G1理论基础与经验分享
关于G1收集器的收集过程,看过一些博客和书,基本上十有八九都说的不一样,如果要确定哪个是正确的还是得去看实现代码。当然我不打算去学C语言看代码了,接下来就结合自己的理解和资料来介绍G1收集器收集过程,力求做到初次接触G1也能看明白。
G1可以说是个里程碑式的产品,从提出到正式商业使用几乎用了差不多10年,与之前的垃圾收集器相比有着明显的区别。比如它可以进行新时代和老年代的收集,而其他的收集器都是新生代收集器 + 老年代收集器的组合;同时对堆的划分与传统的堆划分也有着明显的区别;
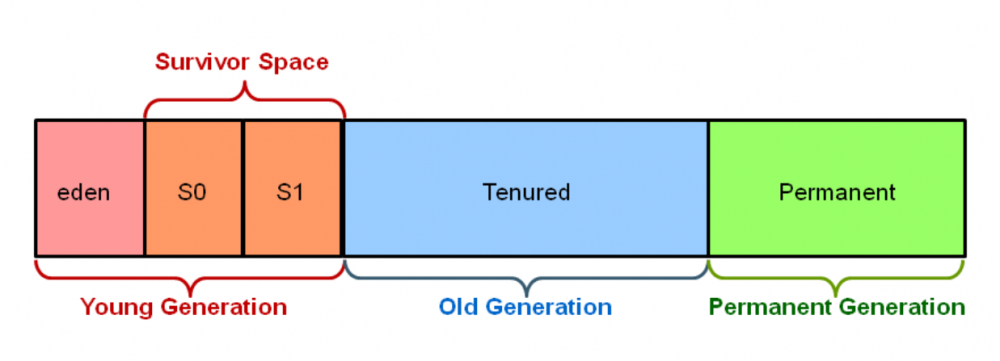
如果忽略掉永久代的话,可以将堆划分为新生代的1个Eden + 2 个Survivor以及一大块老年代然后进行分代收集,如下图所示:
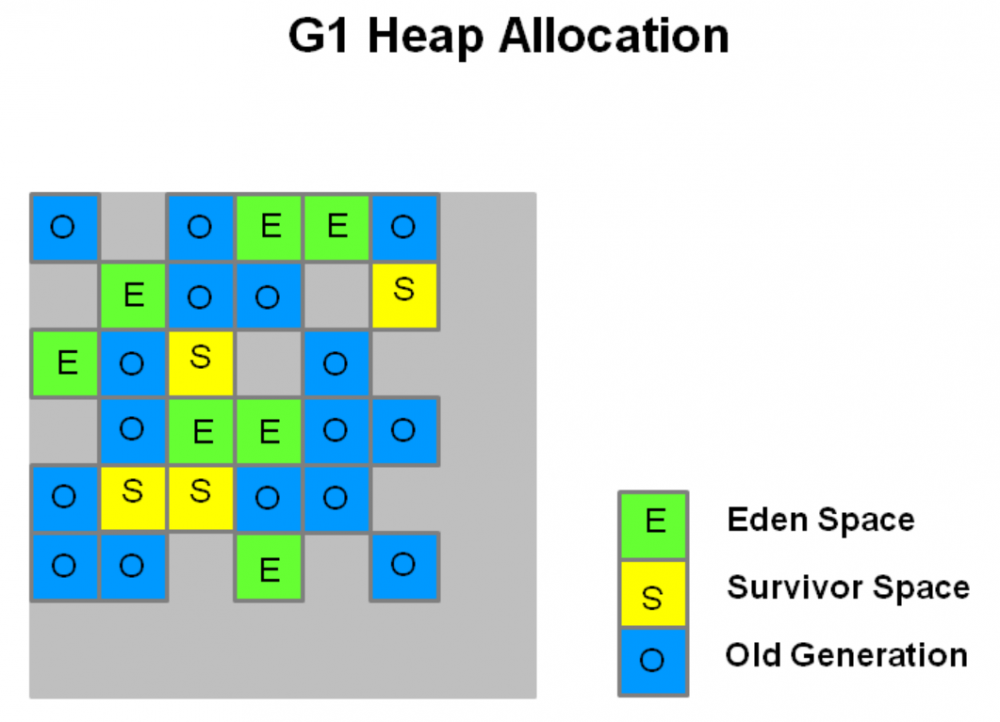
再看G1收集器,则是将整个大堆划分为很多大小相同的region,region大小为2的n次幂,而且不要求region间是空间上连续的。每个Region则可以扮演eden、survivor、old三种角色之一。其实还有humonous区,其专门用来存储大对象,大对象定义为大小达到region一半大小的对象,因为G1会把它当做老年代,所以这里放到老年代一起了。另外每个region扮演的角色不是一直不变的。
到这就可以解释为什么取名叫G1收集器了:收集器根据用户指定的停顿时间来制定回收计划,简单来说就是,对各个区域的回收价值排序收集,比如有的region中对象存活的极少,那么该region肯定排的非常靠前而优先被收集。因为收集这块region只需要移动很少的对象,那么就只需要很少的时间,同时还能释放大量的内存,必然优先收集该区域。这就是G1(Garbage First)名字的由来。
G1只有YongGC(YGC)和mixed gc,YGC用于收集全部的新生代,而mixed gc则是收集全部的年轻代和收益高的老年代。当发生Full GC则会使用单线程进行GC,非常耗时,应该极力去避免Full GC的发生。下面通过介绍G1的回收过程来阐述使用G1的相比其他收集器的优势。
1.2. YongGC
具体的GC过程不会说的太细,否则得写几万字,因为还要介绍记忆集,卡表等。
收集后如下:
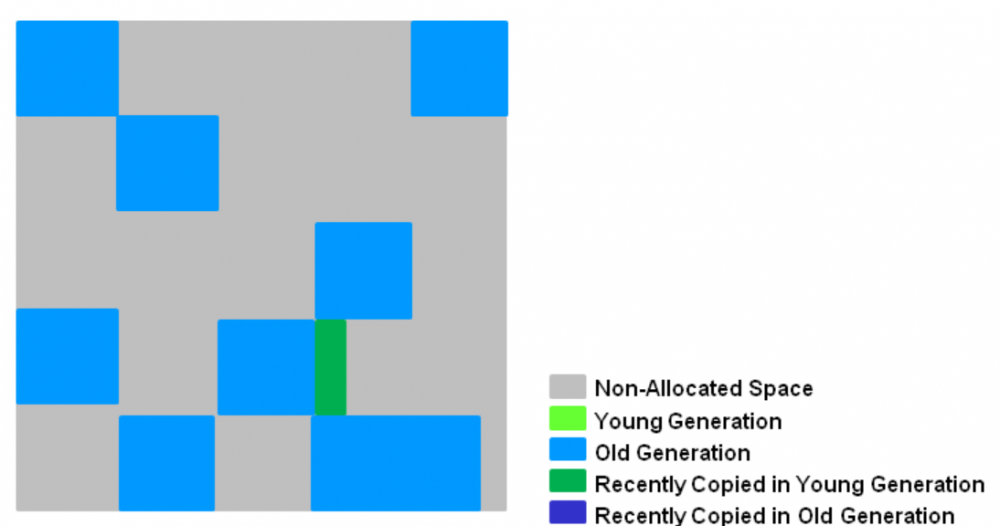
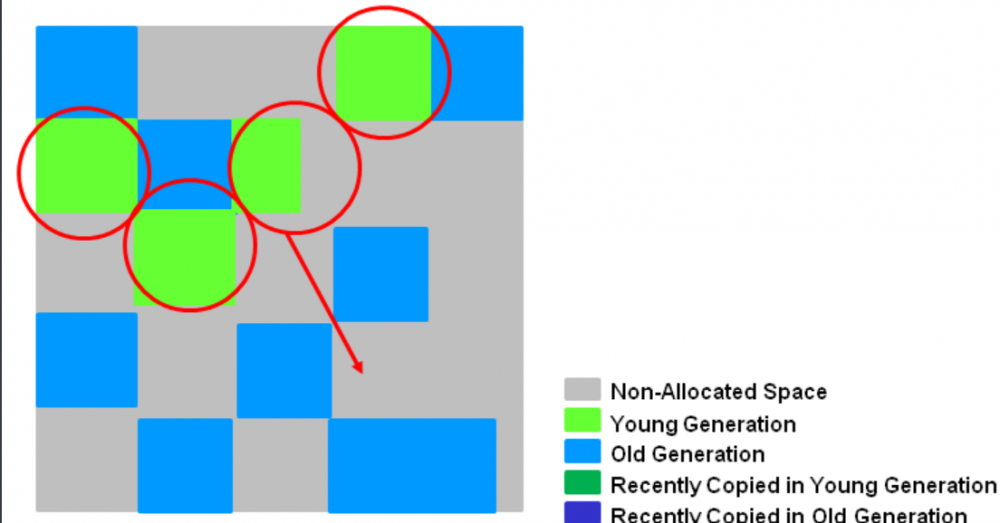
如图所示,年轻代被挑选出来后,收集的时候会将存活对象移动到一块 空的region 中去,然后再一次性清理原来的内存空间释放内存,需要强调的是YGC针对的是整个新生代,很多情况下原来Eden区域有个1-2G,一次YGC后全部清零,而survivor区域内存占用会上涨一些,毕竟绝大部分对象都是朝生夕死,所以YGC效率还是很高的。以下有几点需要强调:
- 基本上Eden区域全部清零,1666M -> 0;
- 新生代存活的对象都会移动到一块或者多块空的region区,之后将这块区域标记为survivor区;但是survivor中的对象如果达到年龄后则会进入到老年代, 如果空间不足,eden区域内存活对象也是会进入到老年代的;
