站在JVM角度看Java的锁
对于最开始 (JDK1.5之前), Java的同步只能是一个synchronized修饰, 进行同步, 但是这个由很大的问题. 只会有一个线程可以entermonitor , 然后计数器+1. 称为重量级锁. 其他线程都被挂起, 我们知道对于大多数JVM来说, 线程是和操作系统的线程是一一绑定的, 也就是我操作的线程挂起需要由内核来完成, 这时候就需要用户态转换到内核态 ,然后内核执行此线程挂起, 当要恢复线程的时候再通知内核, 此时会造成很严重的问题 . 我们知道对于CPU来说, 他是靠时间片来实现的多线程并行执行, 如果我一个同步任务只会比如count++ , 他执行很短, 短到几ns级别, 而挂起线程和恢复线程的实现 远远大于几ns , 可能大几个量级 .
因此聪明的人想到一个事情, 就是我不让你挂起, 这么短我就自己空转一会, 也很短, (空转的意思其实就是while(true) 啥也不做,但是不是让CPU挂起, 这个也称之为自旋 ) , 我们知道空转就是一种浪费CPU的事情 , 但是这个浪费得有个度 , 我们上诉的问题, 每个线程可能空转的时间也就几ns , 但是对于长到几秒的还能空转吗, 不行了. 所以这里就是一个划分点.
还有一个问题就是, 比如某一段时间内, 就一个线程处于运作中, 那么此时还需要加锁操作吗 ? 是否需要优化 .
因此引出了下文的解决方案.
自旋锁
自旋锁是JDK1.4.2的时候引入的, 默认为关闭状态, 可以使用 -XX:+UseSpinning 参数来开启 , 但是这个自旋锁他不是一直的自旋, 他有个度, 这个度可以用 -XX:PreBlockSpin 来控制自旋多少次, 默认是10次.
自适应自旋
JDK 6中对自旋锁的优化,引入了自适应的自旋。
**自适应意味着自旋的时间不再是固定的了,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定的。**如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也很有可能再次成功,进而允许自旋等待持续相对更长的时间,比如持续100次忙循环。另一方面,如果对于某个锁,自旋很少成功获得过锁,那在以后要获取这个锁时将有可能直接省略掉自旋过程,以避免浪费处理器资源。有了自适应自旋,随着程序运行时间的增长及性能监控信息的不断完善,虚拟机对程序锁的状况预测就会越来越精准,虚拟机就会变得越来越“聪明”了。
Java 对象的内存布局(重要)
了解轻量级锁和偏向锁 需要了解Java对象的内存布局.
再看下面之前 , 要了了解一个JAVA对象的内存结构 , 也称之为 对象的内存布局
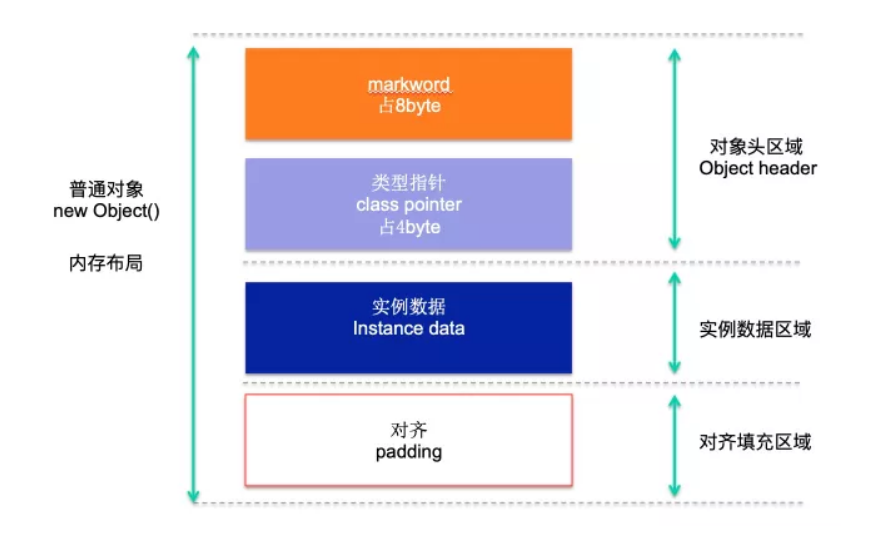
对象头 :
