领域驱动开发简介
领域驱动设计是一种软件开发方法,其基础是使软件深刻反映真实世界的系统或过程。
领域驱动设计中的“领域”是指“应用程序逻辑所围绕的知识和活动领域”。换句话说,“领域”是在软件领域中通常被称为“业务逻辑”的东西。
在域驱动设计中,业务逻辑被视为软件的心脏。
你会在本文中找到对领域驱动设计的介绍,该介绍主要按照Eric Evans的书中的解释进行。还存在其他实现和词汇,以及相似体系结构共享相同原理,例如清洁架构和六边形架构。
1. 领域驱动设计是否适合我?
领域驱动设计的目标是把领域代码从技术细节中释放,从而拥有更多空间来处理其复杂性。它非常适合处理高度复杂的领域,并且项目开始陷入遗留问题的处理。
实施领域驱动方法也意味着一开始花费更多的成本。开发人员将首先面临陡峭的学习曲线和掌握架构,这将使构建软件所需的时间更长。由于这些原因,不建议在简单的项目和无经验的团队中应用领域驱动设计。
在Inato,域驱动设计非常合适,因为我们开始发现我们的代码难以测试,从功能的角度很难阅读,并且在出现新的用例时很难扩展。产品的复杂性正在迅速上升,我们需要扩展代码的基础架构来处理它并更快地进行交付。
2. 一个例子
在深入探讨概念之前,这是实施领域驱动开发的代码的一个小示例。本示例实现对购物车的更新。我鼓励你在阅读完本文的其余部分后再回头看看这个例子。
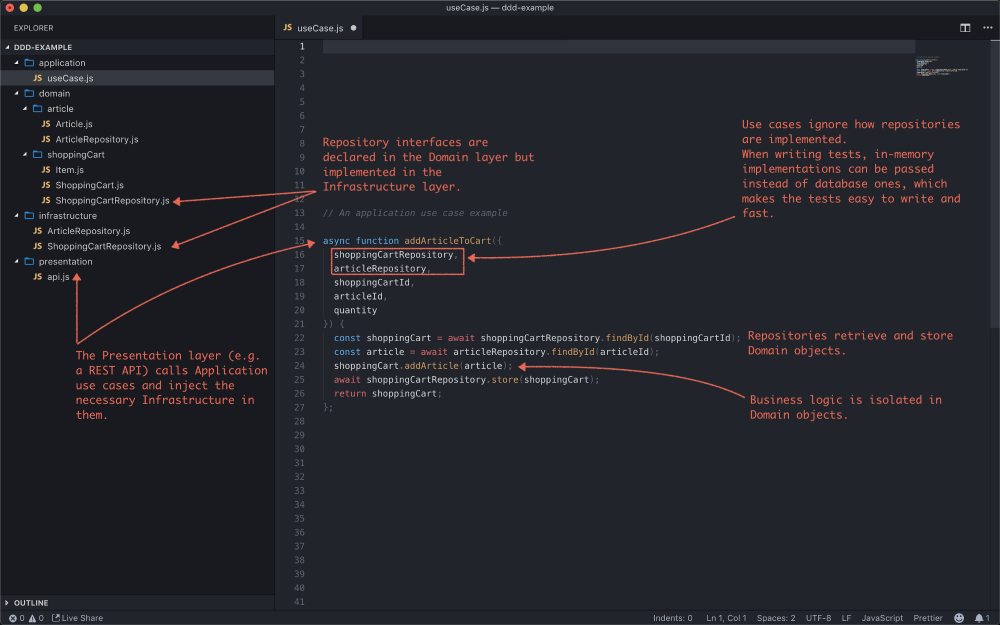
从中,你可以看出:
- 该代码非常具有表达力,因为该代码几乎可以像母语一样易于阅读
- 该代码易于测试( 请参见此处如何编写测试 )
- 耦合点分离,因为此业务代码独立于数据存储方式
3. 域驱动设计的基础
我们将要讨论领域驱动设计里面的三个核心概念。
- 把关注点通过层来分离
- 领域建模
- 管理领域对象的生命周期
3.1 领域隔离:分层架构
领域驱动设计专注于领域建模,并将模型(或业务逻辑)与实现细节(例如我们使用哪个数据库)分开。
确实,如果将与领域相关的代码与其他代码混合在一起,则很快就很难进行推理了。
推荐的体系结构由4层组成:展现层、应用层、领域层和基础设施层。
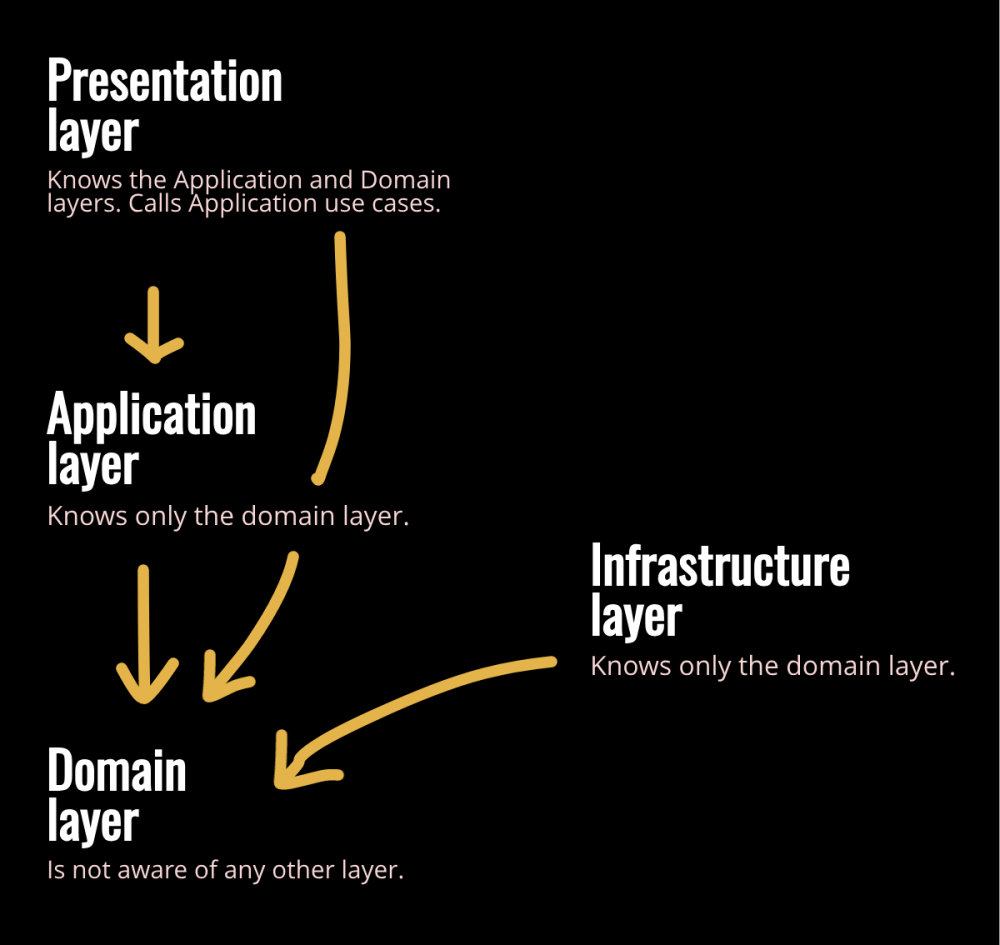
用户界面(或表示层)
负责向用户显示信息并接收用户的命令。外部参与者有时可能是另一个计算机系统,而不是人类用户。
应用层
定义软件应该执行的工作(用例)并协调域对象以解决问题。
