读Hadoop3.2源码,深入了解java调用HDFS的常用操作和HDFS原理
本文将通过一个演示工程来快速上手java调用HDFS的常见操作。接下来以创建文件为例,通过阅读HDFS的源码,一步步展开HDFS相关原理、理论知识的说明。
说明:本文档基于最新版本Hadoop3.2.1
目录
一、java调用HDFS的常见操作
1.1、演示环境搭建
1.2、操作HDFS
1.3、java文件操作常用方法
二、深入了解HDFS写文件的流程和HDFS原理
2.1、Hadoop3.2.1 源码下载及介绍
2.2、文件系统:FileSystem
2.3、HDFS体系结构:namenode、datanode、数据块
2.4、如何访问阿里云OSS等文件系统
2.5、文件租约机制
2.6、RPC机制
2.7、HDFS客户端写流程总结
2.8、Hadoop3.x新特性:纠删码
2.9 文件透明加密处理和目录树
2.10、HDFS客户端写流程总结
一、java调用HDFS的常见操作
首先我们搭建一个简单的演示工程(演示工程使用的gradle,Maven项目也同样添加以下依赖),本次使用的是Hadoop最新的3.2.1。
1.1、演示环境搭建
新增一个普通的java工程即可,过程略,添加hdfs相关依赖jar包
implementation ('org.apache.hadoop:hadoop-common:3.2.1')
implementation ('org.apache.hadoop:hadoop-hdfs:3.2.1')
implementation ('org.apache.hadoop:hadoop-mapreduce-client-core:3.2.1')
implementation ('org.apache.hadoop:hadoop-client:3.2.1')
在实际运行过程中,可能会发现日志Jar包冲突问题,排除掉即可
exclude group:'org.slf4j',module: 'slf4j-log4j12'
1.2、操作HDFS
以创建文件为例,代码如下。可以看到java操作hdfs就是这么简单、丝滑,so easy!
public static void main(String[] args) throws IOException {
// 配置对象
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://172.22.28.202:9000");
// HDFS文件系统的操作对象
FileSystem fileSystem = FileSystem.get(configuration);
// 创建文件。
FSDataOutputStream outputStream =
fileSystem.create(new Path("/hdfs/madashu/test"));
// 写入文件内容
outputStream.write("你好Hadoop,我是码大叔".getBytes());
outputStream.flush();
IOUtils.closeStream(outputStream);
}
1.3、java文件操作常用方法
参照第2步文件创建的操作,我们可以预定义好Configuration和FileSystem,然后提取出HDFSUtil的工具类出来。涉及到文件方面的操作基本只需要hadoop-common包下的 FileSystem 就足够了,一些常用方法的说明:
//文件是否存在 fileSystem.exists(new Path(fileName)); //创建目录 fileSystem.mkdirs(new Path(directorName)); //删除目录或文件,第二个参数表示是否要递归删除 fileSystem.delete(new Path(name), true); //获取当前登录用户在HDFS文件系统中的Home目录 fileSystem.getHomeDirectory(); //文件重命名 fileSystem.rename(new Path(oldName), new Path(newName)); //读取文件,返回的是FSDataInputStream fileSystem.open(new Path(fileName)); //创建文件,第二个参数表示文件存在时是否覆盖 fileSystem.create(new Path(fileName), false); //从本地目录上传文件到HDFS fileSystem.copyFromLocalFile(localPath, hdfsPath); //获取目录下的文件信息,包含path,length,group,blocksize,permission等等 fileSystem.listStatus(new Path(directorName)); //释放资源 fileSystem.close(); //设置HDFS资源权限,其中FsPermission可以设置user、group等 fileSystem.setPermission(new Path(resourceName), fsPermission); //设置HDFS资源的Owner和group fileSystem.setOwner(new Path(resourceName), ownerName, groupName); //设置文件的副本 fileSystem.setReplication(new Path(resourceName), count);
