依赖标准倒置,聚合层与资源层微服务交互探讨 | ArchSummit

作者 | 奇正
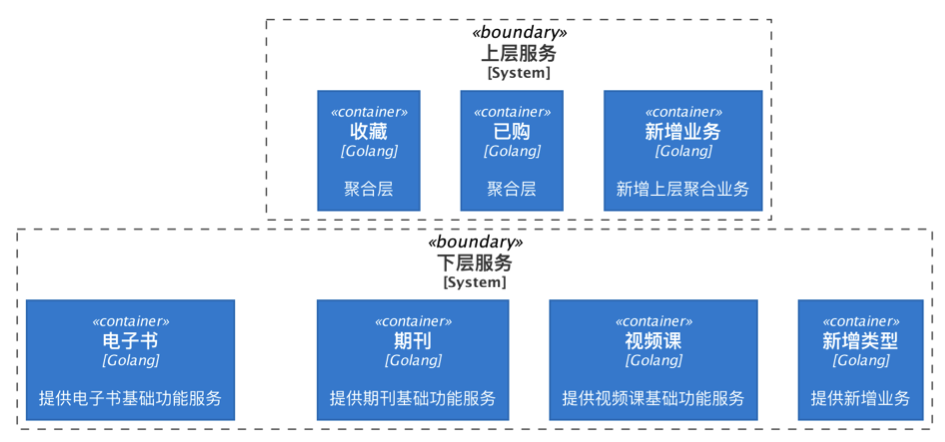
一位产品大咖曾说过,成功的 App 都是在大而全的满足用户的多样化的需求,大部分面向用户服务(ToC)的公司通常会不断的尝试多样化服务。其后端微服务群组通常可以被简单的划分为两层:下层的业务单元服务,提供独立的基础资源功能;和上层的聚合服务,基于下层资源基础上提供衍生功能。比如知识类的平台,底层提供如电子书、期刊、视频课等服务,上层有收藏服务、已购服务、历史记录等聚合服务。
聚合层服务的核心功能通常和业务类型无关,但其周边功能又需要底层资源的支撑。比如任何类商品都应当支持被收藏,而收藏列表里,又需要展示标题、封面、数量等资源信息,这些资源信息来自于底层。
1 如何选择
随着业务的不断发展,当公司决定新增一种业务形态,如付费咨询时,该如何让聚合层的所有业务都支持这一新业务类型呢?或者,公司决定新增一种聚合层业务形态,比如智能推荐业务,所有的底层业务单元都需要出现在智能推荐流里,又如何使所有的底层业务单元接入智能推荐流业务呢?
本文来探讨下层服务和上层聚合层服务在直接交互过程中的相爱相杀。
有人提出,底层每个微服务也是个独立的单元,不应该关心其他服务如何使用,上层服务请求底层资源并自行适配即可;也有人提到,创建一个通用的商品服务,用来冗余基础的商品信息,这样可以减少上层业务的对接。该如何取舍?前一种无可避免的变更所有的聚合层,后一种底层资源的增删改都要同步至该聚合层,难免引发数据不一致问题,还有更好的方案么?
上层服务自行请求底层资源,通常是最自然的演化流程,为什么呢?我们经常说微服务不止是一个技术问题,也是一个团队组织结构问题。
康威定律 “organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations.”
任何设计系统的组织,必然会产生以下设计结果: 即其结构就是该组织沟通结构的写照 。在微服务体系的团队组织下,每一例底层服务或上层聚合服务,都有独立的研发成员来开发维护,聚合层的业务功能需求实现,看似应当属于聚合层研发成员的职责,最粗糙省事的职责划分便是包揽其一切变更。
底层业务单元微服务甩出 API 文档,要对接,研究我 API 去吧!平台渐渐扩张时,会发现新增一种业务单元类型,七八个聚合层服务都要协调人力对该新业务单元来对接联调。有没有更好的解决方案呢?
