还需要学习JDBC吗?如果需要该了解到怎么样的程度?
前言
只有光头才能变强。
文本已收录至我的GitHub精选文章,欢迎Star: https://github.com/ZhongFuCheng3y/3y
不知道大家在工作中还有没有写过JDBC,我在大三去过一家小公司实习,里边用的就是JDBC,只不过它封装了几个工具类。写代码的时候还是能感受到「 这是真真实实的JDBC代码 」

现在开发一般都是Mybatis,也有公司用的Hibernate或者Spring Data JPA。很多时候,不同的项目由不同的程序员开发,在公司层面可能没有将技术完全统一起来,一个项目用Mybatis,一个项目用Hibernate都是很有可能的。
不管用的是什么 ORM 框架,都是在JDBC上封装了一层嘛,所以JDBC还是需要好好学习的。
什么是ORM?
Object_Relative DateBase-Mapping,在Java对象与关系数据库之间 建立某种映射,以实现直接存取Java对象 。
很多同学不知道JDBC要学到怎么样的一种程度,这里我来讲讲JDBC的知识点有哪些,哪些应该是需要掌握的。
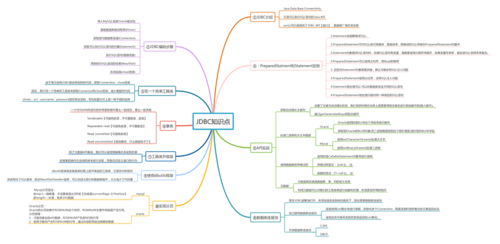
JDBC基础知识
什么是JDBC?JDBC全称为:Java Data Base Connectivity,它是可以执行SQL语句的Java API
每种数据库都有自己的图形界面呀,我都可以在里边操作执行数据库相关的事,为什么我们要用JDBC?
- 数据库里的数据是给谁用的?给程序用的。我们用的是Java程序语言,所以需要用Java程序去链接数据库来访问数据。
- 市面上有非常多的数据库,本来我们是需要根据不同的数据库学习不同的API,sun公司为了简化这个操作,定义了JDBC API【接口】。对于我们来说, 操作数据库都是在JDBC API【接口】上 ,使用不同的数据库,只要用数据库厂商提供的数据库驱动程序即可。
其实可以好好细品一下JDBC,把接口定义出来,反正你给我实现就对了,无论数据库怎么变,用的时候是同一套API

随后我们简单学习一下这几个接口:Connection、Statement、ResultSet。写出 小白必学 的Java连接数据库的代码:
- 导入MySQL或者Oracle驱动包
- 装载数据库驱动程序
- 获取到与数据库连接
- 获取可以执行SQL语句的对象
- 执行SQL语句
- 关闭连接
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
/*
* 加载驱动有两种方式
*
* 1:会导致驱动会注册两次,过度依赖于mysql的api,脱离的mysql的开发包,程序则无法编译
* 2:驱动只会加载一次,不需要依赖具体的驱动,灵活性高
*
* 我们一般都是使用第二种方式
* */
//1.
//DriverManager.registerDriver(new com.mysql.jdbc.Driver());
//2.
Class.forName("com.mysql.jdbc.Driver");
//获取与数据库连接的对象-Connetcion
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/zhongfucheng", "root", "root");
//获取执行sql语句的statement对象
statement = connection.createStatement();
//执行sql语句,拿到结果集
resultSet = statement.executeQuery("SELECT * FROM users");
//遍历结果集,得到数据
while (resultSet.next()) {
System.out.println(resultSet.getString(1));
System.out.println(resultSet.getString(2));
}
} catch (SQLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
/*
* 关闭资源,后调用的先关闭
*
* 关闭之前,要判断对象是否存在
* */
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}

基本流程完了以后,我们要重点学习一下 PreparedStatement 接口与Statement接口的区别,为什么要用PreparedStatement。
- Statement对象编译SQL语句时,如果SQL语句有变量,就需要使用分隔符来隔开,如果变量非常多,就会使SQL变得非常复杂。 PreparedStatement可以使用占位符,简化sql的编写
- Statement会频繁编译SQL。 PreparedStatement可对SQL进行预编译,提高效率,预编译的SQL存储在PreparedStatement对象中
- PreparedStatement防止SQL注入 。(Statement通过分隔符
'++',编写永等式,可以不需要密码就进入数据库)
数据库连接池
为什么我们要使用数据库连接池?数据库的连接的建立和关闭是非常消耗资源的,频繁地打开、关闭连接造成系统性能低下
常见的数据库连接池有C3P0、DBCP、 Druid 。大家在学习的时候可以用 Druid ,我曾经用C3P0写了个Demo被diss了(:
Druid是阿里开源的一个项目,有中文文档,跟着学着连接数据库,我相信不会太难。GitHub搜「 Druid 」就能搜到了

