【SpringBoot MQ 系列】RabbitListener 消费基本使用姿势介绍

【MQ 系列】RabbitListener 消费基本使用姿势介绍
之前介绍了 rabbitmq 的消息发送姿势,既然有发送,当然就得有消费者,在 SpringBoot 环境下,消费可以说比较简单了,借助 @RabbitListener 注解,基本上可以满足你 90%以上的业务开发需求
下面我们来看一下 @RabbitListener 的最最常用使用姿势
I. 配置
首先创建一个 SpringBoot 项目,用于后续的演示
- springboot 版本为
2.2.1.RELEASE - rabbitmq 版本为
3.7.5(安装教程可参考: 【MQ 系列】springboot + rabbitmq 初体验 )
依赖配置文件 pom.xml
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.1.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<!-- 注意,下面这个不是必要的哦-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</pluginManagement>
</build>
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/libs-snapshot-local</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/libs-milestone-local</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-releases</id>
<name>Spring Releases</name>
<url>https://repo.spring.io/libs-release-local</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
复制代码
在 application.yml 配置文件中,添加 rabbitmq 的相关属性
spring:
rabbitmq:
virtual-host: /
username: admin
password: admin
port: 5672
host: 127.0.0.1
复制代码
II. 消费姿势
本文将目标放在实用性上,将结合具体的场景来演示 @RabbitListener 的使用姿势,因此当你发现看完本文之后这个注解里面有些属性还是不懂,请不要着急,下一篇会一一道来
0. mock 数据
消费消费,没有数据,怎么消费呢?所以我们第一步,先创建一个消息生产者,可以往 exchange 写数据,供后续的消费者测试使用
本篇的消费主要以 topic 模式来进行说明(其他的几个模式使用差别不大,如果有需求的话,后续补齐)
@RestController
public class PublishRest {
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping(path = "publish")
public boolean publish(String exchange, String routing, String data) {
rabbitTemplate.convertAndSend(exchange, routing, data);
return true;
}
}
复制代码
提供一个简单 rest 接口,可以指定往哪个 exchange 推送数据,并制定路由键
1. case1: exchange, queue 已存在
对于消费者而言其实是不需要管理 exchange 的创建/销毁的,它是由发送者定义的;一般来讲,消费者更关注的是自己的 queue,包括定义 queue 并与 exchange 绑定,而这一套过程是可以直接通过 rabbitmq 的控制台操作的哦
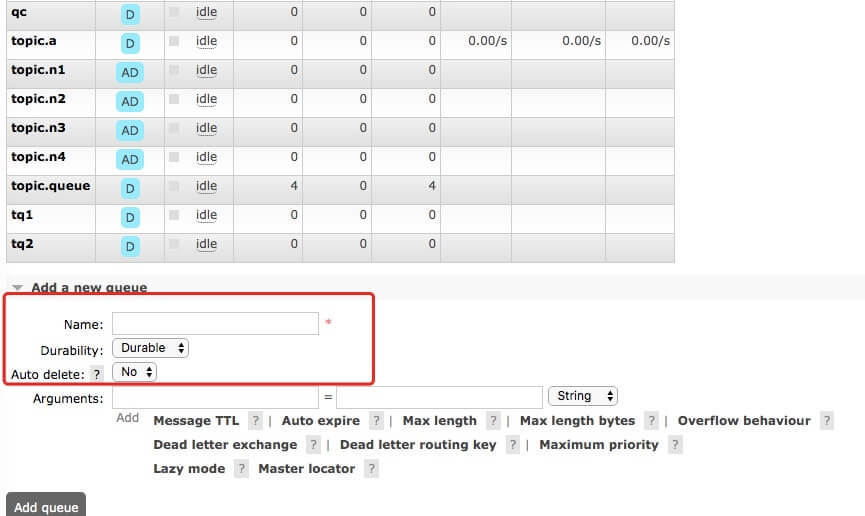
所以实际开发过程中,exchange 和 queue 以及对应的绑定关系已经存在的可能性是很高的,并不需要再代码中额外处理;
在这种场景下,消费数据,可以说非常非常简单了,如下:
/**
* 当队列已经存在时,直接指定队列名的方式消费
*
* @param data
*/
@RabbitListener(queues = "topic.a")
public void consumerExistsQueue(String data) {
System.out.println("consumerExistsQueue: " + data);
}
复制代码
直接指定注解中的 queues 参数即可,参数值为对列名(queueName)