- 大对象会进入到humogous,收集器会把它当做老年代来看;
- YGC会stop the world(STW),但是一般来说由于YGC效率高(同时使用多线程同时收集),所以STW的时间很短。
1.3. mixed gc
mixed gc(混合收集)是G1独有的gc方式,mixed gc会收集全部新生代和收益高的老年代。mixed gc主要分为两步:
- 全局并发标记( global concurrent marking),为mixed gc提供标记服务;
- 混合垃圾回收,包含拷贝存活对象并清理内存;
而全局并发标记又分为四步:
-
初始标记(包含了根区域扫描);
-
并发标记;
-
重新标记;
-
清理;
初始标记阶段 : 标记了从GC Roots开始直接可达的根对象, 需要STW。混合收集中的初始标记和新生代的初始标记几乎一样,所以经常会看到文章说与YGC的时候同步完成的,所以G1收集器在这个阶段实际并没有额外的停顿。实际上混合收集的初始标记是借用了新生代收集的结果,即新生代垃圾回收后的新生代Survivor分区作为根,所以混合收集一定发生在新生代回收之后,且不需要再进行一次初始标记。在gc日志中表现为
GC pause (young)(inital-mark). 并发标记阶段 :当YGC执行结束之后,如果发现满足并发标记的条件,并发线程就开始进行并发标记。根据新生代的Survivor分区以及老生代的RSet开始并发标记。时机是在YGC后,只有达到InitiatingHeapOccupancyPercent阈值后,才会触发并发标记。InitiatingHeapOccupancyPercent默认值是45,表示的是当已经分配的内存加上即将分配的内存超过内存总容量的45%就可以开始并发标记。并发标记会对所有的分区进行标记。这个阶段并不需要STW。
小tips:如果你发现收集完后占用的堆内存达到了总的堆内存的40%以后,下次可能就会发生mixed gc了,如果发现堆内存2G,下次成了1.3G,很可能就是发生了mixed gc,频繁的mixed gc那肯定是有问题的。关于如何查看日志中有效信息这会在后面具体介绍。
重新标记阶段 :用来标记那些在并发标记阶段引用发生变化的对象,需要对用户线程做个短暂的STW。
清理阶段 :在该阶段也是需要STW的。主要统计存活对象,统计的结果将会用来排序分区region,以用于下一次的Collect Set(简称CSet,见该节最后的介绍)的选择;需要把新分配的对象,即不在本次并发标记范围内的新分配对象,都视为活跃对象。
该阶段比较容易引起误解地方在于,清理操作并不会清理垃圾对象,也不会执行存活对象的拷贝。也就是说,在极端情况下,该阶段结束之后,JVM的内存使用情况毫无变化。
混合垃圾回收阶段: 混合回收实际上与YGC是一样的, 第一个步骤是从分区中选出若干个分区进行回收,这些被选中的分区称为Collect Set(简称CSet);第二个步骤是把这些分区中存活的对象复制到空闲的分区中去,同时把这些已经被回收的分区放到空闲分区列表中。在日志中标记为[GC pause (mixed)], 即年轻代和老年代会被同时收集。见下图:
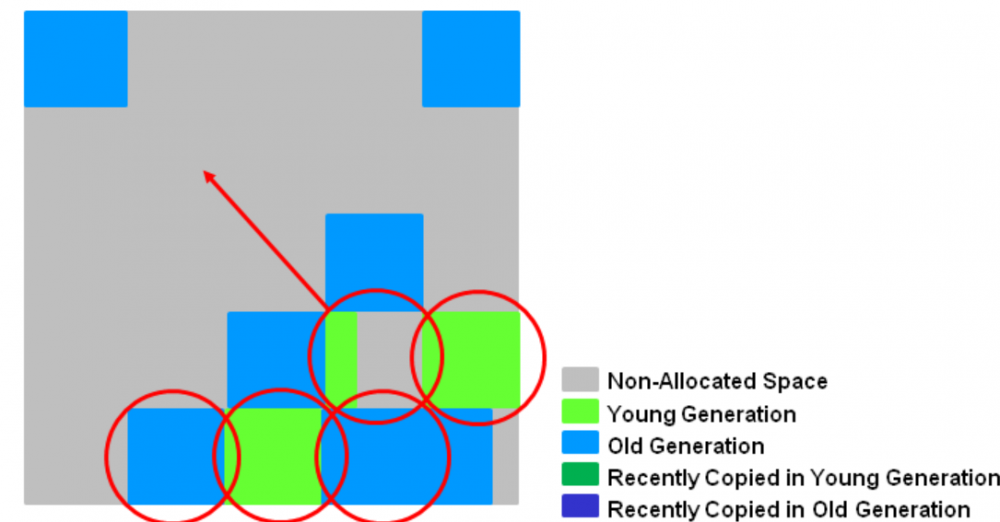
回收完之后就成了下面这个样子:

CSet:收集集合(CSet) 是一组可被回收的分区的集合。 在CSet中存活的数据会在GC过程中被移动到另一个可用分区,CSet中的分区可以来自eden空间、survivor空间、或者老年代。
分代G1模式下选择CSet有两种子模式, 分别对应Young GC和Mixed GC:
- Young GC: CSet就是所有年轻代里面的Region;
- Mixed GC: CSet是所有年轻代里的Region加上在全局并发标记阶段标记出来的收益高的Region;
1.4. 扩展
1.4.1. 记忆集和卡表
说到G1收集器不得不说记忆集(Remembered Set, 简称RSet)和卡表(Card Table),很多文章都会穿插在GC过程中来说,如果不了解可能会看不下去,其实不介绍这两个数据结构更容易了解GC流程。
考虑这样一个问题:YGC的时候针对的是全部新生代,那么选GC Roots的时候,因为存在跨代引用的问题而不好确定哪些是roots,其实很多root是在老年代。但是老年代那么大,总不能每次都花那么多时间扫描整个老年代,这就相当于扫描了整个堆了,因为新生代肯定是要全部扫描的。因此在新生代引入了记忆集RSet这样一个数据结构,用来记录哪些Region中的对象指向了当前分区中的对象(记忆集是一种用于记录从 非收集区域指向收集区域 的指针集合的抽象数据结构,用以避免把整个老年代加进GC Roots扫描范围),下面通过简单的画图来理解。
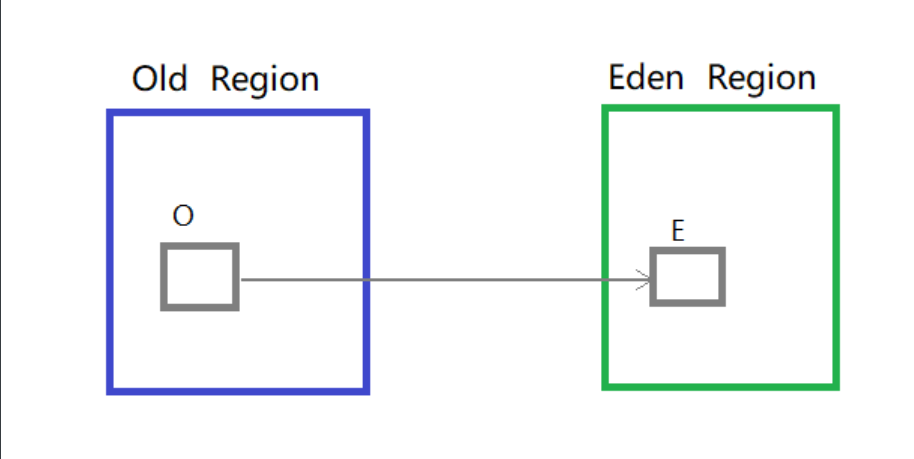
容易知道的是如果忽略老年代作为根而不去扫描的话,显然对象E就是垃圾对象,这就会导致误判;但是也不能去扫描全部的老年代,所以在该Eden Region中使用的RSet,记录了Old Region中有对象指向了本区域中的对象。说到这可能猜到了RSet是怎样的数据结构了。没错,就是哈希表,key为别的Region的起始地址,value则是一个集合,集合中的元素地址(其实是卡表中元素的下标index)。
一个卡表会将一个分区Region划分为固定大小的连续区域,每个区域又称为卡。卡表通常为字节数组,由卡的索引(数组下标)来标识每个分区的地址。默认情况下每个卡都未被引用。当一个卡被引用的时候,则将该卡地址对应的数组下标的值标记为0。同时根据需要在RSet中记录下来,比如O指向了E,那么在该Eden区的RSet中会记录O在Old区域中卡表的索引,看下面的图可能会明白我说的啥。
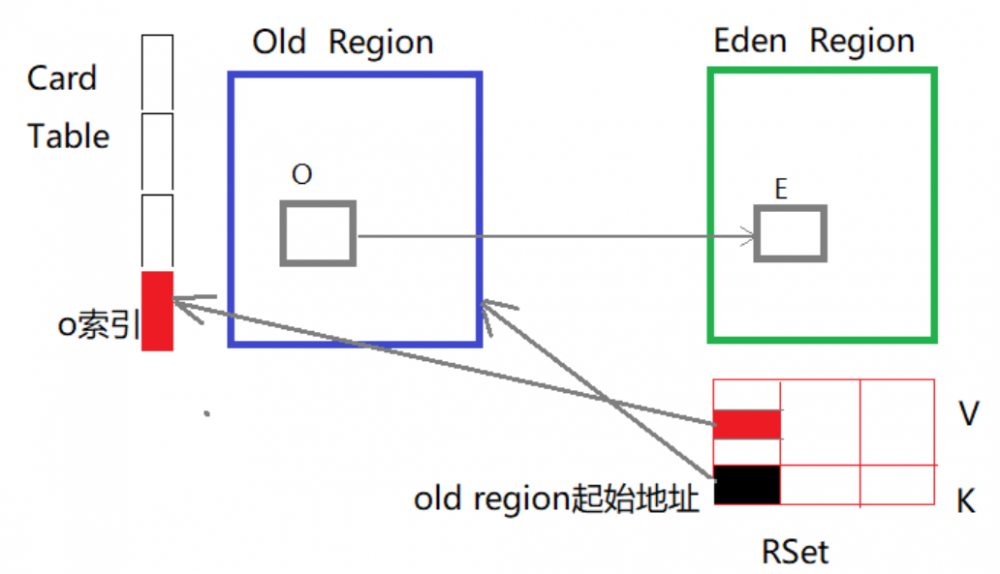
说明: 比较权威的书和部分文章写的是记忆集是一种抽象,卡表则是其实现,两者的关系就像Map和HashMap,但由于上面这种方式对于我来说更易于理解,所以就介绍了上面这种方式。
1.4.2. STAB和TAMS
再说第二个问题:在并发标记阶段如何保证收集线程与用户线程互不干扰地运行?