该层保持简单。它不包含业务规则或知识,而仅协调任务并将工作委托给下一层的域对象协作。
它没有反映业务情况的状态,但是可以具有反映用户或程序的任务进度的状态。
领域层(或模型层)
负责代表业务概念,有关业务状况的信息和业务规则。
在这层中反应业务状况的状态将会被使用,而状态存储的技术细节委托给基础结构。
该层是业务软件的核心。
基础设施层
向更高层的提供通用技术功能:如应用程序的消息发送,领域的持久性,UI的绘图小部件等等。基础架构层还可以通过架构框架支持四层之间的交互模式。
3.2 领域建模
领域建模是一种使用概念和结构描述领域知识的活动,这些概念和结构将有助于推理和实现领域。
其基本约束是该模型必须既有助于功能的实现,又必须代表现实生活中的知识。
为了在代码中强制执行领域的表示,领域驱动设计还鼓励使用“统一建模语言”,该语言在开发人员和业务人员之间共享。
1) 实施领域建模的最佳实践
- 将模型用作统一建模语言的骨干
- 求团队在团队内部和代码中的所有沟通中坚持不懈地使用该语言
- 在图表,写作尤其是演讲中使用相同的语言
- 以我们就普通单词的含义达成共识的方式,解决对话中术语混淆的问题
- 当对模型进行更改时,重构代码(重命名类,方法,模块等)以符合新模型。
- 认识到统一建模语言的改变也是对模型的改变。
- 相反,开发人员需要意识到更改代码也意味着更改模型。
- 领域专家(产品人员)应避免使用不利于理解领域的的术语或结构;开发人员应关注模棱两可或不一致的设计。
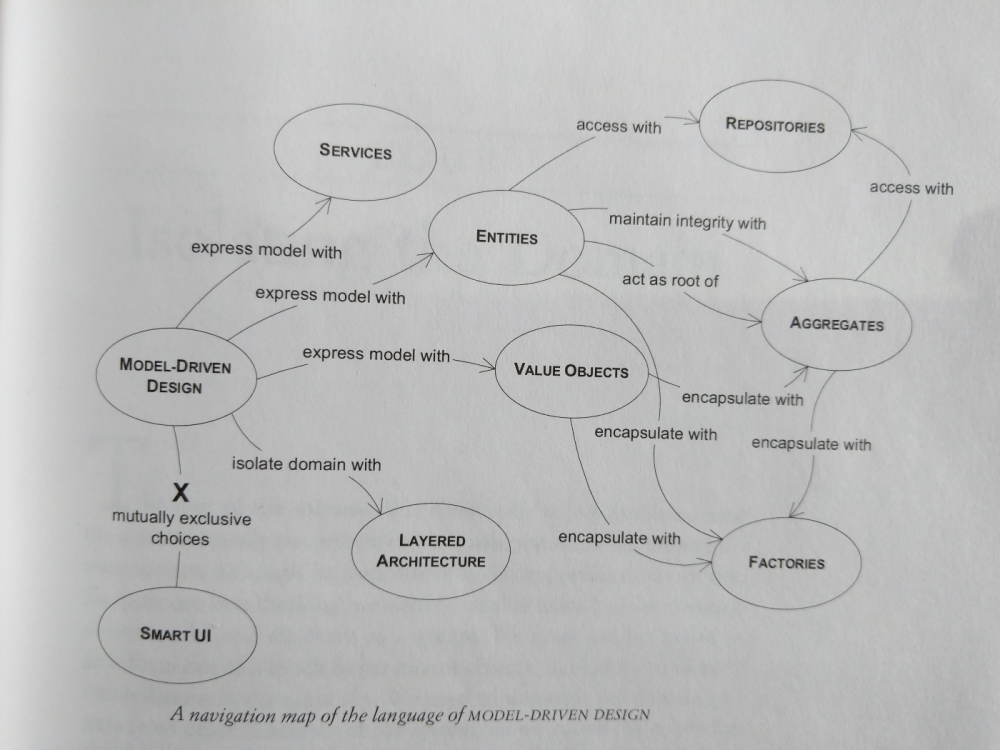
2) 表示模型:构件块
有3种工具可以在领域驱动设计中表达模型,可以在模块中进行分组:
- 值对象
- 实体
- 服务
值对象
值对象是传达含义和功能的简单对象。这些对象描述了事物,但没有特殊的标识。
值对象通常作为参数在对象之间的消息中传递。它们通常是为操作临时创建的,然后丢弃。
最佳做法:
- 值对象是不可变的
- 不要给它任何标识,并避免维护实体所需的设计复杂性。
- 确保组成值对象的属性形成概念上的整体。
```javascriot
// An example of a Value Object
class Price {
amountInEuroCents: number
inEuros(): number {
// implementation
}
// other logic
}
```
实体