2. case2: queue 不存在
当 queue 的 autoDelete 属性为 false 时,上面的使用场景还是比较合适了;但是,当这个属性为 true 时,没有消费者队列就会自动删除了,这个时候再用上面的姿势,可能会得到下面的异常
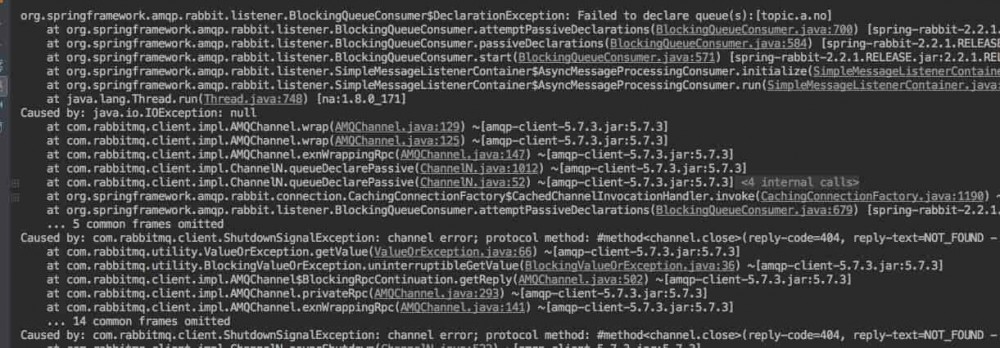
通常这种场景下,是需要我们来主动创建 Queue,并建立与 Exchange 的绑定关系,下面给出 @RabbitListener 的推荐使用姿势
/**
* 队列不存在时,需要创建一个队列,并且与exchange绑定
*/
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "topic.n1", durable = "false", autoDelete = "true"),
exchange = @Exchange(value = "topic.e", type = ExchangeTypes.TOPIC),
key = "r"))
public void consumerNoQueue(String data) {
System.out.println("consumerNoQueue: " + data);
}
复制代码
一个注解,内部声明了队列,并建立绑定关系,就是这么神奇!!!
注意 @QueueBinding 注解的三个属性:
- value: @Queue 注解,用于声明队列,value 为 queueName, durable 表示队列是否持久化, autoDelete 表示没有消费者之后队列是否自动删除
- exchange: @Exchange 注解,用于声明 exchange, type 指定消息投递策略,我们这里用的 topic 方式
- key: 在 topic 方式下,这个就是我们熟知的 routingKey
以上,就是在队列不存在时的使用姿势,看起来也不复杂
3. case3: ack
在前面 rabbitmq 的核心知识点学习过程中,会知道为了保证数据的一致性,有一个消息确认机制;
我们这里的 ack 主要是针对消费端而言,当我们希望更改默认 ack 方式(noack, auto, manual),可以如下处理
/**
* 需要手动ack,但是不ack时
*
* @param data
*/
@RabbitListener(bindings = @QueueBinding(value = @Queue(value = "topic.n2", durable = "false", autoDelete = "true"),
exchange = @Exchange(value = "topic.e", type = ExchangeTypes.TOPIC), key = "r"), ackMode = "MANUAL")
public void consumerNoAck(String data) {
// 要求手动ack,这里不ack,会怎样?
System.out.println("consumerNoAck: " + data);
}
复制代码
上面的实现也比较简单,设置 ackMode=MANUAL ,手动 ack
但是,请注意我们的实现中,没有任何一个地方体现了手动 ack,这就相当于一致都没有 ack,在后面的测试中,可以看出这种不 ack 时,会发现数据一直在 unacked 这一栏,当 Unacked 数量超过限制的时候,就不会再消费新的数据了
4. case4: manual ack
上面虽然选择 ack 方式,但是还缺一步 ack 的逻辑,接下来我们看一下如何补齐
/**
* 手动ack
*
* @param data
* @param deliveryTag
* @param channel
* @throws IOException
*/
@RabbitListener(bindings = @QueueBinding(value = @Queue(value = "topic.n3", durable = "false", autoDelete = "true"),
exchange = @Exchange(value = "topic.e", type = ExchangeTypes.TOPIC), key = "r"), ackMode = "MANUAL")
public void consumerDoAck(String data, @Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag, Channel channel)
throws IOException {
System.out.println("consumerDoAck: " + data);
if (data.contains("success")) {
// RabbitMQ的ack机制中,第二个参数返回true,表示需要将这条消息投递给其他的消费者重新消费