首先 要解决的是用户线程改变对象引用关系时,必须保证其不能打破原本的对象图结构,导致标记结果出现错误。
G1就是采用了SATB(Snapshot-At-The-Beginning,原始快照)算法来实现的:SATB可以理解成在GC开始之前对堆内存里的对象做一次快照,此时活的对象就认为是活的,从而形成一个对象图。在GC收集的时候,新生代的对象也认为是活的对象,除此之外其他不可达的对象都认为是垃圾对象。SATB算法主要分成以下三个步骤:
- 在开始标记的时候生成一个快照图,标记存活对象;
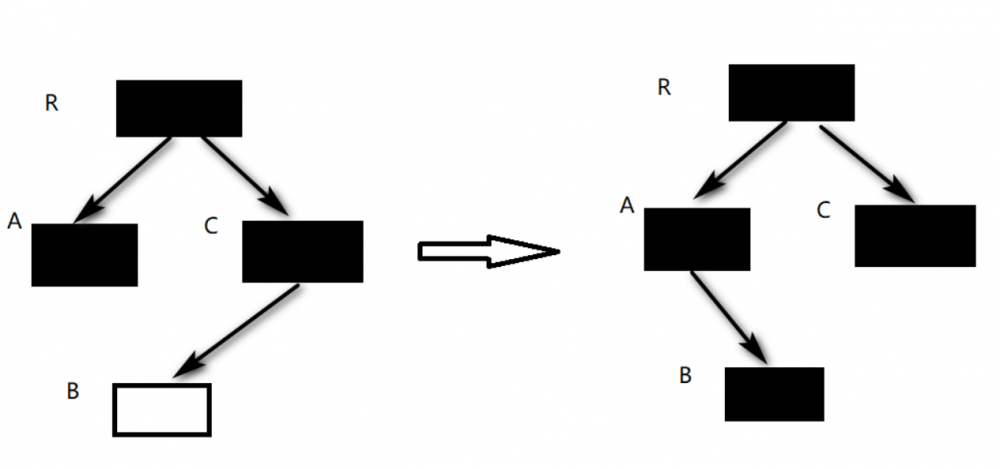
- 在并发标记的时候所有被改变的对象入队(在write barrier里把所有旧的引用所指向的对象都变成非白的);
- 可能存在浮动垃圾,将在下次被收集;
关于步骤2可以这样理解,假设存在这样的关系A.b = B, C.b=null(此时B是白色的),并发标记中发生了这样的变化A.b=null,C.b=B。 那么这个时候由于旧的引用A所指向的对象是B,所以将B标记为非白。标记最后如果对象为白色那就是 垃圾对象 ,此外还有灰色和黑色(黑色是存活对象,灰色可能是垃圾对象或者不是),这属于三色标记算法内容,避免越说越糊涂就不多介绍(SATB其实依赖三色标记),下图简单展示了变化过程。
其次 要解决的问题是,前面说了并发过程新分配的对象认为是存活对象,那么 如何找到GC过程中新分配的对象 呢?
每个region记录着两个top-at-mark-start(TAMS指针, 分别为prev TAMS和next TAMS。在TAMS以上的对象就是新分配的, 因而被视为隐式marked。通过这种方式我们就找到了在GC过程中新分配的对象,并把这些对象认为是活的对象。
最后 ,解决了对象在GC过程中分配的问题,那么在GC过程中 引用发生变化的问题 怎么解决呢?G1给出的解决办法是通过Write Barrier。 Write Barrier就是对引用字段进行赋值做了额外处理,这个额外处理前面也说了,其实就是所有旧的引用所指向的对象都变成非白的,这样就可以了解到哪些引用对象发生了什么样的变化
1.5. G1相比CMS的优势
- G1在压缩空间方面有优势;
- G1通过将内存空间分成区域 (Region) 的方式避免内存碎片问题;
- Eden、Survivor、Old区不再固定, 在内存使用效率上来说更灵活;
- G1可以通过设置预期停顿时间(Pause Time) 来控制垃圾收集时间,避免应用雪崩现象G1在回收内存后会马上同时做合并空闲内存的工作,而CMS默认是在STW(stop the world) 的时候做;
- G1会在Young GC中使用, 而CMS只能在O区使用
2. G1日志解读与经验分享
2.1. 日志解读
先看YGC日志的样子 GC pause (G1 Evacuation Pause) (young) :
class space used 5944K, capacity 6094K, committed 6144K, reserved 1048576K
2020-03-23T17:32:14.984+0800: 9.925: [GC pause (G1 Evacuation Pause) (young)2020-03-23T17:32:15.005+0800: 9.947: [SoftReference, 0 refs, 0.0000722 secs]2020-03-23T17:32:15.005+0800: 9.947: [WeakReference, 71 refs, 0.0000329 secs]2020-03-23T17:32:15.005+0800: 9.947: [FinalReference, 1660 refs, 0.0018747 secs]2020-03-23T17:32:15.007+0800: 9.949: [PhantomReference, 0 refs, 3 refs, 0.0000193 secs]2020-03-23T17:32:15.007+0800: 9.949: [JNI Weak Reference, 0.0000216 secs], 0.0252556 secs]
[Parallel Time: 20.4 ms, GC Workers: 23]
[GC Worker Start (ms): Min: 9925.6, Avg: 9925.7, Max: 9925.8, Diff: 0.2]
[Ext Root Scanning (ms): Min: 0.9, Avg: 2.3, Max: 10.1, Diff: 9.2, Sum: 53.9]
[Update RS (ms): Min: 0.0, Avg: 1.2, Max: 2.8, Diff: 2.8, Sum: 27.9]
[Processed Buffers: Min: 0, Avg: 3.3, Max: 13, Diff: 13, Sum: 75]
[Scan RS (ms): Min: 0.0, Avg: 0.1, Max: 0.5, Diff: 0.5, Sum: 2.9]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.7, Max: 4.3, Diff: 4.3, Sum: 15.0]
[Object Copy (ms): Min: 8.7, Avg: 14.6, Max: 18.6, Diff: 10.0, Sum: 336.1]
