效的防止黑客导致的缓存穿透了。
二、Redis集群的实现
1、传统的主从模式
其实不是很传统,只是我感觉所有的集群都有主从模式orz
主从模式的一个作用是备份数据,这样当一个节点损坏(指不可恢复的硬件损坏)时,数据因为有备份,可以方便恢复。 另一个作用是负载均衡,所有客户端都访问一个节点肯定会影响Redis工作效率,有了主从以后,查询操作就可以通过查询从节点来完成。
在主从模式中,一个Master可以有多个Slaves,默认配置下, master节点可以进行读和写,slave节点只能进行读操作,无法进行写操作 。
如果修改默认配置,可以让slave进行写,但是这毫无意义,因为 写入的数据不会同步给其他slave,同时,master节点如果修改了,slave上的数据回马上被覆盖 。
slave节点挂了不影响其他slave节点的读和master节点的读和写,重新启动后会将数据从master节点同步过来。master节点挂了以后,不影响slave节点的读,Redis将不再提供写服务,master节点启动后Redis将重新对外提供写服务。
所以,我们可以发现Redis的主从和Zookeeper的主从完全不一样! 它竟然不会选举!
这个缺点影响是很大的,尤其是对生产环境来说,是一刻都不能停止服务的,所以一般的生产坏境是不会单单只有主从模式的。所以有了下面的sentinel模式。
2、sentinel模式(哨兵模式)
哨兵模式要搭配主从模式来使用,主从不能自己选举,那我们就加一个哨兵,当sentinel发现master节点挂了以后,sentinel就会从slave中重新选举一个master。
哨兵的作用就是监控Redis系统的运行状况。它的功能包括以下两个。
(1)监控主服务器和从服务器是否正常运行。 (2)主服务器出现故障时自动将从服务器转换为主服务器。 复制代码
这不就皆大欢喜了吗?
哨兵的工作方式:
- 1、每个Sentinel(哨兵)进程以 每秒钟一次的 频率向整个集群中的Master主服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
- 2、如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)
- 3、如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有 Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态 当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认Master主服务器进入了 主观下线状 态(SDOWN), 则Master主服务器会被标记为 客观下线 (ODOWN)
- 4、在一般情况下, 每个 Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送 INFO 命令。 当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
- 5、若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
sentinel模式基本可以满足一般生产的需求,具备高可用性。但是当数据量过大到一台服务器存放不下的情况时,主从模式或sentinel模式就不能满足需求了,这个时候需要对存储的数据进行分片,将数据存储到多个Redis实例中,这就是cluster模式。
3、cluster模式
cluster的出现是为了解决单机Redis容量有限的问题,将Redis的数据根据一定的规则分配到多台机器。
Redis-Cluster采用无中心结构,它的特点如下:
-
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
-
节点的失效是通过集群中超过半数的节点检测失效时才生效。
-
客户端与redis节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
cluster可以说是sentinel和主从模式的结合体,通过cluster可以实现主从和master重选功能,所以如果配置三个副本三个分片的话,就需九六个Redis实例。 因为Redis的数据是根据一定规则分配到cluster的不同机器的,当数据量过大时,可以新增机器进行扩容, 这种模式适合数据量巨大的缓存要求,当数据量不是很大使用sentinel即可。
