Java|如何使用“Java”爬取电话号码
欢迎点击「算法与编程之美」↑关注我们!
本文首发于微信公众号:"算法与编程之美",欢迎关注,及时了解更多此系列文章。
前言
下面会介绍如何使用“ Java ”去爬取到一个网站的电话号码。 使用到的一些基本语法与定义: IO 流,正则表达式,如过不清楚可以先去了解一下,当然在下文中也会做出对应使用介绍与解释。
具体步骤
在这个小实验里,新建一个 class 文件就可以完成。首先需要写一个 main 函数,在 idea 和 eclipse 里都有快捷键,可以自行查阅。这里用的 idea ,直接 psvm 就可以完成。接下来就是在 main 函数里写需要的代码:
首先是载入连接需要爬取的网址:
String path = "https://www.jihaoba.com/escrow/?_mhead=4";
URL url = new URL(path);
URLConnection urlconn = url.openConnection();
然后是创建用来保存电话号码的 txt 文件:
FileWriter fw = new FileWriter("C:/Users/h/Desktop/tel.txt",true);
再是声明使用需要的输入输出流:
InputStream is = urlconn.getInputStream();
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr);
PrintWriter pw = new PrintWriter(fw);
接下来是接收获取到内容,并且通过编译后正则表达式匹配方法去循环写入到 txt 文件中:
String str = null;
String regex = "1[3456789]//d{9}";
Pattern p = Pattern.compile(regex)
while ((str = br.readLine()) != null){
Matcher m = p.matcher(str);
while (m.find()){
pw.println(m.group());
}
}
最后进行关流,释放资源:
try {
br.close();
pw.close();
} catch (IOException e) {
e.printStackTrace();
}
完整加注释代码:
但是不要认为将上面代码都扔在一起就行了哦,因为还有 try , catch 和 finally 没有写出来而且有一些小问题需要注意,接下来就看一下经过整理注释后的完整代码吧。
package com.yellow.java_pachong.tel;
import java.io.*;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//java 爬取电话号码
public class TelDemo {
//java 程序入口, main 函数
public static void main(String[] args) {
// 将变量声明在外面,成为一个全局的,因为作用域的原因,防止 finally 里无法关流
// 如果在 try 里声明,就需要在 try 里关,但是如果运行失败,就关不了, finally 里就不用担心
BufferedReader br = null;
PrintWriter pw = null;
// 目标网址的爬取,随意找的一个
String path = "https://www.jihaoba.com/escrow/?_mhead=4";