[Termination (ms): Min: 0.0, Avg: 1.1, Max: 1.4, Diff: 1.4, Sum: 25.4]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 23]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.5]
[GC Worker Total (ms): Min: 19.9, Avg: 20.1, Max: 20.2, Diff: 0.3, Sum: 461.7]
[GC Worker End (ms): Min: 9945.8, Avg: 9945.8, Max: 9945.8, Diff: 0.1]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.4 ms]
[Other: 4.4 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 2.6 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.3 ms]
[Humongous Register: 0.1 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.7 ms]
[Eden: 284.0M(284.0M)->0.0B(310.0M) Survivors: 20.0M->38.0M Heap: 336.1M(4096.0M)->94.7M(4096.0M)]
Heap after GC invocations=8 (full 0):
garbage-first heap total 4194304K, used 96923K [0x00000006c0000000, 0x00000006c0204000, 0x00000007c0000000)
region size 2048K, 19 young (38912K), 19 survivors (38912K)
Metaspace used 49410K, capacity 49926K, committed 50428K, reserved 1093632K
class space used 5944K, capacity 6094K, committed 6144K, reserved 1048576K
}
[Times: user=0.38 sys=0.06, real=0.02 secs]
复制代码
YGC的详细过程就不说了,只说个人认为关键的日志信息:
[Object Copy (ms): Min: 8.7, Avg: 14.6, Max: 18.6, Diff: 10.0, Sum: 336.1] [Times: user=0.38 sys=0.06, real=0.02 secs] 复制代码
这两行表示拷贝对象花费的时间和耗时,主要看平均时间 Avg 和耗时 real 。如果你发现YGC耗时比较长,特别要留意这两行信息,比如 real=0.56 secs;Object Copy (ms): Avg: 501 那你就知道是对象复制花费了太多时间,但是新生代基本都是招生夕死,那么为什么还有那么多对象存活呢?接下来就需要根据自己的业务具体分析了,后面会结合我们项目遇到过的问题来进行分析。
[Eden: 284.0M(284.0M)->0.0B(310.0M) Survivors: 20.0M->38.0M Heap: 336.1M(4096.0M)->94.7M(4096.0M)] 复制代码
这行表示了内存回收的情况,可以看到的是 Eden 区域是全部会被回收的,幸存区涨了18M,最后对内存情况是从回收前的336.1M到回收后的94.7M。如果你发现间歇性的幸存区域从较小的内存占用,回收后占用飙升,那很可能就有问题了,也即是存在大量对象存活了。当然如果回收后堆内存还是一直上涨,比如我们这里最大对内存是4G,如果回收后一直飙到了2000M(一般是占用45%左右)那你可能就要分析下是否正常了,比如是否经常有大对象申请内存,大对象进入了老年代而没有得到回收导致一直上升。不过一般这时会进行 mixed gc 了,具体的后面会分析遇到的一些问题。
再来看 mixed gc ,其实是和YGC分析是很类似的,由于全局并发标记中的初始标记是伴随着YGC,所以在这一阶段看到的其实是YGC内容
2020-03-24T19:34:12.416+0800: 7388.991: [GC pause (G1 Evacuation Pause) (young) (initial-mark)2020-03-24T19:34:12.447+0800: 7389.022: [SoftReference, 0 refs, 0.0000844 secs]2020-03-24T19:34:12.447+0800: 7389.022: [WeakReference, 24 refs, 0.0000157 secs]2020-03-24T19:34:12.447+0800: 7389.022: [FinalReference, 20 refs, 0.0000212 secs]2020-03-24T19:34:12.447+0800: 7389.022: [PhantomReference, 0 refs, 0 refs, 0.0000098 secs]2020-03-24T19:34:12.447+0800: 7389.022: [JNI Weak Reference, 0.0000400 secs], 0.0336560 secs]