1、对象自身的运行时数据( MarkWord )
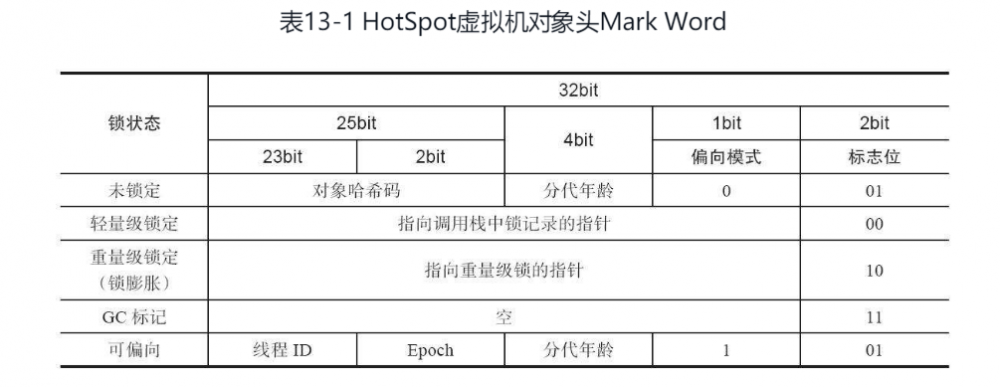
存储 hashCode、GC 分代年龄、锁类型标记、偏向锁线程 ID 、CAS 锁指向线程 LockRecord 的指针等,synconized 锁的机制与这个部分( markwork )密切相关,用 markword 中最低的三位代表锁的状态,其中一位是偏向锁位,另外两位是普通锁位。
关于markword , 这个是32位操作系统的实现,
2、对象类型指针( Class Pointer )
对象指向它的类元数据的指针(这个指针类似于C语言的指针, 指针大小是根据操作系统决定的,64位好像是8个字节大小, 因为64位系统的寻址空间很大), JVM 就是通过它来确定是哪个 Class 的实例。
如果是数组对象,还会有一个额外的部分用于存储数组长度。因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是如果数组的长度是不确定的,将无法通过元数据中的信息推断出数组的大小。也就是arr.len调用很方便.
实例数据区域
此处存储的是对象真正有效的信息,比如对象中所有字段的内容 . ,无论是从父类继承下来的,还是在子类中定义的字段都必须记录起来。
这部分的存储顺序会受到虚拟机分配策略参数(-XX:FieldsAllocationStyle参数)和字段在Java源码中定义顺序的影响。HotSpot虚拟机默认的分配顺序为 longs/doubles、ints、shorts/chars、bytes/booleans、oops(Ordinary Object Pointers,OOPs) (这里基本可以确定Java的类型也就8种),从以上默认的分配策略中可以看到,相同宽度的字段总是被分配到一起存放,在满足这个前提条件的情况下,在父类中定义的变量会出现在子类之前。如果HotSpot虚拟机的+XX:CompactFields参数值为true(默认就为true),那子类之中较窄的变量也允许插入父类变量的空隙之中,以节省出一点点空间。
对齐填充
对象的第三部分是对齐填充,这并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。由于HotSpot虚拟机的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说就是任何对象的大小都必须是8字节的整数倍。对象头部分已经被精心设计成正好是8字节的倍数(1倍或者2倍),因此,如果对象实例数据部分没有对齐的话,就需要通过对齐填充来补全。
其实也是为了存储方便.
如果你还是对上述不理解的话, 你就看看 <深入理解Java虚拟机> , 里面有. 接下来就看看具体内容了 .