2 依赖倒置
至此,我们按下暂停键,先学习下 SILID 原则之一的依赖倒置原则。依赖倒置原则是一哲理性的规则,哲理性的规则往往具有高度抽象的思想之美,可以高度抽象的指导我们的思想和行为。哲理性的规则也会超出语言范畴,无论是用 Java、Go、PHP,也查出架构方式的范畴,不管你使用面向对象,还是 DDD 等,都普遍适用。
依赖倒转原则是指: 代码要依赖于抽象的类,而不要依赖于具体的类;要针对接口或抽象类编程,而不是针对具体类编程 。再引申下,高层模块不应该依赖于低层模块,两者都应该依赖于抽象。
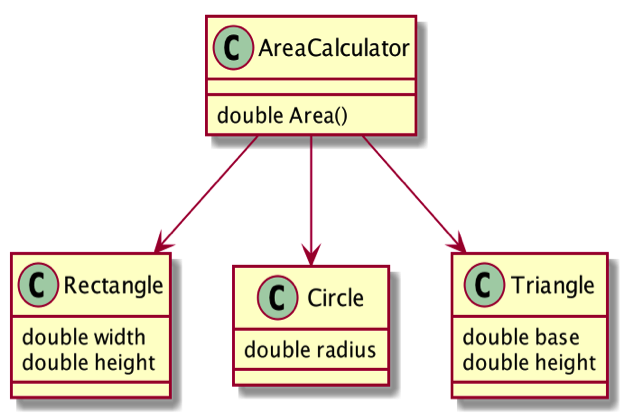
例如累加各种形状总面积的案例,粗糙的方案会导致每次添加新形状时候,修改计算面积 Area 的核心代码。
public double Area(object[] shapes)
{
double area = 0;
foreach (var shape in shapes)
{
if (shape is Rectangle)
{
Rectangle rectangle = (Rectangle) shape;
area += rectangle.Width*rectangle.Height;
}
else if (shape is Circle)
{
Circle circle = (Circle)shape;
area += circle.Radius * circle.Radius * Math.PI;
} else if (shape is NewType)
{
......
}
}
return area;
}
以抽象方式耦合是依赖倒置原则的关键,我们看到,改造后的代码,新增形状不需要改变 Area 代码。众多面向对象语言都在语言层面内置了多态和接口机制,使得我们可以很轻松的实现模块的依赖倒置,上层类给出计算面积接口,底层模块依赖上层的接口,从而解耦上下层类之间的解耦。
public double Area(object[] shapes)
{
double area = 0;
foreach (var shape in shapes)
{
area += shape.Area();
}
return area;
}
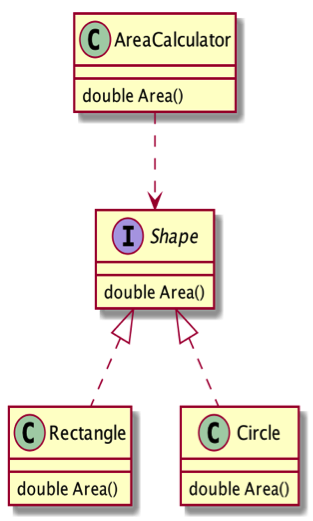
这一例子比较简单,甚至计算机教科书都有讲过。依赖倒置原则,也是构建易扩展、可重用框架 / 系统的核心原则,再延伸如 Java、Spring 核心的控制反转和依赖注入,也都属于依赖倒置原则的范畴。上文提到依赖倒置也是一种哲学层面思想,它脱离编程场景也会有其实际的适用场景,举个企业的战略例子,当年 Flash Player 曾一度去主动适配各个平台、各个浏览器,结果发现平台和浏览器层出不穷,应付的精疲力尽,后来调整战略为提出标准,希望各个厂商根据标准来进行适配,可惜还是过了最佳时机。当然 Flash Player 背后的原因肯定比我描述的复杂,比如有没有能力去推动它想要的标准,以及各方利益斡旋等。
3 依赖标准倒置