[Parallel Time: 28.3 ms, GC Workers: 18]
[GC Worker Start (ms): Min: 7388993.6, Avg: 7388994.1, Max: 7388994.7, Diff: 1.2]
... 内容同YGC
2020-03-24T19:34:12.450+0800: 7389.025: [GC concurrent-root-region-scan-start]
2020-03-24T19:34:12.450+0800: 7389.025: Total time for which application threads were stopped: 0.0366523 seconds, Stopping threads took: 0.0006589 seconds
2020-03-24T19:34:12.461+0800: 7389.036: [GC concurrent-root-region-scan-end, 0.0111133 secs]
2020-03-24T19:34:12.461+0800: 7389.036: [GC concurrent-mark-start]
2020-03-24T19:34:12.917+0800: 7389.493: [GC concurrent-mark-end, 0.4565315 secs]
2020-03-24T19:34:12.919+0800: 7389.494: [GC remark 2020-03-24T19:34:12.919+0800: 7389.494: [Finalize Marking, 0.0016538 secs] 2020-03-24T19:34:12.920+0800: 7389.496: [GC ref-proc2020-03-24T19:34:12.920+0800: 7389.496: [SoftReference, 2129 refs, 0.0008546 secs]2020-03-24T19:34:12.921+0800: 7389.497: [WeakReference, 1891 refs, 0.0006409 secs]2020-03-24T19:34:12.922+0800: 7389.497: [FinalReference, 947 refs, 0.0009644 secs]2020-03-24T19:34:12.923+0800: 7389.498: [PhantomReference, 2 refs, 279 refs, 0.0002176 secs]2020-03-24T19:34:12.923+0800: 7389.498: [JNI Weak Reference, 0.0000991 secs], 0.0030448 secs] 2020-03-24T19:34:12.923+0800: 7389.499: [Unloading, 0.0516170 secs], 0.0587406 secs]
[Times: user=0.20 sys=0.67, real=0.06 secs]
2020-03-24T19:34:12.978+0800: 7389.553: Total time for which application threads were stopped: 0.0604210 seconds, Stopping threads took: 0.0002143 seconds
2020-03-24T19:34:12.979+0800: 7389.554: [GC cleanup 1993M->1296M(4096M), 0.0411176 secs]
[Times: user=0.04 sys=0.31, real=0.05 secs]
2020-03-24T19:34:13.020+0800: 7389.596: Total time for which application threads were stopped: 0.0426097 seconds, Stopping threads took: 0.0001096 seconds
2020-03-24T19:34:13.020+0800: 7389.596: [GC concurrent-cleanup-start]
2020-03-24T19:34:13.021+0800: 7389.597: [GC concurrent-cleanup-end, 0.0009866 secs]
2020-03-24T19:36:25.421+0800: 7521.996: [GC pause (G1 Evacuation Pause) (mixed)2020-03-24T19:36:25.438+0800: 7522.013: [SoftReference, 0 refs, 0.0000595 secs]2020-03-24T19:36:25.438+0800: 7522.013: [WeakReference, 45 refs, 0.0000194 secs]2020-03-24T19:36:25.438+0800: 7522.013: [FinalReference, 0 refs, 0.0000086 secs]2020-03-24T19:36:25.438+0800: 7522.013: [PhantomReference, 0 refs, 5 refs, 0.0000110 secs]2020-03-24T19:36:25.438+0800: 7522.013: [JNI Weak Reference, 0.0000482 secs], 0.0193059 secs]