synchronized 锁升级流程
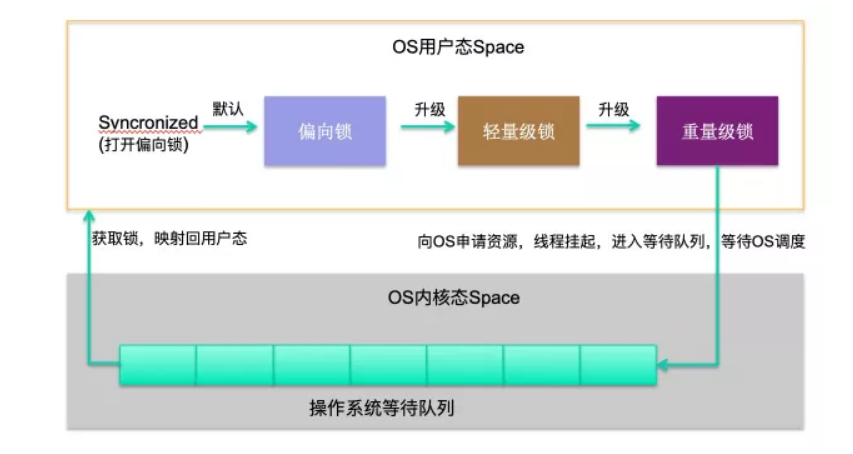
synchronized 锁并不是直接进去就是一个重量级锁, 而是有所思考的, 因为很多短的操作,并不需要挂起线程. 所以类似于空转 , 还有就是单线程加锁. 何必挂起线程呢, 所以sync也帮助我们解决了这个问题.
偏向锁
在 JDK1.8 中,其实默认是轻量级锁,但如果设定了 -XX:BiasedLockingStartupDelay=0 ,那在对一个 Object 做 syncronized 的时候,会立即上一把偏向锁。当处于偏向锁状态时, markwork 会记录当前线程 ID。
它的意思是这个锁会偏向于第一个获得它的线程,如果在接下来的执行过程中,该锁一直没有被其他的线程获取,则持有偏向锁的线程将永远不需要再进行同步。偏向锁解决的问题是, 有些时候就一个线程在运行, 难道还有多线程问题吗, 所以并不需要. 当出现第二个线程去竞争的情况下才会出现降级 .
原理: 当锁对象第一次被线程获取的时候,虚拟机将会把对象头中的标志位设置为“01”、把偏向模式设置为“1”,表示进入偏向模式。同时使用CAS操作把获取到这个锁的线程的ID记录在对象的Mark Word之中。如果CAS操作成功,持有偏向锁的线程以后每次进入这个锁相关的同步块时,虚拟机都可以不再进行任何同步操作(例如加锁、解锁及对Mark Word的更新操作等)。 一旦出现另外一个线程去尝试获取这个锁的情况,偏向模式就马上宣告结束。
轻量级锁
当下一个线程参与到偏向锁竞争时,会先判断 markword 中保存的线程 ID 是否与这个线程 ID 相等,如果不相等,会立即撤销偏向锁,升级为轻量级锁。 每个线程在自己的线程栈中生成一个 LockRecord ( LR ),然后每个线程通过 CAS (自旋 )的操作将锁对象头中的 markwork 设置为指向自己的 LR 的指针,哪个线程设置成功,就意味着获得锁。 关于 synchronized 中此时执行的 CAS 操作是通过 native 的调用 HotSpot 中 bytecodeInterpreter.cpp 文件 C++ 代码实现的,有兴趣的可以继续深挖。
重量级锁
如果锁竞争加剧(如线程自旋次数或者自旋的线程数超过某阈值, JDK1.6 之后,由 JVM 自己控制该规则),就会升级为重量级锁。此时就会向操作系统申请资源,线程挂起,进入到操作系统内核态的等待队列中,等待操作系统调度,然后映射回用户态。在重量级锁中,由于需要做内核态到用户态的转换,而这个过程中需要消耗较多时间,也就是"重"的原因之一。
可重入
synchronized 拥有强制原子性的内部锁机制,是一把可重入锁。因此,在一个线程使用 synchronized 方法时调用该对象另一个 synchronized 方法,即一个线程得到一个对象锁后再次请求该对象锁,是永远可以拿到锁的。在 Java 中线程获得对象锁的操作是以线程为单位的,而不是以调用为单位的。 synchronized 锁的对象头的 markwork 中会记录该锁的线程持有者和计数器,当一个线程请求成功后, JVM 会记下持有锁的线程,并将计数器计为1 。此时其他线程请求该锁,则必须等待。而该持有锁的线程如果再次请求这个锁,就可以再次拿到这个锁,同时计数器会递增。当线程退出一个 synchronized 方法/块时,计数器会递减,如果计数器为 0 则释放该锁锁。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