上文我们提到,上下层微服务交互,最粗糙省事的职责划分便是聚合层业务的开发者包揽其一切变更。我们重新审视下:聚合层业务的开发,可以看做是聚合层研发成员的职责;换个角度,是不是也可以看做底层业务需要融入聚合层,属于底层职责呢,两种观点都成立。面对微服务之间的交互,我们提出了依赖标准原则,并非标新立异,只是依赖倒置的一层具象化,可以帮我们明确上下层微服务交互时候应当遵循的准则。
依赖标准倒置,上层微服务规定交互的标准,下层来实现标准以满足上层微服务的设计,来尽可能的封装上层微服务变化,做到到扩展类型聚合层服务不做变化。上层微服务对修改关闭、对扩展开放,也加符合 SOLID 里开闭原则的精神。微服务之间无明确依赖标准倒置之前,整体开发计划才完备要求所有聚合层相关人都要有计划,项目管理难度也会倍增。敏捷开发中每个研发经常饱和状态,失足在某个被遗漏的聚合层支持上屡见不鲜。归纳来讲,有以下好处:
-
增加系统内不变模块或者不变服务比例。封装变化是系统设计根本,要确保尽可能多不变模块,有利于维护成本及测试成本,聚合层无代码改动,通常不需要测试资源对聚合层代码回归验证。
-
有效减少沟通成本。发生联调问题后,研发同学第一时间容易想到的是不是对方的 BUG,由于聚合层代码不会有变动,所以通常不需要参与排查。而且新增的业务方,对需求最了解这个需求的业务场景,比如展示哪类标题等,某个周期内开发关注度最高,资源也最密集。
-
利于项目管理。通常新增业务单元时,测试和研发资源集中,聚合层服务数量多时,项目排期相关人会大大减少,预估时间也更加精确,有利于团队整体的项目管理。
依赖标准倒置不但减少维护测试沟通成本,也有效的减少项目管理成本,但下层微服务容易产生大量的为了适配接口的代码,也应当配备应对的规范。系统架构是一个综合考虑和折中的过程,可以结合经验预判到某个上层服务更容易变更还是下层服务更容易变更,如支付、收藏等,大概率下层的变更更频繁,如新增类型就必须支持的支付等。
4 实现方式
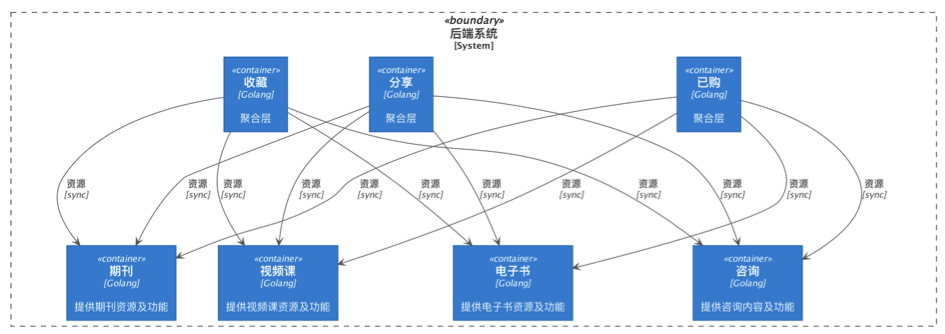
依赖倒转原则的常用实现方式之一:“将抽象放进代码,将细节放进元数据” Put Abstractions in Code, Details in Metadata(《程序员修炼之道:从小工到专家》(The Pragmatic programmer: from journeyman to master) ),依赖标准倒置,在我们应用场景中借鉴这一方式,使用统一的请求框架来完成封装变化,上层微服务提出规范标准,下层微服务依据标准实现具体 API,上层微服务将下层服务提供的 API 作为配置细节放入元数据,也即配置文件,调用框架代码会依赖配置自行调用,从而做到代码不做变更的情况下类型对扩展开放,下图展示了聚合层收藏服务的不断扩展。
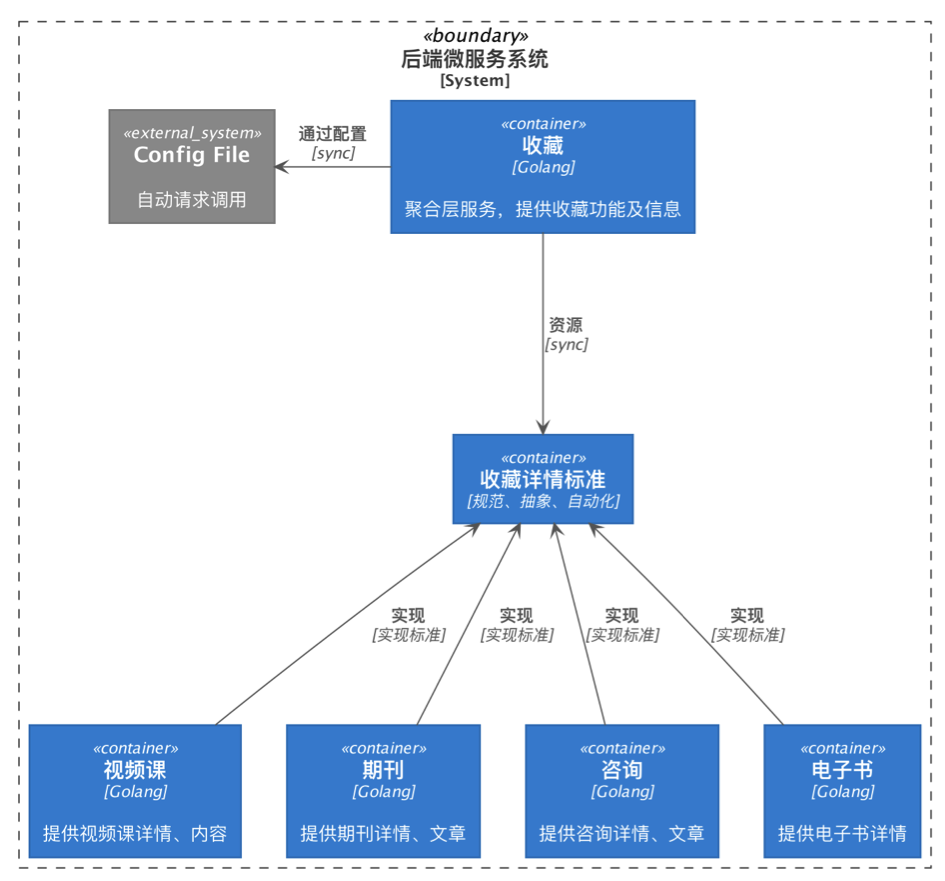
示意代码如下,配置文件使用 .toml,代码采用 Golang
配置文件
[[collection]]
name = "book"