实体是主要由其身份而不是特定属性定义的对象。实体的身份贯穿时间,可能还有不同的表示形式。实体也称为“参考对象”。
```
// An example of an Entity
class ShoppingCart {
id: ShoppingCartId;
items: Array<ShoppingCartItem>
addItem(item: ShoppingCartItem) {
// implementation
}
}
```
服务
在某些情况下,一个服务简单来说就是包括了若干操作,从概念上服务不从属于任何对象。我们可以根据问题的实际情况,在模型中明确包含服务,而不是死搬硬套。
// For e-commerce, an example of a domain service would be the checkout step
function checkout(shoppingCart: ShoppingCart, ...) {
// do service stuff
}
模块
领域分层中的模块应作为模型的有意义的一部分出现,以更大的规模来描述领域。
无论是代码方面还是概念方面,模块之间的耦合度应低,模块之间应具有较高的凝聚力。
- 一个人一次可以考虑多少件事是有限制的(因此需要低耦合)。
- 不连贯的想法和毫无差别的想法一样都难以理解(因此需要高内聚)
最佳做法
- 给模块命名是统一建模语言的一部分。模块及其名称应反映对该领域的了解。
- 创建模块时,在概念上要优先于技术上的方便(如果不能同时实现这两者)
3) 管理领域对象的生命周期
目的是防止模型因管理生命周期的复杂性而陷入困境。为此,我们将生命周期的管理(即持久性对象)与业务逻辑分开。
最重要的概念是聚合和存储库。注意:聚合始终与一个且仅一个存储库关联。
聚合
聚集是一组实体和值对象,它们在域上有意义,并且被检索并持久保存在一起。
聚合为模型所包含的对象设置边界并提供清晰的所有权,使模型结构化。
最佳做法
- 将实体和值对象聚类为聚合,并在每个实体周围定义边界。
- 选择一个实体作为每个聚合的根,并控制通过根对边界内对象的所有访问。
- 允许外部对象仅保留对根的引用。这种安排使得在状态改变时聚合和聚合中对象的不变量作为一个整体被对待。
```
// Our ShoppingCart example of an Entity is actually also an aggregate.