二、深入了解HDFS写文件的流程和HDFS原理
文件操作的方法比较多,本期我们以create方法为例,来通过阅读源码深入了解下hdfs写文件的流程和原理,代码参见1.2 。
2.1、Hadoop3.2.1 源码下载及介绍
hadoop源码地址: https://github.com/apache/hadoop,。
正常途径下访问比较慢的同学(每次写到这句话,都满脸的忧伤和xx)也可以通过国内的 清华大学开源软件镜像站 来下载,地址是https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1-src.tar.gz
下载后我们可以看到这是一个maven工程,导入到idea等我们熟悉开发工具中即可。如果是使用VS需要编译的小伙伴注意下,

目录下有一个BUILDINDG.txt文件,针对比较关键的几个modules做了说明。

这里面很多工程都是和打包相关的,有一个没提到的“hadoop-cloud-storage-project”是和云存储相关的,比如我们熟悉的阿里云,AWS等。这次我们需要关注的是hadoop-hdfs-project,hadoop-hdfs-common-project。
2.2、文件系统:FileSystem
代码参见1.2,我们看到在操作hdfs之前首先需要根据配置文件获取文件系统。
问题:
1、为什么传入的地址是“hdfs:”开头的
2、为什么要获取文件操作系统
我们直接进入get方法
public static FileSystem get(URI uri, Configuration conf) throws IOException {
//获取文件的前缀,即我们传入的 hdfs:
String scheme = uri.getScheme();
// 为了便于阅读,删除掉很多代码
// 从缓存中获取
return CACHE.get(uri, conf);
}
那么缓存中存放了什么呢?一层层深入代码,首先会检查文件系统是否存在,不存在则创建文件系统,最终将文件系统存放在map中。
private static final Map<String, Class<? extends FileSystem>>
SERVICE_FILE_SYSTEMS = new HashMap<>();
public final class HdfsConstants {
/**
* URI Scheme for hdfs://namenode/ URIs.
*/
public static final String HDFS_URI_SCHEME = "hdfs";
我们再回过头来打开 FileSystem 类
public abstract class FileSystem extends Configured implements Closeable, DelegationTokenIssuer
可以看到FileSystem是一个抽象类,它有很多的子类即实现,比如DistributedFileSystem。所以这一步的操作实际是根据你输入的前缀,通过Java中SPI机制从Serviceloder中获取所需的文件操作系统。这里我们还很惊喜地看到 AliyunOSSFileSystem 。Hadoop3.x中默认支持阿里云OSS对象存储系统作为Hadoop兼容的文件系统。阿里云OSS是中国云计算厂商第一个也是目前唯一一个被Hadoop官方版本支持的云存储系统。这是继Docker支持阿里云存储以后又一个更重大的里程碑,这也表明主流开源社区对中国技术生态的认可。假如我们要使用阿里云的文件系统,前缀是什么呢?翻看 AliyunOSSFileSystem 代码
public String getScheme() {
return "oss";
}
比如 oss://madashu/test。同样如果需要使用亚马逊的文件系统,则前缀是“abfs://”
2.3、HDFS体系结构:namenode、datanode、数据块
根据1.2实例代码,获取到文件操作系统后,就是创建文件了,最终我们跟踪到如下的方法
public abstract FSDataOutputStream create(Path f,
FsPermission permission,
boolean overwrite,
int bufferSize,
short replication,
long blockSize,
Progressable progress) throws IOException;
参数说明:
- Path:存放路径
- FsPermission:文件权限
- overwrite:当文件存在时是否覆盖
- bufferSize:客户端的buffer大小
- replication:文件副本数
- blockSize:块大小
- Progressable:文件写入的进度
这里有2个参数:replication和blockSize,在解释之前得先了解一下HDFS的体系结构

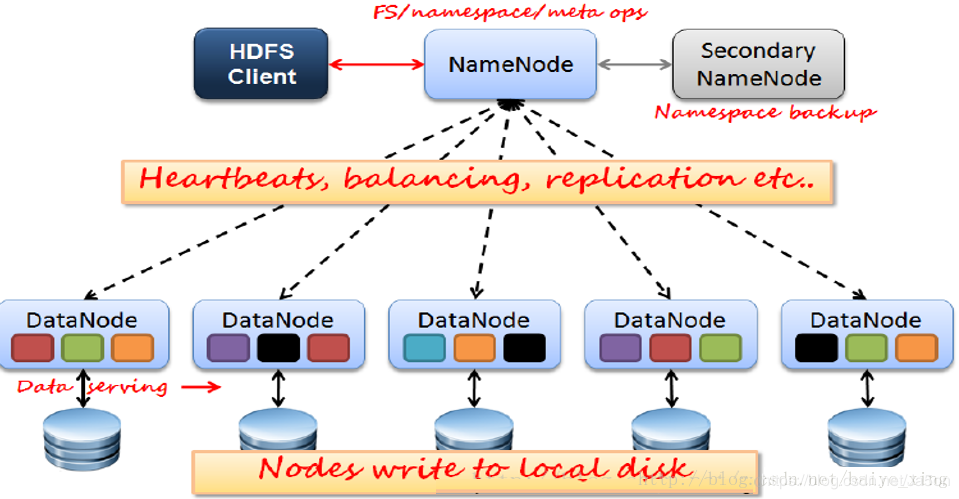