base_url = "http://***.company.com"
server_name = "book_server"
path = "/book/internal/collection-info"
timeout = 200
retry = 2
product_type = 3000
[[collection]]
name = "magazine"
base_url = "http://***.company.com"
server_name = "magazine_server"
path = "/magazine/internal/collection-info"
timeout = 200
retry = 2
product_type = 2000
请求代码
func (cfg *Config) LoadConfigTomlTree(key string) {
treeList := conf.Get(key).([]*toml.Tree)
for _, tree := range treeList {
conf := Config{}
err = tree.Unmarshal(&conf)
confList = append(confList, conf)
}
// 解析配置元数据,输出对应的 Client
confList ==> clientMap
return clientMap
}
func (col *CollectionInfo) MultiLoadCollectionInfo(keysMap) {
for type, reqKeys := range keysMap {
// 开启 Go Routinue 多协程请求
go routinue (func() {
client, ok := fir.clientMap[type]
// 对不同类型,找到不同 Client,发送请求
collectionData := client.requestData(reqKeys)
// 收集各种类型的数据
for key, info := range collectionData{
syncMap.Store(key, &info)
}
})
}
// 提取数据返回
syncMap ==> infoMap
return infoMap
}
依赖标准倒置不止适用于微服务之间的交互,也适用于前端至服务端交互,此时客户端是上层,服务端是下层。当客户端要复用组件时,通用的音视频播放页面、通用的下载组件等,都可以提出标准由服务端各个微服务来进行实现,避免了纯粹的资源聚合的服务端聚合层,减少调用层级也降低了整个系统的复杂度。
5 推动变革
依赖标准倒置是依赖倒置具象化,其仍旧有一定的抽象高度,可以作为我们对微服务之间职责的定义和交互划分。微服务群组内,上下层的交互,依赖标准倒置,通常是一种更好的选择,并非所有的开发者会意识到这一改变讲带来巨大的便利性,并节省团队整体的成本。