[Parallel Time: 13.0 ms, GC Workers: 18]
[GC Worker Start (ms): Min: 7521999.3, Avg: 7521999.7, Max: 7522000.2, Diff: 0.9]
... 内容同YGC
复制代码
需要注意的是 GC pause (G1 Evacuation Pause) (young) (initial-mark)和GC pause (G1 Evacuation Pause) (mixed) 之间可能会穿插YGC,这两段的内容和YGC是一样的所以不需要解释了。关于 mixed gc 的步骤从日志信息里面很容易读出来,比如初始标记 GC pause (G1 Evacuation Pause) (young) (initial-mark) , 根Region扫描,并发标记等,对着 1.3的步骤介绍很容易看明白。
通常来说当某次回收后(大部分是YGC)堆内存占用达到45%左右,后面如果没降下去那很快就会进行 mixed gc 来整理老年代了。如果程序正常的话 mixed gc 频率应该是很低的,我们的项目可能还有点问题,但是一般也就30分钟一次。如果你的项目出现的频率很高,比如1-5分钟一次,那你就可能需要考虑是否出现了问题。频繁的 mixed gc 很可能说明了老年代内存得不到释放,同时可能还在增加,可能最后内存回收的速度跟不上分配的速度那就要 full gc 了,动不动就会十几秒,而且会不断进行下去,由于 full gc 是单线程STW的,此时服务基本就不可用了。所以 full gc 是要极力去避免的。
2.2. 一些参数介绍与重要提示
-XX:+CrashOnOutOfMemoryError 如果启用了此选项,当出现内存不足错误时,JVM将崩溃并产生文本和二进制崩溃文件(如果启用了核心文件),jdk8加的。 -XX:GCLogFileSize=xxxxxxxxx GC日志文件大小上限 -XX:NumberOfGCLogFiles=100 GC日志文件数量上限 -XX:+HeapDumpOnOutOfMemoryError 内存溢出的时候dump文件 -XX:InitialHeapSize=4294967296 初始对内存大小 -XX:MaxDirectMemorySize=805306368 最大直接内存大小 -XX:MaxHeapSize=4294967296 最大堆内存大小 -XX:MaxGCPauseMillis=200 GC时候STW最大停顿时间 -XX:+PrintGCDateStamps 打印GC时间(当前时间,比如2020-03-23T17:33:07.939+0800) -XX:+PrintGCDetails 输出GC详细日志 -XX:+PrintGCTimeStamps 打印GC时间(jvm启动直到垃圾收集发生所经历的时间,比如63表示经历了64秒) -XX:+UseG1GC 使用G1收集器 -XX:G1HeapRegionSize=n 每个Region的大小 -G1HeapWastePercent 在global concurrent marking结束之后,我们可以知道old generegions中有多少空间要被回收,在每次YGC之后和再次发生Mixed GC之前,会检查垃圾占比是否达到此参数,只有达到了,下次才会发生Mixed GC -G1MixedGCLiveThresholdPercent old generation region中的存活对象的占比,只有在此参数之下,才会被选入CSet -G1MixedGCCountTarget 一次global concurrent marking之后,最多执行MixedGC的次数 复制代码
写参数的时候记得初始对内存和最大堆内存要一样,以避免每次垃圾回收完成后JVM重新分配内存,如果不一致很可能会导致full gc问题。
使用的G1收集器,不要去指定新生代(-Xmn)和老年代的大小,让收集器动态调整即可。否则可能带来下面两个问题
- G1将不再考虑暂停时间目标。因此,从本质上讲,设置年轻一代的大小会阻碍暂停时间目标的实现;
- G1不再能够根据需要扩展和收缩年轻一代的空间。因为大小是固定的,所以不能改变大小;
通过 -XX:MaxGCPauseMillis=x 可以设置启动应用程序暂停的时间,G1在运行的时候会根据这个参数选择CSet来满足响应时间的设置。一般情况下这个值设置到100ms或者200ms都是可以的(不同情况下会不一样),但如果设置成50ms就不太合理。暂停时间设置的太短,就会导致出现G1跟不上垃圾产生的速度。最终退化成Full GC。所以对这个参数的调优是一个持续的过程,逐步调整到最佳状态。对于如何设置官方有个tips:时间小于等于程序响应客户端的时间的10%,比如http服务响应浏览器的时间一般就1000ms,那么可以设置停顿时间是100ms,当然具体的还得去调试看看。记住:暂停时间是一个目标,并不能保证总是能达到。
最后需要注意是否有 Evacuation Failure , full x ,这都是不应该出现的,出现了要立即解决掉。
2.3. 经验分享
2.3.1. Full GC经验分享
但运维人员通知了项目不停 full gc 后,首先登机器dump文件,然后重启机器暂时保住线上恢复,然后将 dump文件发送到本机使用Mat进行分析。