HDFS是一个主/从(Master/Slave)体系结构的分布式系统,将一个大文件分成若干块保存在不同服务器的多个节点中,通过联网让用户感觉像是在本地一样查看文件。HDFS集群拥有1个Namenode和n个Datanode,用户可以通过HDFS客户端和Namenode、Datanodes交互以访问文件系统。
Namenode是HDFS的master节点,负责管理文件系统的命名空间,即namespace,他维护这文件系统树及整棵树内所有的文件和目录。这些信息以 命名空间镜像 文件和 编辑日志文件 两个文件持久化保存在文件磁盘上。namenode也留着每个文件中各个块所在的数据节点信息,但是 并不永久保存块的位置信息,这些块的位置信息会在系统启动时根据数据信息节点创建 。
Datanode是文件系统的工作节点,它根据客户端或namenode需要存储并检索数据块,并且定期向nomenode发送所存储的块的列表。
Block是HDFS的最小存储单元。默认大小:128M(HDFS 1.x中,默认64M),若文件大小不足128M,则会单独成为一个block。实质上就是Linux相应目录下的普通文件,名称格式:blk_xxxxxxx。
HDFS块为什么这么大呢?HDFS的块比磁盘的块大,主要是为了最小化寻址的开销。如果块足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因而,传输一个由多个块组成的大文件的时间取决于磁盘传输速率。如果一个1MB的文件存储在一个128M的块中时,文件实际只是用了1M的磁盘空间,而不是128M。
为了降低文件丢失造成的错误,它会为每个小文件复制多个副本(默认为三个),以此来实现多机器上的多用户分享文件和存储。
第一个复本会随机选择,但是不会选择存储过满的节点。
第二个复本放在和第一个复本不同且随机选择的机架上。
第三个和第二个放在同一个机架上的不同节点上。
剩余的副本就完全随机节点了。
补充1:create方法还有最后一个参数:Progressable,主要是为了便于我们知悉文件的写入进度,使用方法如下:
FSDataOutputStream outputStream = fileSystem.create(new Path(targetDirector + File.separator + fileName), new Progressable() {
long fileCount = 0;
@Override
public void progress() {
fileCount++;
System.out.println("总进度:" + fileCount + "|" + fileSize + "|" + (fileCount / fileSize) * 100 + "%");
}
});
补充2:在Hadoop3.2中namenode的默认端口配置发生变化:从50070改为9870
2.4、如何访问阿里云OSS等文件系统
我们继续往下扒代码
@Override
public FSDataOutputStream create(final Path f, final FsPermission permission,
final EnumSet<CreateFlag> cflags, final int bufferSize,
final short replication, final long blockSize,
final Progressable progress, final ChecksumOpt checksumOpt)
throws IOException {
// 文件操作统计,比如创建、删除、拷贝等等,以及操作次数
statistics.incrementWriteOps(1);
storageStatistics.incrementOpCounter(OpType.CREATE);
// 创建文件输出流,采用了责任链的设计模式
Path absF = fixRelativePart(f);
return new FileSystemLinkResolver<FSDataOutputStream>() {
@Override
public FSDataOutputStream doCall(final Path p) throws IOException {
final DFSOutputStream dfsos = dfs.create(getPathName(p), permission,
cflags, replication, blockSize, progress, bufferSize,
checksumOpt);
return dfs.createWrappedOutputStream(dfsos, statistics);
}
@Override
public FSDataOutputStream next(final FileSystem fs, final Path p)
throws IOException {
return fs.create(p, permission, cflags, bufferSize,
replication, blockSize, progress, checksumOpt);
}
}.resolve(this, absF);
}
接下来再进入 FileSystemLinkResolver 类:
1、调用doCall 内部类 DFSClient的create方法,然后将DFSOutputStream包装FSDataOutputStream
2、如果是符号链接文件,则一层一层找到最底层的文件。甚至能连接到其他的文件系统的文件,比如从HDFS文件系统连接到阿里云OSS文件系统、亚马逊文件系统等。
2.5、文件租约机制
继续跟踪代码,进入 DFSClient 类
public DFSOutputStream create(String src, FsPermission permission,
EnumSet<CreateFlag> flag, boolean createParent, short replication,
long blockSize, Progressable progress, int buffersize,
ChecksumOpt checksumOpt, InetSocketAddress[] favoredNodes,
String ecPolicyName) throws IOException {
//检查客户端是否已经在运行了
checkOpen();
final FsPermission masked = applyUMask(permission);
LOG.debug("{}: masked={}", src, masked);
//创建文件输出流,和Namenode进行交互
final DFSOutputStream result = DFSOutputStream.newStreamForCreate(this,
src, masked, flag, createParent, replication, blockSize, progress,
dfsClientConf.createChecksum(checksumOpt),
getFavoredNodesStr(favoredNodes), ecPolicyName);
//更新文件租约:也可以理解为token,保证不会发生写文件冲突。
beginFileLease(result.getFileId(), result);
return result;
}
我们看到最后一个beginFileLease操作,也就是获取文件租约。我们暂时先忽略文件创建的过程,继续往下翻和FileLease有关的代码:
//如果是第一次,还是设置文件租约。
stat = FSDirWriteFileOp.startFile(this, iip, permissions, holder,
clientMachine, flag, createParent, replication, blockSize, feInfo,
toRemoveBlocks, shouldReplicate, ecPolicyName, logRetryCache);
//设置文件租约的方法见FSDirWriteFileOp
fsn.leaseManager.addLease(
newNode.getFileUnderConstructionFeature().getClientName(),
newNode.getId());
FileLease:文件租约,HDFS给客户端发放一个写文件操作的临时许可证,只有持有该证件者才允许操作此文件,从而保证保证数据的一致。
- 每个客户端用户持有一个文件租约。
- 每个文件租约内部包含有一个租约持有者信息,还有租约对应的文件Id列表,即当前租约持有者正在写这些文件Id对应的文件。
- 每个文件租约内包含有一个最新近更新时间,最近更新时间将会决定此租约是否已过期。过期的租约会导致租约持有者无法继续执行写数据到文件中,除非进行租约的更新。
既然每个客户端都有一个文件租约,那么HDFS如如何管理的呢?比如有些客户端用户写某文件后未及时关闭此文件。这样会导致租约未释放,从而造成其他用户无法对此文件进行写操作。答案就是LeaseManager,运行在Active NameNode的服务中。它主要做2件事:
1、维护HDFS内部当前所有的租约,
2、定期释放过期的租约对象。
补充:HDFS 只允许对一个已打开的文件顺序写入,或者在现有文件的末尾追加数据。
2.6、RPC机制
接下来我们的代码将进入 DFSOutputStream.newStreamForCreate() 方法
//调用namenode的文件创建方法
stat = dfsClient.namenode.create(src, masked, dfsClient.clientName,
new EnumSetWritable<>(flag), createParent, replication,
blockSize, SUPPORTED_CRYPTO_VERSIONS, ecPolicyName)
我们再次暂停一下,点击“这里的namenode实际是 ClientProtocol
ClientProtocol is used by user code via the DistributedFileSystem class to communicate with the NameNode. User code can manipulate the directory namespace, as well as open/close file streams, etc.