try {
// 创建一个 url 对象,一 new 一对象。
URL url = new URL(path);
// 打开网络链接
URLConnection urlconn = url.openConnection();
// 创建一个指定的存储文件 , 后面的 true 表示如果文件存在,会在原文件基础上续写
FileWriter fw = new FileWriter("C:/Users/h/Desktop/tel.txt",true);
// 流
//首先创建一个输入流
InputStream is = urlconn.getInputStream();
//is 是一个字节流,为了让我们的效率更高,将字节流转为字符流
InputStreamReader isr = new InputStreamReader(is);
// 因为网页上的是一行一行的,所以还需要将字符流转为包装的字符缓冲流
br = new BufferedReader(isr);
// 精简的写法
//BufferedReader br = new BufferedReader(new InputStreamReader(urlconn.getInputStream()));
// 创建一个缓冲字符输出流
pw = new PrintWriter(fw);
// 定一个字符串来接收读取到的内容
String str = null;
// 手机号的正则表达式 , 首先是 1 开头,然后是 3456789 的第二位,接下来后面 9 位没有要求 , 就用 /d{9} 表示,并且在 Java 里用 / 来转义
String regex = "1[3456789]//d{9}";
// 将上面的正则表达式编译成一种可以用来比较的方法,模式
Pattern p = Pattern.compile(regex);
// 按行循环的去读取内容
while ((str = br.readLine()) != null){
// 创建一个指定模式的匹配器
Matcher m = p.matcher(str);
// 循环匹配
while (m.find()){
// 使用输出流写到指定的位置 ,m.group 把匹配到的转成字符串
pw.println(m.group());
}
}
// 控制台提示完成
System.out.println(" 获取完成 !");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
// 关流,不要忘记了 , 释放资源
finally {
try {
br.close();
pw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
展示 :
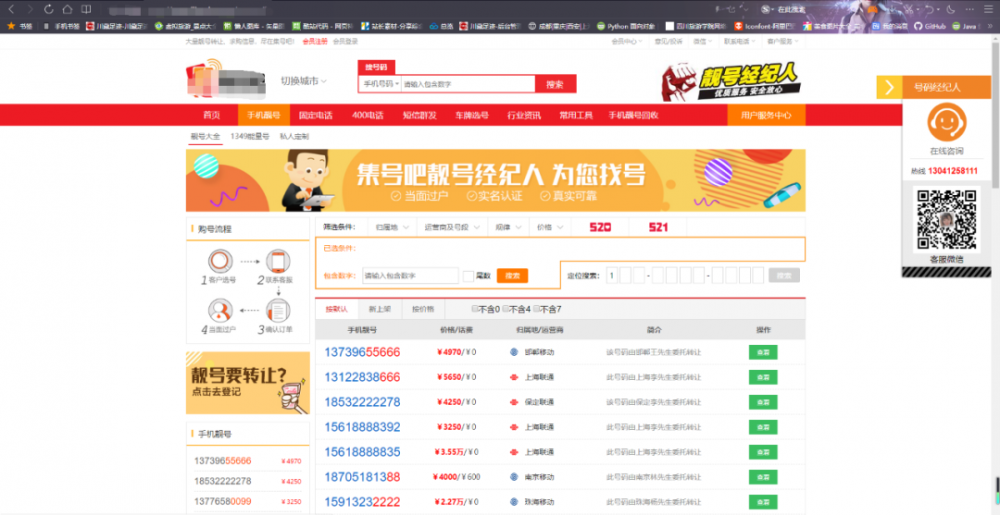
图 5.1 电话号码网
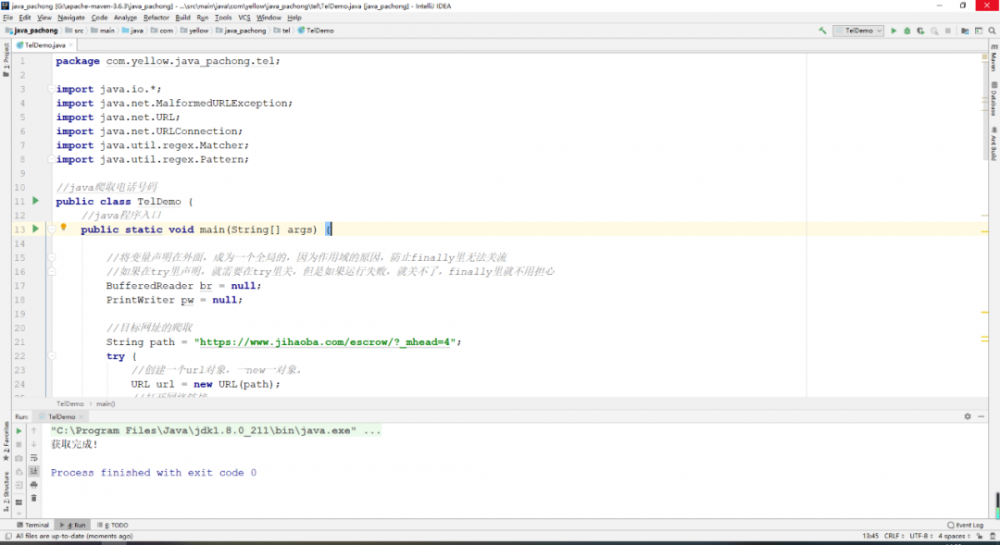
图 5.2 控制台输出完成

图 5.3 爬取到的号码
以上操作就完成了电话号码的简单爬取,在后面可能还会继续更新关于其他爬取的相关内容。
END
编 辑 | 王楠岚
责 编 | 黄晓锋
where2go 团队
微信号:算法与编程之美

长按识别二维码关注我们!
温馨提示: 点击页面右下角 “写留言”发表评论,期待您的参与!期待您的转发!
正文到此结束
热门推荐










相关文章

近期评论
-
收到
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