channel.basicAck(deliveryTag, false);
} else {
// 第三个参数true,表示这个消息会重新进入队列
channel.basicNack(deliveryTag, false, true);
}
}
复制代码
请注意,方法多了两个参数
deliveryTag channel
当我们正确消费时,通过调用 basicAck 方法即可
// RabbitMQ的ack机制中,第二个参数返回true,表示需要将这条消息投递给其他的消费者重新消费 channel.basicAck(deliveryTag, false); 复制代码
当我们消费失败,需要将消息重新塞入队列,等待重新消费时,可以使用 basicNack
// 第三个参数true,表示这个消息会重新进入队列 channel.basicNack(deliveryTag, false, true); 复制代码
5. case5: 并发消费
当消息很多,一个消费者吭哧吭哧的消费太慢,但是我的机器性能又杠杠的,这个时候我就希望并行消费,相当于同时有多个消费者来处理数据
要支持并行消费,如下设置即可
@RabbitListener(bindings = @QueueBinding(value = @Queue(value = "topic.n4", durable = "false", autoDelete = "true"),
exchange = @Exchange(value = "topic.e", type = ExchangeTypes.TOPIC), key = "r"), concurrency = "4")
public void multiConsumer(String data) {
System.out.println("multiConsumer: " + data);
}
复制代码
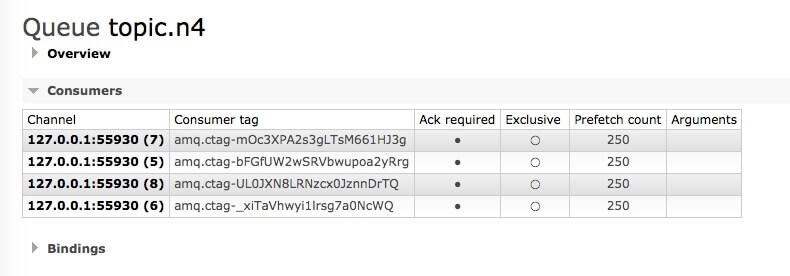
请注意注解中的 concurrency = "4" 属性,表示固定 4 个消费者;
除了上面这种赋值方式之外,还有一种 m-n 的格式,表示 m 个并行消费者,最多可以有 n 个
(额外说明:这个参数的解释实在 SimpleMessageListenerContainer 的场景下的,下一篇文章会介绍它与 DirectMessageListenerContainer 的区别)
6. 测试
通过前面预留的消息发送接口,我们在浏览器中请求: http://localhost:8080/publish?exchange=topic.e&routing=r&data=wahaha
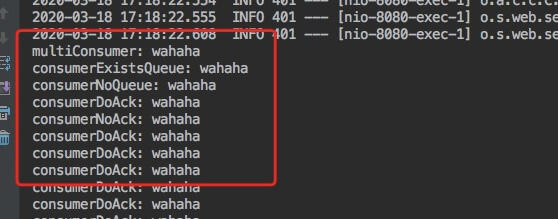
然后看一下输出,五个消费者都接收到了,特别是主动 nak 的那个消费者,一直在接收到消息;
(因为一直打印日志,所以重启一下应用,开始下一个测试)
然后再发送一条成功的消息,验证下手动真确 ack,是否还会出现上面的情况,请求命令: http://localhost:8080/publish?exchange=topic.e&routing=r&data=successMsg

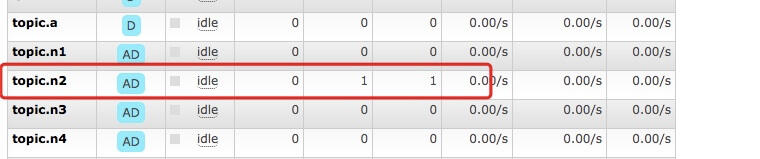
然后再关注一下,没有 ack 的那个队列,一直有一个 unack 的消息
II. 其他
系列博文
- 【MQ 系列】springboot + rabbitmq 初体验
- 【MQ 系列】RabbitMq 核心知识点小结
- 【MQ 系列】SprigBoot + RabbitMq 发送消息基本使用姿势
- 【MQ 系列】RabbitMq 消息确认/事务机制的使用姿势
项目源码
- 工程: github.com/liuyueyi/sp…
- 源码: github.com/liuyueyi/sp…
一灰灰的个人博客,记录所有学习和工作中的博文,欢迎大家前去逛逛
2. 声明
尽信书则不如,以上内容,纯属一家之言,因个人能力有限,难免有疏漏和错误之处,如发现 bug 或者有更好的建议,欢迎批评指正,不吝感激
- 微博地址:小灰灰 Blog
- QQ: 一灰灰/3302797840
正文到此结束
- 本文标签: build message rabbitmq spring https 数据 value 微博 文章 springboot git UI key Word id pom 配置 XML consumer 博客 希望 tag maven 安装 App 开发 删除 MQ 并发 源码 map 需求 dependencies http IO amqp 测试 cat 代码 参数 src plugin bug web tar GitHub REST lib queue 一致性 java 管理 list
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