ClientProtocol用来通过DistributedFileSystem类与NameNode通信。可以操作目录名称空间,以及打开/关闭文件流等。 ClientProtocol 是一个接口,它的实现类有:

我们进入 NameNodeRpcServer.create() 方法
@Override
public HdfsFileStatus create(String src, FsPermission masked,
String clientName, EnumSetWritable<CreateFlag> flag,
boolean createParent, short replication, long blockSize,
CryptoProtocolVersion[] supportedVersions, String ecPolicyName)
throws IOException {
//确认namenode已启动
checkNNStartup();
// 获取服务端ip
String clientMachine = getClientMachine();
if (stateChangeLog.isDebugEnabled()) {
stateChangeLog.debug("*DIR* NameNode.create: file "
+src+" for "+clientName+" at "+clientMachine);
}
//检查是否可以写入。在生成上namenode正常也会进行HA,保证高可用。只有主的才可以写入,
if (!checkPathLength(src)) {
throw new IOException("create: Pathname too long. Limit "
+ MAX_PATH_LENGTH + " characters, " + MAX_PATH_DEPTH + " levels.");
}
namesystem.checkOperation(OperationCategory.WRITE);
CacheEntryWithPayload cacheEntry = RetryCache.waitForCompletion(retryCache, null);
if (cacheEntry != null && cacheEntry.isSuccess()) {
return (HdfsFileStatus) cacheEntry.getPayload();
}
作为分布式文件系统,少不了各个节点之间的通信和交互,比如client和namenode,namenode和datanode,所以需要这样一套RPC(Remote Procedure CallProtocol,远程过程调用协议)框架,允许程序像调用本地方法一样调用远程机器上应用程序提供的服务。Hadoop RPC并没有采用JDK自带的RMI,据说基于Google Protocol Buffer(简称Protobuf)来实现的。Hadoop的RPC和通用的RPC一样,包含通信模块、客户端Stub程序、服务端Stub程序、请求程序、服务程序等。
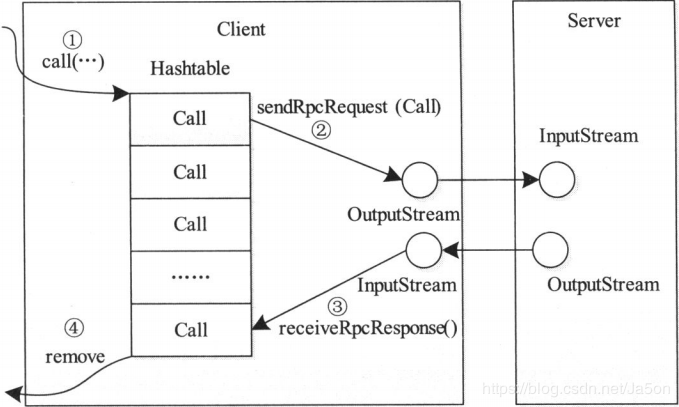
Hadoop RCP 主要提供两个接口
//构造一个客户端代理对象,用于向服务器发送RPC请求 public static <T>ProtocolProxy <T> getProxy/waitForProxy() // 为某个协议实例构造一个服务器对象,用于处理客户端发送的请求 public static Server RPC.Builder (Configuration).build()
2.7、HAState:active、standby
HdfsFileStatus status = null;
try {
PermissionStatus perm = new PermissionStatus(getRemoteUser()
.getShortUserName(), null, masked);