引用一张大佬的图片来直观展现一下什么是 Redis-Cluster
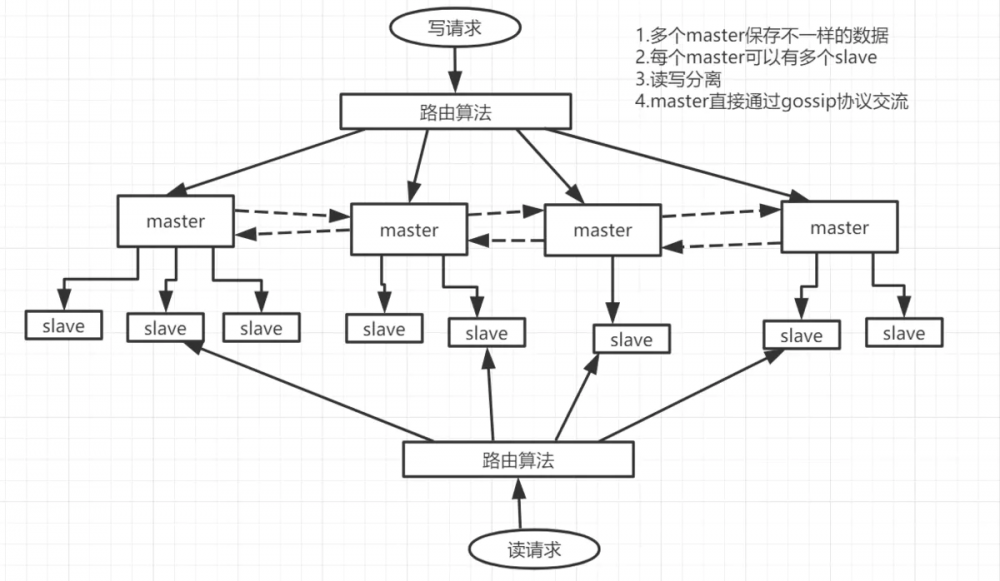
每个请求访问Redis-Cluster集群的时候,都会进行一个路由,路由可以通过Hash(也可以用别的)来进行随机分片,但是如果完全hash的话很可能导致分片们旱的旱死,涝的涝死。,所以,提出了**一致性哈希(自动缓存迁移)+虚拟节点(自动负载均衡)**的方法来解决问题
具体内容大家可以看看这篇文章,写的比较详细,看的也很过瘾
www.jianshu.com/p/49c9e03ee… 关于redis的几件小事(十)redis cluster模式
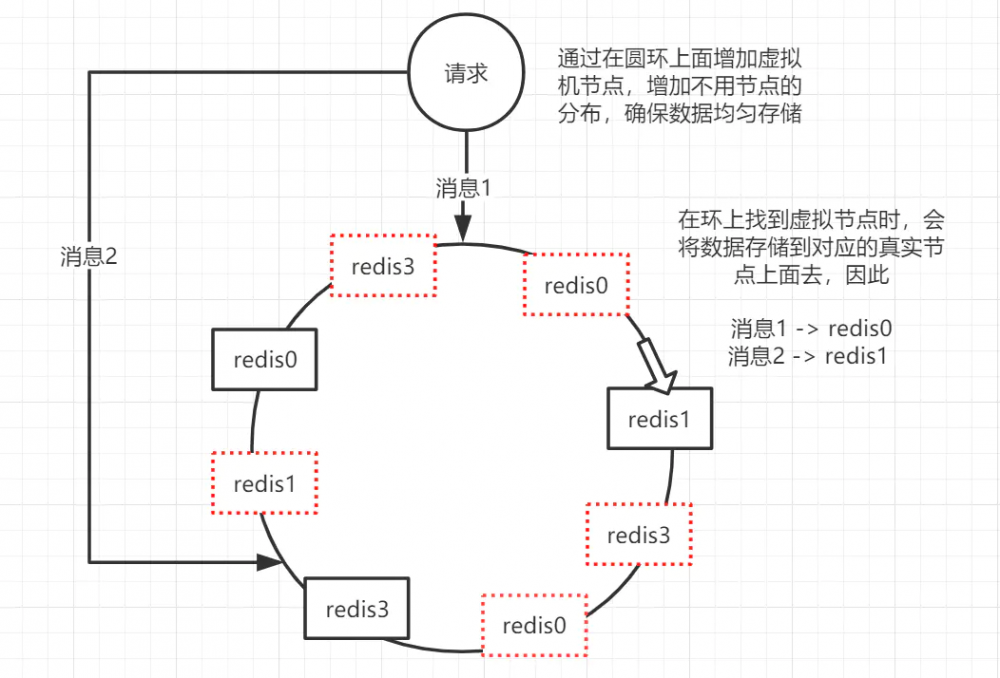
一致性哈希的原理 :将所有master node落在一个圆环上面,然后,有一个key过来之后。同样就是hash值,然后会用hash值在圆环对应的各个点上(每个点都有一个hash值)去对比,看hash值落在那个位置,落在圆环上面以后,就会顺时针旋转去寻找距离自己最近的一个节点,数据的存储于读取都在该节点进行。
一致性哈希的优势 :保证了任何一个master宕机,只会影响之前在那个master上面的数据,因为照着顺时针走,全部在之前的master上面找不到了,master也宕机了,就会继续顺着顺时针走到下一个master节点去。这样就只会有一部分数据丢失。
三、内存淘汰机制
既然Redis能储存数据,自然也就要删除多余的数据,不然,空间都被占满了,新的内容放在哪里?聪明的程序员提出了三个办法解决Redis的内存问题。
- 1、定时删除
- 2、惰性删除——查询后如果过期就不返回、过期则删除。这种情况容易出现很多冗余数据导致占用大量空间
1、定时删除
创建一个定时器,当key设置有过期时间,且过期时间到达时,由定时器任务立即执行对键的删除操作,默认100ms就随机抽一些key判断是否过期,过期的话就删除,用处理器性能换取存储空间( 拿时间换空间 )
-
优点:节约内存,到时就删除,快速释放掉不必要的内存占用
-
缺点:CPU压力很大,无论CPU此时负载量多高,均占用CPU,会影响redis服务器响应时间和指令吞吐量
2、惰性删除
当Redis中的数据到了过期时间,我们先不做处理。等下次访问该数据时进行一次判断,如果未过期,就正常返回,如果发现数据已过期,立刻删除,然后返回不存在,用存储空间换取处理器性能( 拿空间换时间)
-
优点:节约CPU性能,发现必须删除的时候才删除
-
缺点:内存压力很大,出现长期占用内存的数据
不知道大家不知道发现了没有,大部分的算法,不是时间换空间,就是空间换时间。刚刚发现这个秘密的我简直惊呆了,这就是人类的终极奥秘之一了,只要我们知道这个诀窍,就能解决大部分的问题。
3、淘汰机制
在Redis的redis.config文件中还可通过搜索maxmemory-policy来设置淘汰机制
noeviction:当内存使用达到阈值的时候,所有引起申请内存的命令会报错。 allkeys-lru:在主键空间中,优先移除最近未使用的key。 volatile-lru:在设置了过期时间的键空间中,优先移除最近未使用的key。 allkeys-random:在主键空间中,随机移除某个key。 volatile-random:在设置了过期时间的键空间中,随机移除某个key。 volatile-ttl:在设置了过期时间的键空间中,具有更早过期时间的key优先移除。 复制代码
正文到此结束
- 本文标签: 自动缓存 Sentinel db 压力 redis key src 本质 node 进程 数据 实例 同步 cache 一致性 协议 数据库 黑客 DOM 总结 处理器 高可用 部署 服务器 UI 程序员 锁 免费 Master rand 备份 负载均衡 配置 空间 volatile 文章 希望 并发 Nginx https zookeeper 时间 参数 博客 IO 缓存 java struct Slaves 需求 软件 删除 图片 一致性哈希 ip 集群 代码 list http
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