class ShoppingCart {
id: ShoppingCartId;
items: Array<ShoppingCartItem>
addItem(item: ShoppingCartItem) {
// implementation
}
}
```
尽管聚合通过定义所有权和边界来帮助管理生命周期,但它们对基础结构的细节一无所知,并且属于领域层。
存储库
存储库提供了一个接口来检索和保持聚合。他们从域中隐藏数据库详细信息。存储库管理生命周期的中期和中期。存储库接口在域层中声明,但是存储库本身在基础结构层中实现。这使得在存储库的不同实现之间轻松切换而不会影响任何业务代码(例如,从SQL到No-SQL存储,或编写内存实现以进行更快的测试)。
```
// Repository interface example
interface ShoppingCartRepository {
findById(shoppingCartId: ShoppingCartId): Promise<ShoppingCart>;
store(shoppingCart: ShoppingCart): Promise<void>;
}
```
```
class InMemoryShoppingCartRepository implements ShoppingCartRepository {
findById(shoppingCartId: ShoppingCartId) {
// implementation
}
store(ShoppingCart: ShoppingCart): Promise<void> {
// implementation
}
}
```
4. 更进一步
不要忘记从一开始就回顾一下代码示例,以了解所有代码示例如何结合到实际代码中。
实际上还不止如此,所以我真的建议你在正式实施前读一本书或两本书。到目前为止,这是我们迄今为止在Inato中使用过的最佳资源,可帮助我们进行域驱动设计:
- 《领域驱动设计》,Eric J. Evans
- 《 Implementing Domain-Driven Design 》,Vaughn Vernon
- 实现《域驱动设计》一书中示例的开源库: https://github.com/citerus/ddd ... ample
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