// 开始创建文件
status = namesystem.startFile(src, perm, clientName, clientMachine,
flag.get(), createParent, replication, blockSize, supportedVersions,
ecPolicyName, cacheEntry != null);
} finally {
RetryCache.setState(cacheEntry, status != null, status);
}
metrics.incrFilesCreated();
metrics.incrCreateFileOps();
return status;
}
@Override
// 报错
public void checkOperation(final OperationCategory op)
throws StandbyException {
state.checkOperation(haContext, op);
}
在这个代码里有一个HA状态的检查,standby 只能read,不能write。
public static final HAState ACTIVE_STATE = new ActiveState(); public static final HAState STANDBY_STATE = new StandbyState(); public static final HAState OBSERVER_STATE = new StandbyState(true);
从Hadoop2开始,增加了对HDFS高可用(HA)的支持,配置了1对active-standby的namenode。当活动的namenode失效,备用的namenode能够快速(几十秒的时间)实现任务接管,因为最新的状态存储在内存中:包括最新的编辑日志条目和最新的数据块映射信息。实际观察到的失效时间略长一点,需要1分钟左右,这是因为系统需要保守确定活动的namenode是否真的失效了。假设活动的namenode和备用的namenode都失效了(人品爆发了),管理员依旧可以声明一个备用namenode并实现冷启动。
实际开发踩坑
在实际开发过程中,由于配置或者启动顺序的原因,倒是会经查遇到standby的问题,甚至发现master和slave两个NameNode的状态均为standby。比如启动了hdfs再启动zookeeper 导致zookeeper的选举机制zkfc(DFSZKFailoverController)没有格式化 NameNode节点的自动切换机制没有开启 两个NameNode都处于standby状态(解决方案:先启动zookeeper集群:zkServer.sh start 再启动hdfs集群FSNamesystem)。
人工查看namenode的方法
sudo -E -u hadoop /home/hadoop/bin/hdfs haadmin -getServiceState nn1
2.8、Hadoop3.x新特性:纠删码
private HdfsFileStatus startFileInt(String src,
PermissionStatus permissions, String holder, String clientMachine,
EnumSet<CreateFlag> flag, boolean createParent, short replication,
long blockSize, CryptoProtocolVersion[] supportedVersions,
String ecPolicyName, boolean logRetryCache) throws IOException
//检查冗余策略:副本或者纠删码
boolean shouldReplicate = flag.contains(CreateFlag.SHOULD_REPLICATE);
//文件写入锁
writeLock();