我们再次回到康威定律,产品必然是其组织沟通结构的缩影。上文提到,各方力量角逐下,Flash Player 不一定有能力去推动标准,因为其他公司并不属于自己组织。同一组织内推动标准也会有阻力的,架构师是应当有能力来识别是否需要依赖标准倒置,并调整相应组织内的权责来推动落地的。依赖标准小节我们提到,两种观点都成立,此处我们已经做出选择,并明确职责划分观点:即聚合层业务不变,底层业务需要融入聚合层,变更属于底层业务的职责,明确职责划分后,便会有来自聚合层业务不愿变更的阻力来自发去驱动这一标准的落地。
系统是不断迭代的过程,对于存量服务的过渡期间下,底层微服务负责同事开放某些包开发权限,由聚合层业务研发同事深入底层服务进行开发,将原来维护在自身项目里的逻辑移至底层服务。对于新增的聚合层服时,则协调底层微服务研发集中开发。对于新增底层业务服务时,由底层业务自行开发。对权责的进一步明确划分,有利于团队更容易接纳对存量服务改造。
同时,产出一个合适的依赖标准导致框架也是有必要的,有示范的代码或框架可循,如果有必要,添加部分自动代码机制,来尽可能的确保约定的自行遵守。这一系列措施,都会减少了落地的规范和阻力,使得依赖标准倒置不依赖外力自行运转。
6 总结
最后,依赖倒置这一类基本架构原则,应当成为团队的技术共识。只有这样,大家对权责划分才会认同,同时也要明白共识达成并非容易,需要多次宣讲讨论,甚至产出标杆项目,让成员广泛的参与其中,团队才能体会到架构模式的优势并真正接受。依赖倒置虽然可操作性强,但也不是万能,其解耦的能力稍偏表层,更深层次的解耦仍依赖对整个自身业务的深入理解。
关于作者:
奇正,曾在奥多比 、百度任高级工程师,现任某互联网公司后端业务线 Leader,先后从事过 C++、Android,Golang 开发工作。
【活动推荐】
微服务落地是一个复杂问题,涉及到 IT 架构、应用架构、组织架构等多个方面,这是一个循序渐进的阶段性过程,而在每一个阶段都会遇到运维、部署、安全等问题,包括组织协作上的问题。
ArchSummit 全球架构师峰会(深圳站)2020 邀请了网易、阿里等一线大厂技术大咖,分享他们各个团队在微服务架构实施过程中的经验和心得。
目前大会门票限时抢购 5 折 起,组团购票还有 极客时间企业版年卡免费送 !时间截止 3 月 31 日!抓紧抢购吧!联系票务经理:15600537884(同微信)
详情可扫描下方二维码或点击【阅读原文】

点个在看少个 bug :point_down:
正文到此结束
- 本文标签: IO bug spring 产品 开发者 App 敏捷 企业 Action ArchSummit 互联网 UI 智能 核心原则 同步 id 系统架构 时间 list 免费 应用架构 部署 https 配置 需求 key 百度 下载 服务端 微服务 struct map 代码 解析 总结 项目管理 Master retry 测试 安全 API Android 开发 http 希望 架构师 PHP 标题 管理 HTML 二维码 src Collection 工程师 java cat 数据 程序员 组织 client
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