分页
说到分页,面试和工作都是非常常见的了,是必须要掌握的技术。下面来简单说一下Oracle和MySQL是如何实现分页的,以及对应的解释:
Oracle分页:
/*
Oracle分页语法:
@lineSize---每页显示数据行数
@currentPage----当前所在页
*/
SELECT *FROM (
SELECT 列名,列名,ROWNUM rn
FROM 表名
WHERE ROWNUM<=(currentPage*lineSize)) temp
WHERE temp.rn>(currentPage-1)*lineSize;
/*
Oracle分页:
Oracle的分页依赖于ROWNUM这个伪列,ROWNUM主要作用就是产生行号。
分页原理:
1:子查询查出前n行数据,ROWNUM产生前N行的行号
2:使用子查询产生ROWNUM的行号,通过外部的筛选出想要的数据
例子:
我现在规定每页显示5行数据【lineSize=5】,我要查询第2页的数据【currentPage=2】
注:【对照着语法来看】
实现:
1:子查询查出前10条数据【ROWNUM<=10】
2:外部筛选出后面5条数据【ROWNUM>5】
3:这样我们就取到了后面5条的数据
*/
MySQL分页:
/*
Mysql分页语法:
@start---偏移量,不设置就是从0开始【也就是(currentPage-1)*lineSize】
@length---长度,取多少行数据
*/
SELECT *
FROM 表名
LIMIT [START], length;
/*
例子:
我现在规定每页显示5行数据,我要查询第2页的数据
分析:
1:第2页的数据其实就是从第6条数据开始,取5条
实现:
1:start为5【偏移量从0开始】
2:length为5
*/
总结:
- Mysql从
(currentPage-1)*lineSize开始取数据,取lineSize条数据 - Oracle先获取
currentPage*lineSize条数据,从(currentPage-1)*lineSize开始取数据

DBUtils
DBUtils我觉得还算是一个挺好用组件,在学习Hibernate,Mybatis这些ORM框架之前,可以学着用用。可以极大简化我们的JDBC的代码,用起来也很方便。
如果急忙着写毕业设计,还没时间来得及学ORM框架,用这个工具来写 DAO 数据访问层,我觉得是一个不错的选择。
可以简单看看代码:
/*
* 使用DbUtils框架对数据库的CRUD
* 批处理
*
* */
public class Test {
@org.junit.Test
public void add() throws SQLException {
//创建出QueryRunner对象
QueryRunner queryRunner = new QueryRunner(JdbcUtils.getDataSource());
String sql = "INSERT INTO student (id,name) VALUES(?,?)";
//我们发现query()方法有的需要传入Connection对象,有的不需要传入
//区别:你传入Connection对象是需要你来销毁该Connection,你不传入,由程序帮你把Connection放回到连接池中
queryRunner.update(sql, new Object[]{"100", "zhongfucheng"});
}
@org.junit.Test
public void query()throws SQLException {
QueryRunner queryRunner = new QueryRunner(JdbcUtils.getDataSource());
String sql = "SELECT * FROM student";
List list = (List) queryRunner.query(sql, new BeanListHandler(Student.class));
System.out.println(list.size());
}
@org.junit.Test
public void delete() throws SQLException {
QueryRunner queryRunner = new QueryRunner(JdbcUtils.getDataSource());
String sql = "DELETE FROM student WHERE id='100'";
queryRunner.update(sql);
}
@org.junit.Test
public void update() throws SQLException {
QueryRunner queryRunner = new QueryRunner(JdbcUtils.getDataSource());
String sql = "UPDATE student SET name=? WHERE id=?";
queryRunner.update(sql, new Object[]{"zhongfuchengaaa", 1});
}
@org.junit.Test
public void batch() throws SQLException {
//创建出QueryRunner对象
QueryRunner queryRunner = new QueryRunner(JdbcUtils.getDataSource());
String sql = "INSERT INTO student (name,id) VALUES(?,?)";
Object[][] objects = new Object[10][];
for (int i = 0; i < 10; i++) {
objects[i] = new Object[]{"aaa", i + 300};
}
queryRunner.batch(sql, objects);
}
}
放干货
现在已经工作有一段时间了,为什么还来写 JDBC 呢,原因有以下几个:
- 我是一个对 排版 有追求的人,如果早期关注我的同学可能会发现,我的GitHub、文章导航的
read.me会经常更换。现在的 GitHub 导航也不合我心意了(太长了),并且早期的文章,说实话排版也不太行,我决定重新搞一波。 - 我的文章会分发好几个平台,但文章发完了可能就没人看了,并且图床很可能因为平台的防盗链就挂掉了。又因为有很多的读者问我:” 你能不能把你的文章转成PDF啊 ?“
- 我写过很多系列级的文章,这些文章就几乎不会有太大的改动了,就非常适合把它们给” 持久化 “。
基于上面的原因,我决定把我的系列文章汇总成一个 PDF/HTML/WORD 文档。说实话,打造这么一个文档 花了我不少的时间 。为了防止 白嫖 ,关注我的公众号回复「 888 」即可获取。

文档的内容 均为手打 ,有任何的不懂都可以直接 来问我 (公众号有我的联系方式)。
涵盖Java后端所有知识点的开源项目(已有6 K star): https://github.com/ZhongFuCheng3y/3y
如果大家想要 实时 关注我更新的文章以及分享的干货的话,微信搜索 Java3y 。
PDF文档的内容 均为手打 ,有任何的不懂都可以直接 来问我 (公众号有我的联系方式)。


正文到此结束
- 本文标签: 遍历 总结 Word id 小公司 java tar 开源项目 final http MQ JDBC API spring 数据 HTML 开发 src IO druid mysql https UI 程序员 分页 Connection ORM junit git map App mybatis dataSource bean ResultSet db sql 时间 list C3P0 JPA Statement 编译 cat 代码 value DBCP 文章 JDBC root 数据库 GitHub Select 开源 ACE 连接池 update Oracle API
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