//根据文件目录字符串实例化目录结构。比如/hdfs/madashu,在hdfs里需要把目录结构映射成对象
iip = FSDirWriteFileOp.resolvePathForStartFile(
dir, pc, src, flag, createParent);
feInfo = FSDirEncryptionZoneOp.getFileEncryptionInfo(
dir, iip, ezInfo);
// 添加到文件目录树中:检查文件是否已经存在,是否可覆盖,文件数量的限制,纠删码格式存储,获取纠删码策略,创建文件节点等。
这里面出现了一个新的名词: 纠删码,Erasure Coding,EC 。前面章节我们提到了默认情况下,HDFS的数据块都会保存三个副本。副本提供了一种简单而健壮的冗余方式来最大化保证数据的可用性。数据的多副本同时可以尽量保证计算任务的本地化。 但副本方式成本是较高的 :默认情况下三副本方式会在存储空间或其他资源(比如写入数据时的网络带宽)中产生200%的开销。对于较少访问的数据集(对集群的I/O影响相对不大),它们的第二个或者第三个副本会比较少访问,但是仍会消耗相同的存储空间。因此可以使用纠删码来代替多副本的方式,它使用更少的存储却可以保证相同级别的容错。在典型配置下,与三副本方式相比,EC可以将存储成本降低约50%。但同样他的使用也是需要一些代价的,一旦数据需要恢复,他会造成2大资源的消耗:
1、网络带宽的消耗,因为数据恢复需要去读其他的数据块和校验块
2、进行编码,解码计算需要消耗CPU资源
具体可参见https://cloud.tencent.com/developer/article/1363388
2.9、文件透明加密处理和目录树
目录树:
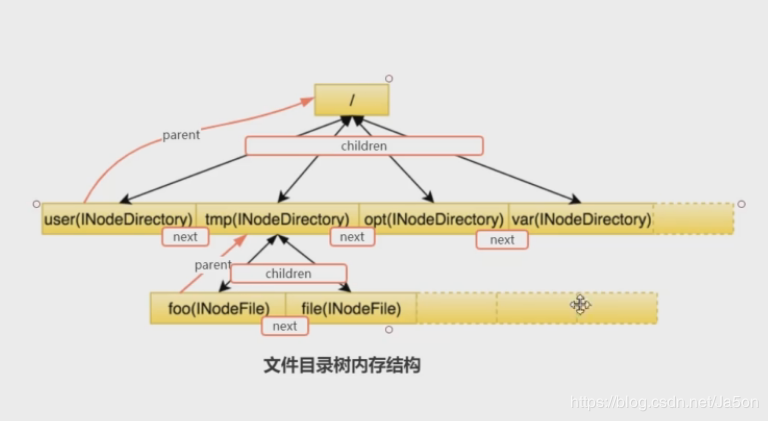
在2.8 的代码中,还出现了目录树和文件加密,这一块就不做多讲了。分享两个相关的链接:
《HDFS文件目录详解》 https://blog.csdn.net/baiye_xing/article/details/76268495
《HDFS数据加密空间--Encryption zone》 https://www.cnblogs.com/bianqi/p/12183761.html
2.10、HDFS客户端写流程总结
以上源码才完成了文件创建过程,接下来还需要通过管道方式将文件写入datanode中去,后续有机会再和大家一些学习分享。
// 创建文件。
FSDataOutputStream outputStream =
fileSystem.create(new Path("/hdfs/madashu/test"));
// 写入文件内容
outputStream.write("你好Hadoop,我是码大叔".getBytes());
outputStream.flush();
IOUtils.closeStream(outputStream);
以下文字来自于《Hadoop权威指南》一书,对HDFS客户端写流程进行了总结,作为本文的收尾,想大牛致敬!
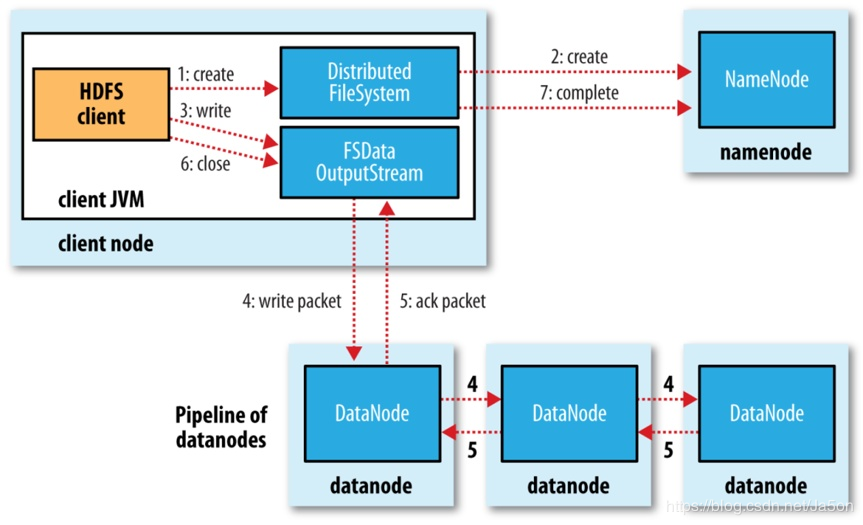
1、创建文件
HDFS客户端写一个新的文件时,会首先调用DistributedFileSystem.create()方法在HDFS文件系统中创建一个新的空文件。这个方法在底层会通过调用ClientProtocol.create()方法通知Namenode执行对应的操作,Namenode会首先在文件系统目录树中的指定路径下添加一个新的文件,然后将创建新文件的操作记录到editlog 中。完ClientProtocol.create()调用后,DistributedFileSystem.create()方法就会返回一个HdfsDataOutputStream对象,这个对象在底层包装了一个DFSOutputStream对象,真正执行写数据操作的其实是DFSOutputStream对象。
2、 建立数据流管道