1.dump文件:
- 命令: jmap -dump:format=b,file=./myfile 324576
- myfile为dump的文件名,324576为pid
关于jmap还有两个实用的命令:
1. jmap -histo:live pid 查看存活对象分布情况(可能会触发full gc不要在线上使用,不加live可以,加了live会强制执行一次full gc);
2. jmap -heap pid 查看heap参数,使用情况等;
复制代码
2.dump文件下载到本地:
- 命令:scp -r ./myfile tom@192.168.25.128: /home/tom/mydir - 下载完之后给文件名加个.hprof后缀(或者dump的时候就加上),因为mat打开dump文件的时候只选择hprof文件。 复制代码
3.下载MAT并进行分析:
- 下载地址: https://www.eclipse.org/mat/downloads.php, 注意选国内镜像; - 下载完之后基本上是打不开大点的dump文件(该文件有6个G),所以需要使用命令行启动MAT同时指定最大堆内存参数; - 进入到安装目录,启动命令:MemoryAnalyzer.exe -vmargs -Xmx8g 复制代码
打开后看到
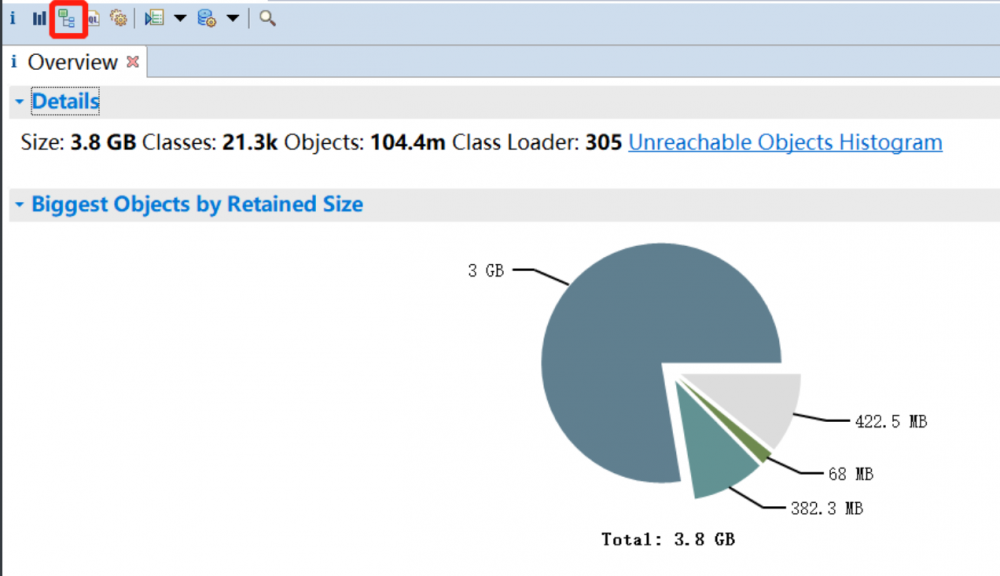
显然占用3G的对象是有问题的,点击左上角的图标查看对象分布,找到占用内存过大的对象

基本一个对象占了5M左右,到这里基本就知道问题在哪了,找到代码去解决BUG吧,其实很多时候full gc还是代码写的有问题,这样的代码是真的存在的,遇到几次了。
2.3.2. 日志分析
对于上面的full gc问题其实从GC日志一开始也分析出来了,只是当时还没出现full gc就打算第二天去解决,但是晚了。根据公司老司机分享的经验,首先看下eden区域情况
cat gc.log | grep 'Eden'|less 复制代码
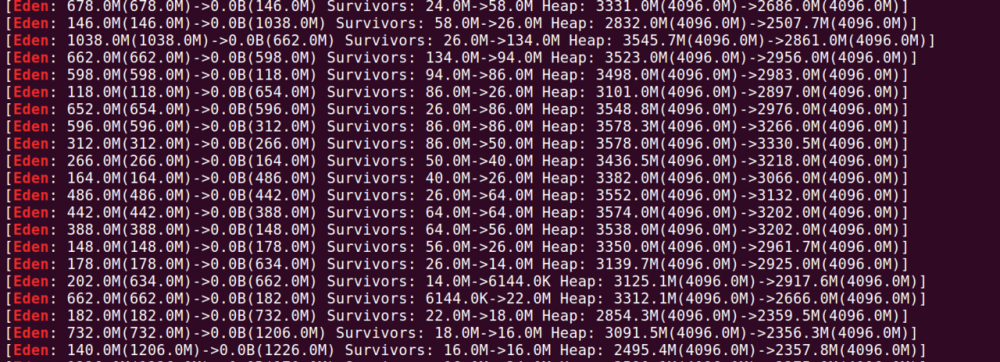
回收后基本都在3000M左右,老年代占用了那么多基本上会大批量的进行mixed gc,查看下频率
$ cat gc.log | grep 'mixed'|awk '{print $1}'
$ cat gc.log | grep 'real'|awk '{print $4}'|sort -n -k 2 -t = # 这条可以不看
复制代码
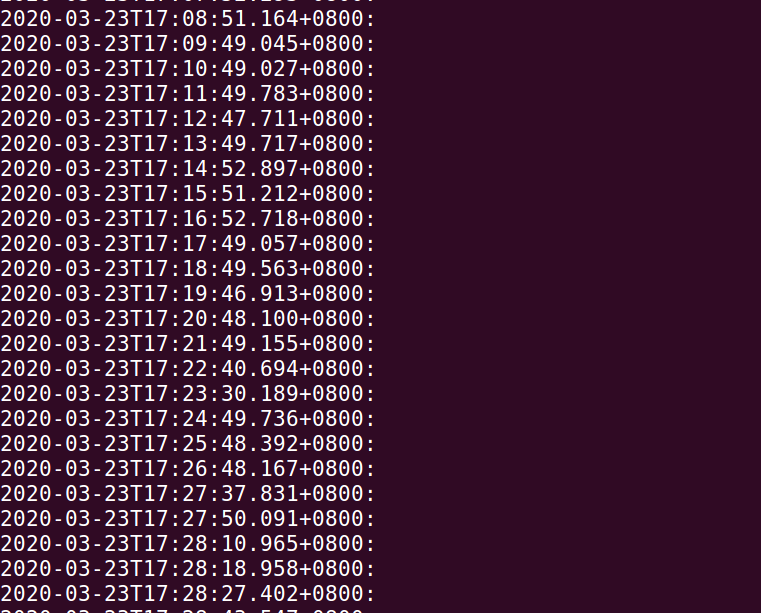
其实这个频率是不合理的,几乎是一分钟一次 mixed gc,再来看gc 内容:从mixed gc往下找,发现了mixed gc前的yong gc总会有大对象内存分配申请。

说明不停的有大对象内存申请,然后大对象会直接进入老年代Humongous 区(如果是5M那么得三个连续的Humongous 区),导致内存不断上涨,但是得不到释放后又不断申请。如果使用 jmap -histo pid 基本就能查到是啥子对象了。
2.4.2. YGC时间过长问题分析
通常情况下由于新生对象存活率低,YGC的时间是很短的,因为不需要拷贝大量存活对象。但是还真见过两次YGC时间过长的问题(1-3秒),由于会STW所以这个问题是需要解决的。之前有人反馈服务存在间歇性抖动问题(内存也存在抖动,当时只分配了2G内存,所以问题非常明显,后续是改了4G才改善了很多,下面的分析则是基于改善后的分析)。
同样还是先grep 'Eden'区域:
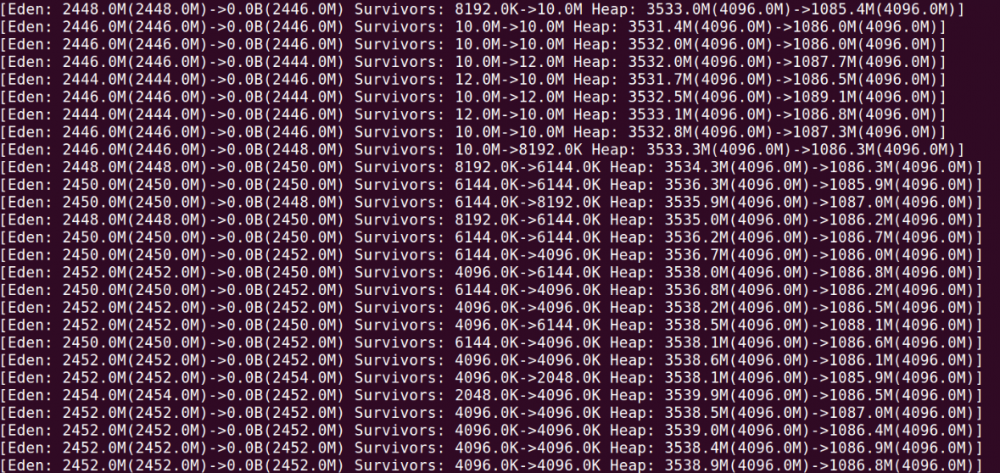
前面还好都是上图那样,属于正常。但是继续翻发现了问题:
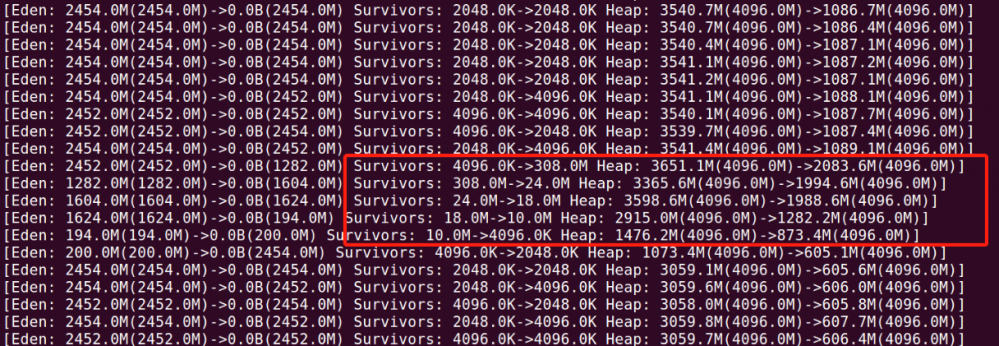
内存突然陡增,当然几次gc后又下来了,显然这里必定做了 mixed gc (可能是几次),查一些mixed gc频率发现是每30分钟一次(如果堆对内存有监控那更是一目了然),到这里可以猜测是不是什么定时任务导致的(比如lettuce的拓扑结构每隔n分钟刷新一次也需要考虑),可以使用jmap查看对象占用内存情况,然后确定该对象属于哪一块功能从而确定问题点,其实最后发现就是定时任务导致的。
进入到日志内容的时候可以发现,大量的内存拷贝占了过多的时间
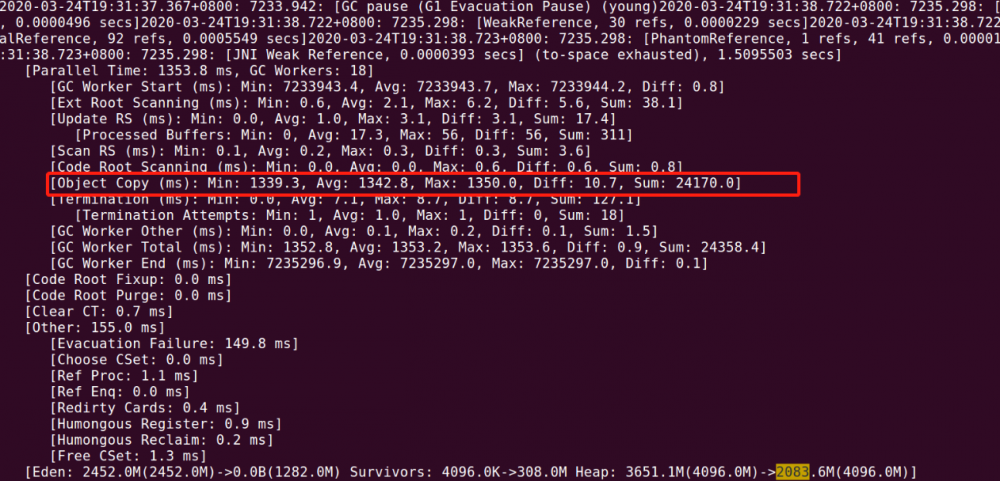
因为定时任务导致了创建很多对象分配在Eden区域,gc后对这些对象进行拷贝,导致survivor区域暴涨,同时可能因为survivor不能完全容纳这些对象,导致直接进入到了老年代,从而占用内存一下涨了1G,此时2G内存已经占了最大对内存的一半了,接下来基本是会进行mixed gc来回收全部新生代的和部分有价值的老年代了。
正文到此结束
- 本文标签: root tar Region App ECS IO 索引 PHP 安装 空间 统计 ORM HashMap update https map 时间 src 下载 mongo rmi awk apr 代码 同步 文章 本质 目录 ip cat 多线程 final 1111 bug 并发 mina 产品 数据 参数 ACE id yong GC eclipse 线程 调试 value 博客 MQ Full GC tab grep UI key http 垃圾回收 JVM
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

