Java 8 Stream 简介
前言
这篇文章的主题是探究 Java 8 Stream的内容,虽然现在Java 14 都发布了,但是目前企业用得最多的还是 Java 8,我们的短期关注点还是在于对 Java 8 的使用,而 Stream 是 Java 8 中一个非常重要的部分,掌握好 Stream API 能让我们的代码变得更简洁、更灵活。
Java Stream 介绍
Stream 是 Java 8 的一个重要特性,在《Java 8 实战》一书中的定义是: "从支持数据处理操作的源生成的元素序列"。我认为还可以将 Stream 看做是包装器,对数据源的包装,通过使用 Stream 对数据源进行一些处理操作。需要注意的是,Stream 不存储数据,它不算数据结构,它也不会修改底层的数据源。
中间操作 vs 终端操作
Stream 接口定义在 java.util.stream.Stream 里 ,其中定义了很多操作,它们可以分为两大类:中间操作和终端操作。我们来看一下下面的例子:
List<String> list = Arrays.asList("a1", "a2", "b1", "c1", "c2");
list.stream()
.filter(s->s.startsWith("c"))
.map(String::toUpperCase)
.sorted()
.forEach(System.out::println);
//Output:
//C1
//C2
可以看到两类操作:
- filter、map 和 sorted 是中间操作(Intermediate operations)
- forEach 是终端操作(terminal operation)
诸如 filter 或 map等中间操作会返回另一个 Stream,可以连成一条流水线。而终端操作是从流的流水线生成结果,会返回 void 或者不是流的值,比如List、Integer。
forEach 就是一个返回 void 的终端操作。同时, Stream 具有延迟特性,在调用终端操作输出结果之前,不对中间操作进行任何处理,要等到在终端操作时一次性全部处理 。
Streams VS Collections
Stream 从表面上看与 Collections 很相似,可以获取数据并对数据进行操作,但实际上它与 Collection 还是有很大不同,在 Stream Javadoc 中有说明区别。在这里,我也做了一个表格来总结这两者之间的区别:
| Collections | Streams | |
|---|---|---|
| 概念 | 主要用于存储数据 | 不存储数据,主要对数据进行计算操作 |
| 数据修改 | 可以添加或删除元素 | 不能添加或删除元素 |
| 迭代 | 必须在外部进行迭代,比如用 for-each | 利用内部迭代:替你把迭代做了 |
| 遍历 | 可以遍历多次 | 只能遍历一次,或者说只能消费一次 |
| 操作 | 一开始将所有元素纳入计算 | 延迟执行的,在调用终端操作之前,不对中间操作进行任何处理 |
获取 Stream
同样,在 Stream Javadoc 中也列举出了获取 Stream 的一些常见做法:
- 通过一个集合的 stream() 和 parallelStream() 方法获取
- 通过 Arrays.stream(Object[]) 获取数组的 Stream
- 通过 Stream 的静态方法,比如 Stream.of(Object[]);IntStream.range(int, int) 或者 Stream.iterate(Object, UnaryOperator)
- 静态方法 Files.lines 会返回一个包含文件中所有行的 Stream
- ......
Stream API 提供了 IntStream、LongStream 和 DoubleStream 等类型,专门用来对基础类型值进行计算操作,非常方便。如果是 short、char、byte 和 boolean 类型的,可以使用 IntStream;float 类型的值使用 DoubleStream。
比如,使用 IntStream.rang(int,int) 方法直接产生步进为1的一个整数范围,如下:
IntStream intStream = IntStream.range(1, 10); // 不包括上限 intStream.forEach(System.out::println);
当我们想要创建无限 Stream 的时候,可以使用 Stream 提供的两个静态方法:generate 和 iterate
- generate(Supplier<T> s) : 接受一个 Supplier<T> 接口对象作为参数,用于生产值
- iterate(final T seed, final UnaryOperator<T> f):接受一个 “种子(seed)” 和一个函数作为参数
举个例子来说明 iterate 的用法:
Stream.iterate(3, i -> i * 2).limit(5).forEach(System.out::println);
第一个元素是3,第二个元素就是 3*2 = 6,第三个元素就是:6*2 = 12,以此类推,对之前的值重复应用 iterate 的第二个参数。这里,使用了 limit 截断流,使其元素不超过给定数量。
Stream API
Stream 接口中定义了很多方法,比如 filter、sorted、distinct 等,这些都比较常见,理解起来也比较简单。下面介绍几个稍复杂一点的方法。
map
map() 方法接受一个 Function<? super T, ? extends R> 函数,通过该函数将流中的元素映射成其他形式的元素,即一对一映射,比如下面这个例子:
List<String> list = Arrays.asList("abc1", "abc2");
list.stream()
.map(element -> element.substring(0, 3))
.forEach(System.out::println);
//Output:
//abc
//abc
下图也说明了 map 的思想(图片来自于 Reactivex 网站):
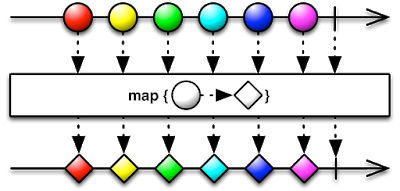
flatMap
前面提到,map 方法是将每个元素映射成另一个值,一对一。
而 flatMap 方法接受一个 Function<? super T, ? extends Stream<? extends R>> 函数,Function 函数传入泛型 T,生成 Stream<R> ,而不是 <R> ,即每个元素转换成一个 Stream,Stream 又包含0、1、或多个元素。比如下面这个例子:
List<List<String>> names = Arrays.asList(
Arrays.asList("pjmike", "pj"),
Arrays.asList("Bob", "zhangshan"));
List<String> result = names.stream()
.flatMap(Collection::stream)
.collect(Collectors.toList());
result.forEach(System.out::println);
//Output:
//pjmike pj Bob zhangshan