获取了 DFSOutputStream对彖后,HDFS客户端就可以调用DFSOutputStream.write()方法来写数据了。由于 DistributedFileSystem.create()方法只是在文件系统目录树中创建了一个空文件,并没有申请任何数据块,所以DFSOutputStream 会首先调用 ClientProtocol.addBlock()向 Namenode 申请一个新的空数据块,addBlock()方法会返冋一个LocatedBlock对象,这个对象保存了存储这个数据块的所有数据节点的位置信息。获得了数据流管道中所有数据节点的信息后,DFSOutputStream就可以建立数据流管道写数据块了。
3、通过数据流管道写入数据
成功地建立数据流管道后,HDFS客户端就可以向数据流管道写数据了。写入DFSOutputStream中的数据会先被缓存在数据流中,之后这些数据会被切分成一个个数据包(packet)通过数据流管道发送到所有数据节点。这里的每个数据包都会按照上图所示,通过数据流管道依次写入数据节点的本地存储。每个数据包都有个确认包,确认包会逆序通过数据流管道回到输出流。输出流在确认了所有数据节点已经写入这个数据包之后,就会从对应的缓存队列删除这个数据包。当客户端写满一个数据块之后,会调用addBlock()申请一个新的数据块,然后循环执行上述操作。
4、关闭输入流并提交文件
当HDFS客户端完成了整个文件中所有数据块的写操作之后,就可以调用close()方法关闭输出流,并调用ClientProtocol.completeO方法通知Namenode提交这个文件中的所有数据块,也就完成了整个文件的写入流程。
对于Datanode ,当Datanode成功地接受一个新的数据块时,Datanode会通过
DatanodeProtocol.blockReceivedAndDeleted()方法向 Namenode 汇报,Namenode 会更新内存中的数据块与数据节点的对应关系。
我的个人微信公众号:“ 码大叔 ”,架构师,十年戎“码”,老“叔”开花,我们一起学习交流!

本文参考:
《Hadoop权威指南》
《Hadoop 2.X HDFS源码剖析 》
https://www.cnblogs.com/joqk/p/3963101.html
https://blog.csdn.net/baiye_xing/article/details/76268495
https://blog.csdn.net/androidlushangderen/article/details/52850349
http://blog.itpub.net/69908606/viewspace-2648472/
https://cloud.tencent.com/developer/article/1363388正文到此结束
- 本文标签: retry 文件权限 remote zookeeper Google CTO 阿里云 Developer ask cache 高可用 缓存 apache 端口 https apr 管理 空间 软件 开源 DDL constant 分布式 java tab git Datanode IDE 设计模式 list 总结 统计 Service id Proxy 递归 Hadoop struct Namenode 数据 时间 Docker final core 微信公众号 服务端 HashMap rmi 分布式文件系统 源码 ip HDFS 开源软件 代码 实例 锁 src 下载 Master 架构师 目录 category 协议 maven 集群 UI GitHub Android 开发 dist ACE 十年 token 云 加密 编译 db cat 配置 SDN HTML 操作系统 client 删除 文件系统 bug linux stream 服务器 node tar map 亚马逊 App 参数 build http IO 分布式系统
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