最开始是嵌套 List—— List<List<String>> ,每个元素就是一个 List,而 flatMap 可以处理 每个 List 元素内部的数据,将内部的数据转换成单个 Stream,或者再对单个 Stream 做进一步处理得到新的 Stream。最终将单个流合并在一起,扁平化成一个流。
同样,用一张图来说明 flatMap 的思想(图片来自于 Reactivex ):
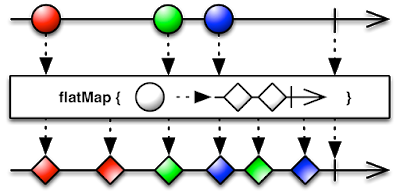
总结而言,flatMap 方法让你把每一个流中的每个值都换成另一个流,可以处理更深一层的东西,然后把所有的流连接起来成为一个流,即扁平化的思想。
reduce
简单说,reduce 是一种聚合操作,如果希望对元素求和,或者以其他方式将流中的元素组合为一个值,可以使用 reduce 方法。reduce 有三个重载方法,定义如下:
//第一个参数是初始值,第二个参数是累加器,BinaryOperator<T> 将两个元素结合起来产生一个新值 T reduce(T identity, BinaryOperator<T> accumulator); //不接受初始值,只有一个累加器参数,会返回一个 Optional 对象 Optional<T> reduce(BinaryOperator<T> accumulator); //入参为:初始值,累加器,组合器,用于并行流 <U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);
下面分别进行举例说明:
Optional<Integer> result1 = Stream.of(1, 2, 3, 4).reduce(Integer::sum); //使用方法引用
Integer result2 = Stream.of(1, 2, 3, 4).reduce(10, (x, y) -> x + y); //lambda表达式
System.out.println("result1: " + result1.get());
System.out.println("result2: " + result2);
List<User> users = Arrays.asList(new User("pj", 22), new User("pjmike", 21));
//对所有 User 的年龄求和
Integer ageSum = users.stream().reduce(0, (integer, user) -> integer + user.getAge(), Integer::sum);
System.out.println("the sum of ages: " + ageSum);
//Output:
//result1: 10
//result2: 20
//age sum : 43
如果累加器参数的类型与其返回的类型不匹配的话,就需要使用组合器。比如在上面的例子,对所有 User 的年龄求和时,accumulator 累加器参数的类型是 Integer 和 User,但是累加器返回的类型是整数的和,需要使用组合器,否则无法编译通过。
当然可以直接使用 map-reduce 的方式,可读性更好,如下:
List<User> users = Arrays.asList(new User("pj", 22), new User("pjmike", 21));
Integer reduce = users.stream()
.map(User::getAge)
.reduce(0, Integer::sum);
System.out.println(reduce);
//Output
//43
collect
collect 是一个终端操作,可以将流中的元素结合成一个 List,或者 Set、Map等。
collect 接受入参为 Collector(收集器),在Collections 工厂类中内置了常用的收集器,可以直接拿来使用。比如下面这个普通的例子,使用 toList() 将流转换成 List:
List<Integer> list = Stream.of(1, 2, 3, 4)
.collect(Collectors.toList());
再比如使用 Collections.groupingBy 方法进行分组:
List<User> users = Arrays.asList(
new User("pj", 20),
new User("pjmike", 20),
new User("bob", 22));
Map<Integer, List<User>> map = users.stream()
.collect(Collectors.groupingBy(user -> user.getAge()));
map.forEach((age,user)-> System.out.printf("age %s: %s/n", age, user));
//Output:
//age 20: [StreamTest.User(name=pj, age=20), StreamTest.User(name=pjmike, age=20)]
//age 22: [StreamTest.User(name=bob, age=22)]
想了解更多有趣的方法,可以查看 Collections 工厂类源码,这里就不多介绍了。
并行流
前面主要介绍的都是串行流,默认情况下,我们调用集合的 stream() 方法就是创建一个串行流。我们已经看到了使用流的便利性,那么如果将流用于并行计算,该怎么做呢?
首先需要有一个并行流。 并行流就是一个把内容分成多个数据块,并用不同的线程分别处理每个数据库的流,底层使用 ForkJoinPool 。
我们可以通过集合的 parallelStream() 方法获取并行流,或者在已存在的串行流上调用 parallel() 方法,将串行流转换成并行流。然后,像使用串行流一样使用并行流即可。
boolean isParallel = IntStream.range(1, 5)
.parallel().isParallel();
System.out.println("isParallel: " + isParallel);
//Output:
//isParallel: true
由于本人对并行流的使用经验较少,不过多介绍,有兴趣的朋友可以翻阅 《Java8实战》这本书,里面有对并行流的详细介绍。
小结
本次对于 Java 8 Stream 的分享就到这,如果小伙伴们想要了解更多有关 Stream 的知识,可以阅读 Stream Javadoc 官方文档,或者是 《Java 8 实战》 这本书。
参考资料 & 鸣谢
- stream javadoc
- The Java 8 Stream API Tutorial
- Mastering Lambdas: Java Programming in a Multicore World
- Difference Between Collections And Streams In Java
- Java 8 - An Introductory article to Java Streams API
- A Guide to Streams in Java 8: In-Depth Tutorial With Examples
- Java 8 实战
- 写给大忙人看的Java SE8
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

